SquirrelFish: optimalizace vykonávání instrukcí a nativní kód

Dnes se budeme věnovat tomu, jak urychlit vykonávání instrukcí bajtkódu JavaScriptu ve virtuálním stroji SquirrelFish. Představíme si přitom techniku direct threading, která zrychluje dispatching instrukcí, a další optimalizace. Na závěr článku se podíváme, jak je na tom SquirrelFish s generováním nativního kódu.
Seriál: Do hlubin implementací JavaScriptu (14 dílů)
- Do hlubin implementací JavaScriptu: 1. díl – úvod 30. 10. 2008
- Do hlubin implementací JavaScriptu: 2. díl – dynamičnost a výkon 6. 11. 2008
- Do hlubin implementací JavaScriptu: 3. díl – výkonnostně nepříjemné konstrukce 13. 11. 2008
- Do hlubin implementací JavaScriptu: 4. díl – implementace v prohlížečích 20. 11. 2008
- Do hlubin implementací JavaScriptu: 5. díl – implementace mimo prohlížeče 27. 11. 2008
- SquirrelFish: reprezentace hodnot JavaScriptu a virtuální stroj 4. 12. 2008
- SquirrelFish: optimalizace vykonávání instrukcí a nativní kód 11. 12. 2008
- SquirrelFish: regulární výrazy, vlastnosti objektů a budoucnost 18. 12. 2008
- SpiderMonkey: zpracování JavaScriptu ve Firefoxu 8. 1. 2009
- SpiderMonkey: rychlá kompilace JavaScriptu do nativního kódu 15. 1. 2009
- V8: JavaScript uvnitř Google Chrome 22. 1. 2009
- Rhino: na rozhraní JavaScriptu a Javy 29. 1. 2009
- Velký test rychlosti JavaScriptu v prohlížečích 5. 2. 2009
- Javascriptové novinky: souboj o nejrychlejší engine pokračuje 19. 3. 2009
V minulém dílu jsme si říkali, že jedním z problémů interpretů je pomalý dispatching instrukcí – tj. nalezení kódu, který vykonává právě zpracovávanou instrukci bajtkódu. Pojďme se nyní podívat, jak přesně dispatching probíhá, proč je to pomalá operace a jak ho lze urychlit.
Smyčka interpretu a dispatching
Každý interpret má v sobě „nekonečnou“ smyčku, ve které vykonává instrukce bajtkódu. V každém jejím kroku musí provést několik operací:
- načíst opkód instrukce z paměti (fetch)
- nalézt kód, který instrukci vykonává (dispatch)
- vykonat instrukci (execute), včetně načtení jejích operandů a uložení výsledků
- přejít na další instrukci
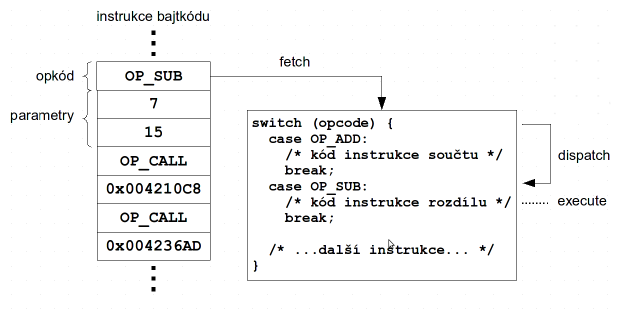
Fáze zpracování instrukcí bajtkódu interpretem.
Instrukce jsou obvykle uloženy v souvislém bloku v paměti, načtení opkódu tedy není složité – pokud je opkód instrukce stejně dlouhý jako slovo na dané platformě (což u SquirrelFish je), pak na něj stačí obvykle jen jedna instrukce.
Problémem ovšem je nalezení kódu implementujícího instrukci. Interpret má v sobě obvykle jeden velký příkaz switch, který se větví podle opkódu a v tělech jednotlivých větví obsahuje kód vykonávající instrukce.
Příkaz switch se (v ideálním případě) zkompiluje do tabulky, kde na místech indexovaných opkódy budou adresy kódu v jednotlivých větvích příkazu switch. To znamená, že při vykonávání bajtkódu se bude muset u každé instrukce provést vyhledání v tabulce (což zabere několik instrukcí) a poté nepřímý skok závislý na opkódu instrukce.
Nepřímé skoky v podobě používané interprety jsou na dnešních procesorových architekturách prakticky nepredikovatelné – procesor u takového skoku musí ve většině případů zastavit své předzpracovávání následujících instrukcí, protože neví, kde se bude ve vykonávání kódu pokračovat. To spolu s vyhledáváním v tabulce způsobuje relativní pomalost interpretu.
Zpomalení zde může být opravdu značné. Například podle měření provedeného na několika interpretech tvoří nepřímé skoky přibližně 3–13 % z instrukcí reálného stroje při běhu interpretu a především zaberou víc než polovinu času běhu interpretu. Vyplatí se tedy dispatching zoptimalizovat, na což se podíváme za chvilku.
Další části vykonávání instrukce již pro nás nejsou zajímavé. Průběh vykonání je pro každou z nich jiný a těžko lze zde uplatnit nějakou obecnou optimalizaci. Posun k další instrukci je ve většině případů jen inkrementace ukazatele na aktuální instrukci, případně jeho přepsání novou hodnotou (u instrukcí způsobujících skok, jako je třeba volání metody či vyvolání výjimky).
Urychlení dispatchingu
Technika, která se v interpretech (včetně SquirrelFish) používá pro urychlení dispatchingu instrukcí, se nazývá direct threading a nemá nic společného s vlákny, jak by se snad z názvu mohlo zdát. Její myšlenka je jednoduchá: nahradit opkódy instrukcí přímo ukazateli na kód, který vykonává danou instrukci. Zbavíme se tak celého příkazu switch a prohledávání tabulky. Skok na kód sice stále zůstane nepřímý, ale je obvykle o něco lépe predikovatelný, a tedy i rychlejší. Celkové dosažené zrychlení může být až dvojnásobné (samozřejmě velmi závisí na architektuře procesoru, použitém kompilátoru a dalších faktorech).
Technika není implementačně vůbec náročná – stačí předem projít vygenerovaný kód a opkódy instrukcí nahradit příslušnými adresami. Opkódy virtuálního stroje SquirrelFish jsou na to dokonce přímo stavěné (mají stejnou velikost jako ukazatel, který přijde na jejich místo).
Menším problémem je, že musíme znát adresu kódu, který vykonává jednotlivé instrukce. To znamená, že potřebujeme určit adresu návěští v jazyce C a pracovat s ní (odborně řečeno, návěští musí být first-class value). V ANSI C to není možné, ale některé překladače to dovedou. Mezi ně patří například gcc, nikoliv už ale Microsoft Visual C++.
Pro SquirrelFish, který je potřeba kompilovat oběma zmíněnými překladači, to znamená, že musí podporovat obě metody dispatchingu (příkaz switch i direct threading). Použitá metoda se vybere pomocí podmíněné kompilace při sestavení interpretu.
Další optimalizace
SquirrelFish se kromě optimalizace dispatchingu instrukcí snaží urychlit i jejich samotné vykonávání. Mnoho instrukcí se například díky dynamickému typování rozpadá na několik různých případů podle typů operandů, např. operátor „+“ může představovat buď numerický součet, nebo spojení textových řetězců. V takových případech se SquirrelFish snaží nejdříve testovat a řešit nejběžnější případy, a až poté zkoumá varianty okrajové. Správné seřazení podmínek znamená, že se stráví méně času zkoumáním slepých větví.
U zmiňovaného operátoru „+“ je například podle vývojářů SquirrelFish nejčastější případ, kdy jsou oba operandy čísla, případně řetězce, a relativně častá je ještě varianta, kdy je nalevo řetězec a napravo číslo. Všechny ostatní kombinace operandů se vyskytují vzácně.
Vývojáři také zkoumali frekvence vykonávání jednotlivých instrukcí a jejich kombinací. Pro často se opakující vzory po sobě jdoucích jednoduchých instrukcí vytvořili nové tzv. combo instrukce. Ty mají stejnou funkcionalitu jako série instrukcí jednoduchých, ale ušetří se u nich na dispatchingu.
Kompilace do nativního kódu
Jak již bylo řečeno v předchozích dílech, SquirrelFish podporuje just-in-time (JIT) kompilaci do nativního kódu. Spojení just-in-time znamená, že kompilace neprobíhá předem jako u klasických kompilátorů, ale program se kompiluje po částech za jeho běhu.
V současné době je kompilace podporována pouze na platformě x86. Přidání dalších architektur je v principu možné, ale dle vývojářů i mého pohledu do zdrojového kódu interpretu to bude vyžadovat poměrně velkou refaktorizaci celého kompilátoru.
Kdy a co se kompiluje?
Nativní kód je generován z bajtkódu, přičemž jsou vždy kompilovány najednou celé funkce. Kompilace je líná, tzn. funkce se kompiluje až ve chvíli, kdy má být spuštěna – do té doby je její kód reprezentován bajtkódem. Šetří se tak čas, který by se strávil kompilací nikdy nevolaných funkcí.
Při zkoumání kompilátoru mě velmi překvapilo, že spouštěné funkce jsou kompilovány vždy. Ve většině JIT kompilátorů se totiž měří, jak často jsou jednotlivé části kódu (typicky právě funkce či metody) spouštěny a kompilují se jen ty, u nichž kompilátor usoudí, že se to vyplatí. Kompilace je relativně časově náročný proces a kompilovat funkci, která je spuštěna jen několikrát za celou dobu běhu programu, by bylo neekonomické.
Důvody, proč SquirrelFish kompiluje všechny funkce, můžou být v zásadě dva: selektivní kompilace buď ještě není implementována, nebo je rozdíl rychlostí spuštění bajtkódu a nativního kódu tak velký a kompilace tak rychlá, že se opravdu vyplatí funkce kompilovat téměř ve všech případech.
Průběh kompilace
Jak přesně kompilace bajtkódu probíhá? SquirrelFish prochází bajtkód instrukci po instrukci a povede jednu ze dvou věcí:
- U složitějších instrukcí vygeneruje do nativního kódu volání funkce, která implementuje funkcionalitu instrukce.
- U jednodušších instrukcí se použije inlining, tzn. kód implementující instrukci je přímo vložen na její místo.
Posloupnost výsledných instrukcí nativního kódu je po vygenerování případně dále zoptimalizována.
Při rozhodování, zda použít inlining, musí být kompilátor opatrný. Tato technika totiž zvětšuje velikost kódu a díky omezené velikosti keší procesoru je obecně vykonávání většího kódu pomalejší. To může v konečném důsledku vyrušit čas uspořený absencí volání funkce.
Technika, kdy se volají funkce implementující původní instrukce bajtkódu, se nazývá context threading. Na první pohled se může zdát pomalá – jak se učí snad v každém kurzu assembleru, volání funkce je relativně drahá záležitost. V dnešních procesorech jsou ale volání a návraty z funkcí poměrně hodně zoptimalizovány a především jsou velmi dobře predikovatelné. Jsou tedy většinou rychlejší než nepřímé skoky používané u direct threadingu. V článku, který techniku context threadingu poprvé popsal, uvádí autoři zrychlení v řádu desítek procent.
Další informace
Pro podrobnější informace o kompilaci do nativního kódu doporučuji nahlédnout přímo do zdrojového kódu SquirrelFish – konkrétně především do souborů JavaScriptCore/jit/JIT.cpp, JavaScriptCore/interpreter/Interpreter.cpp a do souborů v adresáři JavaScriptCore/assembler.
Dobrým způsobem, jak najít všechny části související s kompilací, je vyhledat všechny výskyty řetězce #if ENABLE(JIT).
Co nás čeká příště
V příští části seriálu povídání o interpretu SquirrelFish dokončíme. Podíváme se na to, jak optimalizuje přístup k vlastnostem objektů, jak urychluje práci s regulárními výrazy a jaké další optimalizace jeho autoři připravují v blízké budoucnosti.
Zdroje
- M. A. Ertl, D. Gregg: The Structure and Performance of Efficient Interpreters – pojednává o návrhu virtuálních strojů obecně a vysvětluje direct threading
- M. Berndl, B. Vitale, M. Zaleski, A. D. Brown: Context Threading: A flexible and efficient dispatch technique for virtual machine interpreters – podorbný popis context threadingu
- Announcing SquirrelFish – oznámení vydání SquirrelFish
- Introducing SquirrelFish Extreme – představení SquirrelFish Extreme
David Majda
Autor je vývojář se zájmem o programovací jazyky, webové aplikace a problémy programování jako takového. Vystudoval informatiku na MFF UK a během studií zde i trochu učil. Aktuálně pracuje v SUSE.



Děkuji za opravdu dobré technické čtení. Užil jsem si to.
Díky za článek, moc zajímavé čtení!
Clanek je docela pekny (jen jsem moc nepochopil ten skok ke context threadingu na konci).
Jen drobna poznamka: "Ve většině JIT kompilátorů se totiž…" Treba .NET (aspon v pripade C#, ale myslim, ze je to az na urovni CILu) JITuje taky vsechny funkce uz pri prvnim volani, takze to neni zas az takova vzacnost.
To moje podivení vychází z toho, co jsem v průběhu let o JIT kompilátorech různě četl/slyšel. Ve většině z těchto popisů převažoval přístup "nejdřív měř a pak teprve kompiluj". Je ale možné, že mám zastaralé/zavádějící informace a kompilace funkce při prvním spuštění není vůbec neobvyklá nebo dokonce převažuje.
Pokud někdo ze čtenářů zná příklady JIT kompilátorů, které to dělají jedním nebo druhým způsobem, napište je prosím do komentářů.
No možná je problém v tom, že zaměňujete JIT kompilaci a HotSpot. To jsou dvě různé věci. To co jste možná až do dneška považoval za JIT kompilaci je HotSpot. To co SquirrelFish provádí je skutečně JIT a může trpět neduhy, které popisujete. Jestli .NET dělá JIT kompilaci netuším, ale slyšel jsem, že se poučili z některých chyb Javy a dělají JIT kompilaci, ale na rozdíl od Javy výsledky ukládají do system wide cache, kdežto Java JIT kompilaci dlouhou dobu prováděla pořád znova při každém spuštění (a hůř i pro základní třídy!) pro každou instanci VM a získala tak onu velmi špatnou pověst s pomalým startem. Pánové v Sunu neměli chuť se pouštět do nějaké formy cache (snad kvůli portovatelnosti a nezávislosti například vůbec na existenci hostujícího OS, čímž si pánové v MS evidentně hlavu nelámali) a tak jim nezbylo než se pustit jinou cestou a HotSpot je výsledek. Kód po překladu do bytecode je nejdříve interpretován a po profilaci jako hot spot je překompilován. To je technologie HotSpot a dá se považovat za jistou podmnožinu JIT kompilace. Java de fakto technologii prosté JIT kompilace opustila. Nicméně je velký rozdíl kompilovat staticky typovanou Javu, nebo C# a dynamicky typovaný jazyk jako je JS. Jestliže u staticky typovaných jazyků má za sebou proces optimalizace výsledného kódu desítky let zkušeností a rozdíl mezi interpretovaným a nativním kódem je propastný, tak v dynamicky typované oblasti se chleba láme právě dnes a právě kolem JS a ta propast teprve musí vzniknout.
mam takovy dojem, ze v tom JIT a hotspot jste se trochu zamotal… ale co…
nemyslim, ze by kompilace ,,dynamickych jazyku'' byla neco az tak noveho. prekladace LISPu vznikaly uz nekdy pred padesati lety, ktery ,,dnesni'' jazyk tomu muze konkurovat?
Hmm, a víš ty anonymní rozumbrado jaký je rozdíl mezi nativně přeloženým Lispem s typovou anotací a bez ní? To je rozdílek, co? Dtto různé Scheme implementace.
.NET JIT kompiluje vzdy pred prvnim vykonanim funkce, zadny interpret neobsahuje. System je ve vysledku jednodussi, snaze udrzovatelny a hlavne (tohle muze byt pro programatory ze sveta OSS hure pochopitelne ;) snaze otestovatelny.
Resenim pomaleho start-upu ve svete .NET je NGEN – predkompilace celych binarek typicky behem instalace programu.