Co prozradila homepage velkých českých serverů?

Před časem jsme v redakci diskutovali s kolegou o tom, co vlastně prozrazují „hlavičky“ v HTTP protokolu. Že v nich putují zajímavé informace o klientu, to je známo i mírně poučeným uživatelům, ale co prozrazují naopak o serveru? Udělali jsme si drobný průzkum velkých českých serverů a zde jsou výsledky.
Vzorek
Kolegovi jsme v redakci ukázali asi šest hlaviček webů (ve Firebugu) a řekli jsme mu, co nám hlavičky prozrazují. Od toho vedl už jen krůček k myšlence podívat se na větší vzorek, reprezentativnější, a nějak získané informace setřídit a zpracovat.
Jako vzorek („velké weby“) jsme nakonec vzali data z měření NetMonitoru. Ano, nejsou to „všechny české velké weby“ a k metodice měření NetMonitoru můžeme mít výhrady, ovšem je to poměrně solidní vzorek „relevantních“ webů. Zdrojem pro měření byla veřejně dostupná statistika z května 2011.
Ze zprávy jsme vzali URL webů, a pro některé další výpočty jsme použili i RU (reální uživatelé) a PV (PageViews). Servery jsou ve zprávě uváděny většinou jako domény 2. úrovně. Při sběru dat jsme před tuto doménu přidávali „www“, pokud server nevrátil data nebo vrátil přesměrování, zkoušeli jsme i variantu bez www.
Sběr dat
Sběr dat proběhl z 483 adres dne 13. 7. 2011 (pro puntičkáře: bylo to mezi 14.46 a 14.51 SELČ). Časový úsek, během něhož musel server odpovědět, byl nastaven na 15 sekund, pokud neodpověděl, zůstal záznam prázdný a ve statistice se dostal do kolonky „nezjištěno“, „nezměřeno“ apod.
Skript ukládal odpověď serveru – jednak hlavičky HTTP protokolu, a kromě nich ještě začátek samotného HTML po element <body>. V hlavičkách jsme si všímali údajů Server, Content-Type a X-Powered-By, ve vlastním dokumentu jsme pak hledali deklaraci DOCTYPE, DTD, charset, zjišťovali jsme, zda servery používají jQuery, Google Analytics, zda nabízejí RSS, zda mají vyplněná metadata keywords a description, zda nabízejí tiskový styl a zda mají styl přímo v HTML, nebo v externím souboru.
Vzorek serverů zahrnoval weby od Seznamu (5.490,000 RU, 2973 mil. PV) až po stránky pokemon-guru.cz (880 RU, 11 227 PV), tedy od největších českých hráčů po miniaturní fanweb. Společným kritériem byla pouze přítomnost v NetMonitoru.
Výsledky
Pojďme se podívat na to, co nám servery o sobě prozradily a co jejich měření řeklo o českém internetu z technického hlediska.
Znaková sada
Začněme od snadno zjistitelného údaje, totiž od znakové sady. Na českých webech jednoznačně dominuje UTF-8 (73% z měřených serverů), za ním následuje Windows-1250 (14%) a na konci je ISO-8859–2 (zastoupení 4%). Zbytek do sta procent připadá, jak jsme si psali výš, na servery, které neodpověděly, nebo které informaci o znakové sadě vůbec neposílají.
Procentuální zastoupení jsme vypočítali, pro zajímavost, i podle RU, tedy „kolik uživatelů webů dostává jaké kódování“. V grafu jsou vyneseny obě hodnoty; je vidět, že se moc neliší.

Server
Zajímavější pohled nabídlo zjišťování použitých HTTP serverů dle hlavičky Server (resp. „posledního serveru před sítí“). Podle očekávání vede Apache, IIS používá z „velké desítky“ jediný server, iDnes. Apache používá 66 procent serverů. IIS pak 10 procent, nginx 8 procent, 14 procent nezjištěno, 0,8 procenta lighttpd.
U serverů jsme opět použili přepočet podle RU a podle PV, a tam se poměry dramaticky změnily. Obrovský objem uživatelů a stránek, generovaný Seznamem, pořadí serverů naprosto obrátil, takže zatímco „největší počet“ serverů běží na Apache, je „největší počet stránek“ (PV) posílán z nginx. Hezky to ilustruje následující graf.
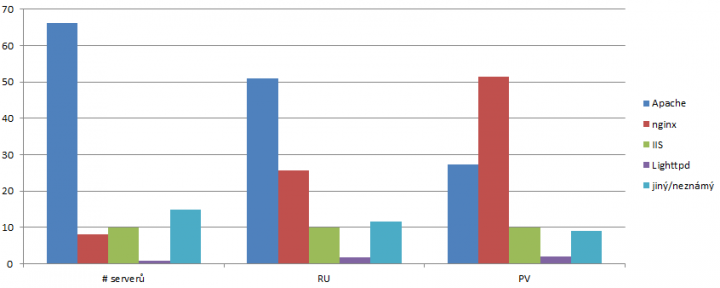
Lze oprávněně tvrdit, že je pravděpodobné, že Apache je u malého serveru „technologie první volby“ – LAMP je univerzálně dostupný a téměř všude. Proto je Apache při přepočtu na počet serverů vítěz. Velké servery, které už mají nemalé počty odbavených uživatelů a stránek, místo náročného Apache používají rychlé alternativy, nejčastěji právě nginx – ovšem právě v kombinaci s obrovským počtem uživatelů a stránek vypadá statistika zcela jinak: Ano, Apache je skoro na všech serverech, ale na těch opravdu významných je právě nginx.
Jako perlička pak je, že IIS má svých 10 % jak podle počtu serverů, tak i podle počtu uživatelů či PV.
Serverový jazyk
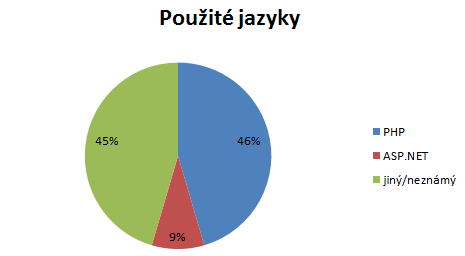
Spíš doplňkem k měření bylo porovnávání serverových technologií. Naprostá většina webů nedává znát interní technologii pomocí přípon (.php, .aspx atd.), takže hrubý odhad jsme dělali pouze z hlavičky X-Powered-By. Téměř polovina serverů (45 procent) tuto hlavičku posílá prázdnou. 46 procent pak přiznává použití PHP, 9 % ASP.NET.
Čistě pro zajímavost: PHP4 uvedly pouhé 3 servery, 148 se hlásí k PHP5.2 a 33 k PHP5.3. 22 serverů pak v hlavičce Powered-By poslalo jako odpověď „Nette Framework“.
Značkovací jazyk
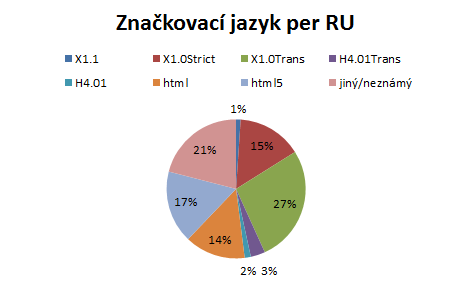
Z doctype a DTD jsme zjišťovali verzi použitého značkovacího jazyka. Zde potvrdilo svou dominantní pozici XHTML, a to verze 1.0 – rovná čtvrtina připadá na XHTML 1.0 Strict, 38 procent pak na XHTML 1.0 Transitional. XHTML1.1 používají pouhá dvě procenta serverů. Zbytek připadá na různé verze HTML4, jednotky procent patří HTML5 a u pětiny serverů se nepodařilo jazyk detekovat.
Neměřili jsme validitu ani jiné faktory, vycházeli jsme pouze z údajů, co servery tvrdily v doctype a v DTD.

I tento graf jsme si přepočítali podle RU, odchylky nebyly příliš velké:
Další údaje
Z hlaviček titulních stránek jsme získali i další údaje, které jsou shrnuty v následujícím grafu:
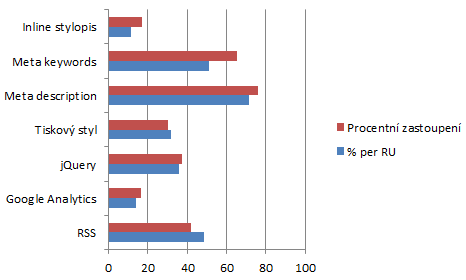
Měřili jsme počet webů, které mají stylopis přímo v HTML, pak počet webů s vyplněnými meta tagy keywords a description, existenci tiskového stylu, zastoupení jQuery, Google Analytics a nakonec i to, zda web nabízí RSS kanál (pomocí tagu link application/rss+xml).
Inline stylopis je záležitost téměř pětiny webů (17 %). Osvětová práce lidových SEOlogů zdůraznila potřebu vyplnit tagy description a keywords – můžeme se o efektivitě těchto věcí přít, ale na druhou stranu, když už se to tam designéři naučili psát (keywords: 66 %, description: 75 %), je to určitě lepší, než kdyby tam nepsali nic, nebo svou kreativitu vybíjeli vymýšlením vlastních novinek.
Tiskový styl nabízí 30 procent webů. Je to hodně, nebo málo? Vzhledem k tomu, že tiskový styl může hodně pomoci zabudované funkci prohlížeče (nezapomeňte, to, jestli si vaši stránku někdo vytiskne, nezáleží na vás!) Navíc odladění takového stylu není většinou velký problém – tedy s dobře napsaným markupem. Určitě by to mohlo a mělo být víc.
Na jQuery jsme byli zvědavi, a po pravdě řečeno je výsledek slušný. Knihovna, která existuje vlastně jen pár let, má téměř 40% penetraci (zde mohlo dojít ke statistické chybě, kdyby si některý web přejmenoval „jquery-blabla.js“ na nějaký indiferentní název, to už by bylo pro nás bez analýzy dalších souborů nezjistitelné). Což je pěkné.
Čistě pro zajímavost jsme se podívali na přítomnost měřicích kódů Google Analytics. Vypadají téměř nepoužívané: 16% zastoupení. Ale toto měření je nutné brát opravdu cum grano salis – zachytili jsme pouze ty, kteří si jej dali do hlavičky souboru.
Poslední test, měření počtu serverů s RSS, ukázalo, že jej 42 procent nabízí. Při přepočtu podle RU vychází, že téměř polovina (48 procent) uživatelů má k dispozici odběr RSS serverů. Kolik z nich to opravdu využívá, to je jiná otázka.
Závěr
Statistika vznikla jako oddychové téma, jako odpověď na otázku: „Co vlastně můžeme o serveru z jeho metadat zjistit?“ Nepoužili jsme žádné invazivnější metody zkoumání, data jsme prostě sebrali a vyhodnotili. Přesto nám to poskytlo zajímavý (minimálně pro technika) pohled na české servery. Nelze z ní usuzovat nic víc než to, co říká – jsou to jen informace poskytnuté serverem. Proto se ve statistikách neobjevil např. Python nebo Ruby (servery tyto informace neposlaly). Nezkoumali jsme ani poddomény nebo další stránky. Šlo nám jen o to, co prozradí hlavičky na homepage.
Možná by nebylo od věci zopakovat takový test za čas a podívat se, zda a jak se český web v tomto směru vyvíjí.
Martin Malý
Začal programovat v roce 1984 s programovatelnou kalkulačkou. Pokračoval k BASICu, assembleru Z80, Forthu, Pascalu, Céčku, dalším assemblerům, před časem v PHP a teď by rád neprogramoval a radši se věnoval starým počítačům.



je mozna velky a relativne narocny, ale i tak se da pouzit bez problemu na projektech co jsou v netmonitoru v top10. Ostatne minimalne o jednom takovem projektu vim ;-)
Je take relativne caste, ze se nechava apache se vsemi svymi vyhodami na vydavani dynamickeho obsahu a staticka cast se odbavuje z nejake subdomeny kde bezi prave neco odlehceneho typu lighttpd nebo nginx. Coz se ve statistikach pochopitelne neobjevi …
Dalsi docela caste schema je, kdy pred apachem vydavajicim dynamicky obsah je nginx jako reverzni proxy. Jedna se o relativne casty zpusob optimalizace serveru.
Takze vysledkem je, ze mate presna cisla, ktera s realitou nemaji nic spolecneho. Proste je okurkova sezona … co se da delat.
Souhlas. Vypovídající hodnota o realitě je poměrně malá, z výše uvedených důvodů.
ani ne, apache má dlouhou odezvu a mamutí spotřebu ram – navíc oproti nginx nenabízí o mnoho navíc.
tudíž jeho použití za nginx má opodstatnění pouze kvuli .htaccess (což dost pochybuju že autory větších portálů trápí, jelikož přepsání těch pár řádek není zas takový problém).
každý kdo má větší traffic později šáhne po nginx nebo varnish cache.
to bych spíš věřil že někde běží tomcat.
Určitě! Tomcat někde musí běžet, ale nehlásí se :) Stejně tak různé servery pro Python / Ruby. Našel jsem v datech jediný případ „přiznaného Ruby“ (v Powered-By), zbytek o platformě cudně mlčel a spadl do „nezjištěno“.
Perlička: Jeden server z měřených posílá hlavičku „X-Powered-By: Chuck Norris“
Treba vetsina serveru Seznamu bezi na pythonu … to je obecne znama vec a hadam ze v tom seznamu z netmonitoru jich par bude ;-)
Je to obecně známá věc, o tom žádná, ale v měření šlo jen o to, „co lze zjistit z hlaviček“. Není to hloubková analýza českého webu, je to vzorek X webů a data vyčtená z jejich hlaviček… Když se tam Python neprojevuje, tak se v měření neobjeví.
Dobrý den,
jaké Accept-* hlavičky jste používali? Dost to totiž mohlo ovlivnit výsledky měření u znakové sady. Server generuje své hlavičky až na základě toho, co pošle prohlížeč, a ten typicky v těch hlavičkách pošle něco jako (FF4 v mém případě):
Accept-Language cs,en-us;q=0.7,en;q=0.3
Accept-Encoding gzip, deflate
Accept-Charset utf-8;q=0.8,*;q=0.7
Čili v tomto příkladu je preferováno UTF-8, pak cokoliv a server se tomu může přizpůsobit.
Z těch nasbíraných dat by také šlo odvodit, kolik serverů provádí kompresi obsahu – hlavička Content-Encoding (tedy pokud v požadavcích bylo Accept-Encoding).
Popřípadě se dal udělat test na automatické jazykové verze a jejich servírování podle Accept-Language.
Používali jsme hlavičku dotazu, která odpovídá „českému FF4“ – tedy stejné Accept-*, UA atd. Content-Encoding jsme netestovali, to je dobrý tip, stejně jako jazykové verze. Skripty a seznam webů jsou připravené, takže není problém přidat další testy.
Nebol to náhodou server auto.cz?
http://www.statistiky-domen.sk/domains/16167-autocz-sk
Tomcat frci treba na pravednes.cz
Doplnění schémat je pěkné, děkuji za ně. Statickou část webů jsme nezjišťovali, protože jsme zkrátka četli homepage. Na statické soubory a CDN se podíváme třeba příště.
U serverů jsem dostatečně nezdůraznil, že jsme zjišťovali, co posílá server jako odpověď v hlavičce Server. Napsal jsem to tam jen cca třikrát, takže to snadno někdo přehlédne… :) No a zbytek čísel – kódování, značkovací jazyk, RSS, … – domníváte se, že z nějakých podobných důvodů jsou tyto údaje mimo realitu? Jako že třeba server interně jede v KOI-8 a HTML, ale předsazený nginx to schválně převádí do ISO-8859-2 a XHTML, aby zmátl naslouchajícího nepří… ehm, uživatele? ;)
Rozumím tomu správně, že jste vždy vzali pouze home page a přepočty na RU/PV pak vychází jen z hypotézy, že všechny další stránky budou vracet totéž?
Marku, přesně tak. Přepočet na RU/PV je tu spíš hříčka, protože ze statistik NetMonitoru nevyčtu jednotlivé poddomény, navíc, jak známo, některé servery nasazují stejný měřicí kód na víc „serverů v rodině“. Je mi jasné, že jiná část webu může dělat třeba 50% návštěvnosti a běžet na jiné technologii. Ale jak říkám – šlo spíš jen o to ukázat, co řeknou hlavičky, udělat z toho nějaký „výcuc“, a přepočet s PV/RU se nabízel jako zajímavost, „jiný úhel pohledu“, i když je to zatíženo takovouto chybou.
Jo jo, i tak je to zajímavé. Díky za test.
Trochu mne překvapilo malé zastoupení RSS kanálů (42%), čekal bych víc. Nemůže to být tím, že hodně webů nepoužívá přímo RSS ale Atom? Tudíž tam mají:
<link title="…" href="…" type="application/atom+xml" rel="alternate" />Nešlo by z té statistiky ještě vytáhnout zastoupení jednotlivých agregačních formátů případně jejich verzí?
Šlo by, a udělám. Podle pohledu do kódu to bývá buď RSS, nebo Atom a RSS. Důvod nízkého zastoupení vidím spíš v tom, že mnoho z těch webů nemá z principu pro RSS využití – třeba zrovna vyhledávače a portály.
28 serverů má ATOM i RSS, 176 jich má pouze RSS, 3 mají pouze ATOM. Konkrétní verze můžeme změřit příště (bude potřeba stáhnout i ten feed).
Viz také mé několikaleté srovnávání verzí PHP všech domén v
.cz. Zkoumal jsem i zastoupení jednotlivých webových serverů.Meta značku
Descriptionpovažuji za užitečnou. Vyhledávače (např. Google) její obsah totiž zobrazují v případě, že na cílové stránce nenajdou hledaný text (který je třeba jen ze zpětných odkazů).Značku
Keywordspodle mě na druhou stranu už prakticky nikdo nepoužívá.Zajímavé by bylo vědět, kolik serverů posílá stránky jako opravdové XHTML, tedy s hlavičkou application/xhtml+xml. Jinak je to jenom hra na XHTML, pokud prohlížeč dostane stránku jako text/html, tak ji zpracuje jako staré dobré HTML.
Můj tip: 0, slovy ani jedna.
Ad „pokud prohlížeč dostane stránku jako text/html, tak ji zpracuje jako staré dobré HTML.“
To není pravda – jestli myslíš to, čemu Firefox říká „Režim zpětné kompatibility“ a „Režim platných standardů“. „Režim platných standardů“ se použije, i když XHTML stránka přijde s HTTP hlavičkou
Content-Type: text/html„Režim zpětné kompatibility“ a „Režim platných standardů“ jsou zobrazovací režimy, nesouvisí s XHTML.
Obávám se, že tahle diskuse nikam nevede… ale na tohle ještě musím reagovat: souvisí to spolu právě v tom, že když stránka přijde s MIME typem
text/xml,application/xmlneboapplication/xhtml+xml, tak se použije (alespoň ve FF) ten „Full Standards Mode“.
A teď se zrovna povedlo něco pěkného :-)
V předchozím komentáři jsem omylem napsal <code> místo </code> (za application/xhtml+xml) a místo aby mi to systém omlátil o hlavu a řekl, ať to opravím, tak si něco domyslel – a samozřejmě si to domyslel špatně, protože zbytek věty měl být už normálním písmem. A k tomu je, milé děti, dobrá ta validita a striktní syntaxe (mimo jiné). Dobrou noc.
Striktní syntaxe ano, ale (alespoň v tomto případě) na úrovni kontroly vstupu, ne výstupu. Jasně, že je dobré, když vás systém při odesílání příspěvku upozorní na to, že tam máte chybu — o tom snad nikdo nepochybuje, ne? Ale nevidím žádné plus v tom, kdyby až do rána (v případě nějakého staršího článku pak bůhví do kdy) byla celá stránka mimo provoz, protože máte půlku věty v code…
presne tak HTML dokument s XML syntaxou a je stále len (chybný) HTML dokument. o type dokumentu rozhoduje jeho MIME typ.
viz Mozilla’s DOCTYPE sniffing
I když neříkám, že je to optimální…
Kdyby náhodou někdo nevěděl, kdo za to může: Microsoft a jeho parodie na www prohlížeč.
To ale nič nemení na fakte že keď posielam dokument s MIME typom text/html tak ho tým označím ako html dokument, bez-ohľadu na doctype, alebo syntax je to html s chybnou syntaxou… rovnako ako keď posielam súbor s MIME typom image/png tak tým prehliadaču dávam jasne najavo že je to súbor v PNG formáte a nemôžem ho považovať napr. za MP3 súbor. To že 90 percent html kóderov nesprávne používa HTML je už zase iný problém.
Nemyslím. Celkem dost serverů mění MIME typ mezi HTML a XHTML podle klineta a podle toho, co pošle v hlavičkách Accept.
Použitý Accept: „text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8“ – vzato z FF5.0 v základním nastavení. Zkusím prohodit a podívat se, jestli se to na výsledku nějak projeví, to je dobrý tip, díky.
Původní hlavičky požadavků:
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
User-Agent: Mozilla/5.0 (Windows NT 6.1; WOW64; rv:5.0) Gecko/20100101 Firefox/5.0 FirePHP/0.5
Accept-Language: cs,en-us;q=0.7,en;q=0.3
Accept-Encoding: gzip, deflate
Accept-Charset: windows-1250,utf-8;q=0.7,*;q=0.7
Při druhém pokusu jsem změnil pořadí text/html a application/xhtml+xml. Tipni si, kolik serverů z „TOP 371“ na to zareagovalo jiným MIME typem…
42?
fakt netuším ;-)
Žádný. Co jsem dělal špatně? Resp. jinak – máš po ruce nějaký příklad serveru, který mění MIME typ podle hlavičky Accept, na kterém bych to mohl ověřit?
Asi si nedělal špatně nic. Tak před pěti lety to dělalo opravdu hodně serverů, pokud vím, tak i přímo http://www.w3.org. Nicméně jak tak teď koukám, už asi všichni pochopili, že to byla blbost, a servírují výhradně jako text/html. Tak sorry za mistifikaci a ztracený čas.
Spočítal jsem, a výsledek je následující:
– Jeden server posílá MIME application/xhtml+xml a neuvádí XHTML DTD.
– Šest serverů uvádí XHTML DTD a posílá hlavičku xhtml+xml.
– Zbytek má pouze DTD a MIME typ text/html
A co posílal klient v HTTP hlavičce
Accept? Dá se zjistit, kolik serverů na její hodnoty reaguje?Viz odpověď Jirkovi, to jestli servery reagují měřím právě teď.
Díky za statistiku, jak jsem, psal na začátku, čekal jsem jiné výsledky. A jak zmínil Jirka Kosek, tak před zhruba pěti lety byla situace jiná, hodně serverů se posílalo vybraným prohlížečům application/xhtml+xml.
Zase to tu srší samými odborníkmi :)
K veci, nie je nič tažšie ako do hlavičky vložiť:
A co se tím změní?
A čo tým chcel básnik povedať?
A funguje to někde? Ve FF ne – na rozdíl o uvedení DOCTYPE (pak se XHTML zpracuje skutečně jako XHTML navzdory špatnému MIME typu v HTTP hlavičce).
Teda od Vás jsem bludy nečekal. Rozhoduje pouze mime typ. Takže třebas takový Interval.cz se v prohlížečích naštěstí zpracovává jako HTML, přičemž jako XHTML by neprošel, protože kód není well-formed, což je, jak známo u XHTML nutná podmínka pro zpracování XML procesorem.
Viz Mozilla’s DOCTYPE sniffing, co už jsem tu odkazoval.
„This document describes how Mozilla uses the DOCTYPE declaration to determine strict mode vs. quirks mode.“
Na základě Doctypů vyjmenovaných v tom dokumentu pak prohlížeč pracuje v „Full Standards Mode“. Nebo mluvíš o něčem jiném?
Ano, mluví o něčem jiném. XHTML „by se mělo” zpracovávat jako XML, kdežto pokud se pošle jako text/html, tak se zpracovává jako HTML. Rozdílu mezi zpracováním jako HTML a XHTML je víc, připravil jsem demo dvou odlišností. V případě „opravdového XHTML” používám koncovku .xhtml, server pak pošle v hlavičce Content-Type: application/xhtml+xml, meta element je k ničemu.
Až čumím, to je sila. Bubák ako jeden z mála prispievateľov, ktorí naozaj rozumejú tomu, o čom hovoria, tu má zošedené príspevky (kto všetko mu dal mínus?), a pán pseudoodborník Franta Kučera tu za svoje do očí bijúce bludy by bol na serióznejšej diskusii dávno skritizovaný tak, že by sa išiel zahrabať pod čiernu zem.
Človek by čakal, že v diskusii sa dozvie ďalšie užitočné informácie alebo upresnenia. Otras.
Jaké bludy myslíš? Akorát jsem psal, že FF, pracuje v režimu platných standardů (a ne zpětné kompatibility) i na základě DOCTYPE uvnitř stránky a ne jen na základě HTTP hlavičky Content-Type.
Jistě, ale bohužel tady nebyla řeč o DOCTYPE nebo režimu (ne)platných standardů. Dle mého laického názoru se cvrlikalo o rozdílu zpracování application/xhtml+xml a text/html. Ten první má správný prohlížeč parsovat jako XML, což je daleko přísnější než obyčejné HTML a občas velmi problematické (http://blog.ataxo.cz/article:xhtml-mime-typ).
1) Projdi si prosím znovu moje komentáře a napiš, jestli něco z toho není pravda.
2) K tomu odkazu: příběh je to pěkný a podle mého dokazuje výhodnost „žluté obrazovky smrti“ – vždyť pomohla odhalit mnohem závažnější problém: nějaký všivák po cestě manipuluje s obsahem stránky. Když něco vygeneruji na serveru, tak chci, aby to přesně tak dorazilo ke klientovi – nechci na své stránce mít přepsané texty (třeba ceny nebo čísla účtů, to by bylo zajímavé…), vložené reklamy ani zmršené XHTML, ani nic jiného… část z toho pomůže odhalit XML parser. Ale daleko účinější je HTTPS – proto ho používám, kde to jen jde – tak se zajistí, že klient dostane to, co mu posílám, a ne nějaké blbosti, nad kterými nemám kontrolu.
3) Co se týče: „A dokud bude na světě jenom pár setinek promile…“ – to mi připomíná argumentaci typu „i kdyby to zachránilo jediný lidský život“.
1) Jen říkám, že mluvíš o koze a zbytek lidí tady o voze :) Viz třeba komentář od blizze (nebo Timyho), zcela potvrzuje, co jsem si před pěti vteřinami ověřil. Doctype sniffing na tom nic nezměnil. Stránka hlásila, že je v režimu „plné podpory standardů“, ačkoliv to nebyl stejný způsob parsování jako u „pravého“ xhtml+xml MIME typu.
2) a 3) Jasně, však to byl taky asi první odkaz, na který jsem narazil a použil jsem ho jenom jako demostraci, že XML parsování je něco jiného než HTML. ;)
Ja ti ukážem, čo nie je pravda:
„Ve FF ne – na rozdíl o uvedení DOCTYPE (pak se XHTML zpracuje skutečně jako XHTML navzdory špatnému MIME typu v HTTP hlavičce).“
Ak je v HTTP hlavičke „zlý“ MIME typ (text/html), XHTML sa nikdy nespracuje ako XHTML.
Já ale od začátku psal o tom, že se použije „Režim platných standardů“.
To ale vôbec nesúvisí s otázkou, či sa kód parsuje HTML alebo XML parserom – na to má vplyv jedine MIME typ. Táto stránka je tiež jedným z príkladov, keď sa použije „režim platných štandardov“, v doctype deklaruje XHTML a aj napriek tomu tento kód každý jeden prehliadač parsuje ako HTML.
To zašednutí je věru nějaké pochybené – vidím zašedlé i naprosto neškodné příspěvky (třeba moje informace o tom, jaké hlavičky byly v měřeních použité). Poptám se u vývojářů, jestli tam není něco divného.
Nešlo by spíš vývojářům říci, aby to zrušili úplně? Je to k něčemu dobré, že nějaká část příspěvků je zešedlá a já musím přejíždět přes příspěvek myší, abych ho mohl pohodlně přečíst? Úplně nejlepší je to pak na mobilních věcech, kde ani tou myší přes příspěvek přejet nemůžu… :)
+1
(a tady jsou 4 znaky)
Spravil som podobné štatistiky všetkých .sk domén. Okrem iných vecí sa snažím odhadnúť framework (čo nie je a nikdy nebude 100-percentné).
http://www.statistiky-domen.sk/
Po zlepšení detekcie frameworkov chcem preskúmať aj české domény, len sa budem musieť dostať k ich zoznamu.
Moc pěkné :-)
Kdy budou údaje pro ČR?
A chválím i za ty grafy (funkční bez Flashe).
ČR by som chcel spracovať do 2 mesiacov. Ale neviem, či sa dostanem k zoznamu domén.
Grafy sú riešené JS knižnicou Highcharts :)
Sľúbené štatistiky českých domén. Je ich tam cca 500k.
http://www.statscrawler.com/?tld=Czech
… z 25+38% na 15+27% v jedné skupině a z 3+4% na 17+14% ve druhé. Tady někdo předvyplňuje přihlášku na ministra financí, že?!
P.S. ty subpixely v grafech vypadají příšerně i v nativu :-( . Fakt to nejde vypnout, nebo udělat v něčem slušnějším – třeba Gnumericu nebo VisiCalcu?