VersionPress český projekt pro správu WordPressu pomocí Gitu
Na DevBlogu byl dnes představen VersionPress – projekt, který dokáže verzovat celé WordPress weby v Gitu. To umožní nejen návrat do libovolného stavu z historie webu, ale například i snadnou synchronizaci mezi testovacím a živým prostředím, úsporné zálohování, sdílení přes GitHub a tak dále.
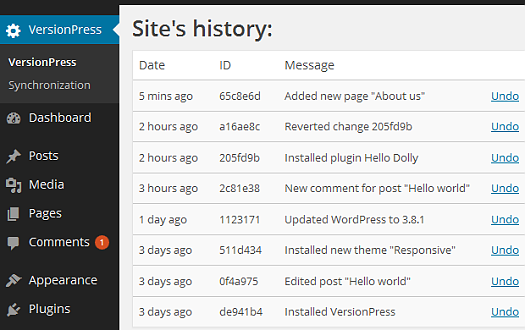
Web projektu je na http://versionpress.net/, kde rovněž probíhá crowd-fundingová kampaň na realizaci vývoje. Pokud se české vývojáře rozhodnete podpořit, můžete použít kód „CZSK“ pro získání 50% slevy.

