Ukládáme hierarchická data v databázi – III

V minulých dvou dílech jsme si ukázali rozdíl mezi „klasickou“ cestou ukládání stromu a představili jsme si metodu MPTT. Předtím, než se zběsile vrhneme do implementace v rámci našich CMS, podívejte se, na jaké problémy jsme během tří let narazili my.
Seriál: Ukládáme hierarchická data v databázi (3 díly)
- Ukládáme hierarchická data v databázi – I 5. 3. 2012
- Ukládáme hierarchická data v databázi – II 14. 3. 2012
- Ukládáme hierarchická data v databázi – III 19. 3. 2012
Nálepky:
Tento článek je závěrečným dílem mini seriálu o MPTT.
Poznámka autora: Tento článek popisuje zkušenosti a trable, které jsem měl při implementaci MPTT stromů do CMS, které používá společnost WDF. Momentálně pro tuto společnost dokončuji jeden projekt, a ačkoliv dělám na volné noze, styl psaní článku bude, jako kdybych byl zaměstnancem WDF. Jednak je to proto, že jsem pro WDF skutečně pracoval, ale také proto, že k WDF mám srdcový vztah. Obraty „my,“ „naše“ a všeobecné použití množného čísla tedy značí tým WDF před 3 lety.
Základní premisou článku je systém, do kterého jsme MPTT integrovali. Bylo to naše vlastní CMS, které používáme na spoustu projektů s postupnými obměnami dodnes. I když je CMS silně specifické, na některé problémy můžete narazit i vy ve vašich implementacích; proberme si tedy nejdříve, jakou jsme měli výchozí pozici my a na co všechno jsme narazili.
Naše CMS je postaveno na jednoduchém principu – vše je modul, nicméně ke všem modulům se přistupuje přes definované metody. V jednotlivých modulech jsme nemuseli implementovat metody getItem a podobně – všechny nám obstarává jedna a ta samá metoda. Nemohu přesně sdělit, jak to děláme, ale mohu sebevědomě říct, že to je poměrně chytrý systém. Navíc, všechny položky všech modulů jsou součástí jednoho velkého stromu, každá položka má unikátní ID napříč celým webem a tak podobně.
Výhoda je nesporná – nemůže se stát, že položka s ID 125 je v databázi několikrát (dle počtu modulů) – je tam jenom jedna, a ta je součástí právě jednoho modulu. Stejně tak fakt, že je vše součástí jednoho velkého stromu, zjednodušuje práci extrémním způsobem – a právě proto jsme MPTT vůbec implementovali.
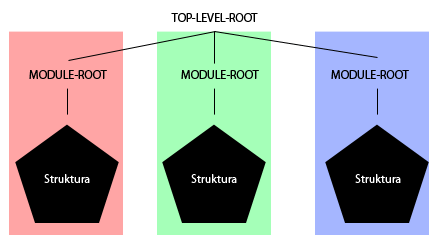
Premisa byla jednoduchá: existuje pouze jeden top-level-root, tedy hlavní uzel celého stromu, který pod sebou obsahuje dílčí uzly jednotlivých modulů (module-root), které obsahují strukturu daného modulu. Navíc systému (a databázi) je srdečně jedno, zda pod daným module-rootem jsou jen položky daného modulu nebo i modulů jiných, což dává extrémní volnost při implementaci jakéhokoli projektu. Struktura by se tedy dala načrtnout takto:

Více jazyků = více stromů
Systém podporuje multi-jazyčnost a to až na úroveň verzování. Implementačně jsme to měli tak, že jedna verze = jeden jazyk s tím, že jeden item může mít libovolné množství verzí a tím pádem i libovolné množství jazyků (a verzí pro dané jazyky.) Což nás při implementaci „starého stromu“ dovedlo k paradoxu, že každá jazyková verze má vlastní stromovou strukturu. Ano, jinak to nešlo – uživatelům CMS prostě nevysvětlíte, že ta daná položka musí být ve všech jazycích, i když ji nikde na webu samotném nepoužijí.
Což nás dovedlo k tomu, že při implementaci MPTT jsme museli rozlišovat nejen parametr „id položky“ (např. „získej všechny potomky item ID 125“), ale museli jsme rozlišovat i parametr jazyka. Ostatně – tak byl starý strom naimplementován také, takže potud je vše ok. Pouze když se přidávala položka: nestačí „prostě updatnout“ všechny položky napravo, je potřeba pamatovat i na to, že se aktualizují položky jen pro daný jazyk.
Existují však moduly, které musí být přístupné pro všechny jazyky zároveň, takové, které mají také vypnuté verzování (a nebo ho mají pro všechny jazykové mutace stejné). V rámci politiky jednoho stromu ale nic takového neexistuje – nemůžeme prostě takové moduly „vyčlenit“ do samostatné tabulky – to by zbořilo všechny výhody, které díky této politice máme k dispozici. Výsledek? Při aktualizaci modulu, který má obsah stejný pro všechny jazyky, je nutné aktualizovat všechny stromy, tedy všechny jazyky.
Kanón na vrabce? Nemyslím – kdybychom použili přístup „všejazykové moduly technicky používají speciální jazyk“, tak musíme JOINovat, podmínkovat, a záhy nám celý systém naroste do obludných rozměrů. Tradeoff? Snížený výkon při přidávání a mazání položek v databázi – ale nakonec, to je cca 1% aktivit na webu, takže potud je to zatím pořád ok.
Držte si klobouky, teprve začínáme.
Smazání položky = rekurzivní mazání
Každá databáze má svoji abstrakci. A jak řešíte vy, když někdo odstraní složku, která obsahovala podsložky a hlubší strukturu? V lepším případě je na to trigger v databázi ON DELETE – v tom horším si to zbastlíme přímo v abstrační vrstvě. Pamatujete na to, jak se mažou položky ze stromu? Počítejte se mnou: máme uzel, který potřebujeme smazat. Ten obsahuje 10 složek, kdy každá obsahuje další 2 položky. Celkem tedy budeme mazat 30 uzlů.
A řekněme, že první implementace bude cestou nejmenšího odporu – prostě si získáme (např. přes MPTT::getDescendants – viz příklad) všechna ID, která daný uzel obsahuje, zavoláme na ně naši abstrakční class (např. new TreeItem($id)) a smažeme je ve foreach cyklu pomocí $TreeItem->delete(). Tedy něco podobného následujícímu:
$descendants = MPTT::getDescendants($this->left, $this->right);
foreach($descendants as $one) {
$item = new TreeItem($one->id);
$item->delete();
}
Gratuluji, právě jsme zavolali 60 (!) UPDATE příkazů na databázi. Ostatně tento problém se týká i použití triggeru – trigger totiž zavolá sám sebe při mazání dílčích položek.
Pozn. autora: 60 updatů není moc pro běžný web. Poznáte to až ve chvíli, kdy „napravo“ od smazané položky je 300 000 dalších položek, které jsou v 16 jazycích – reálně tak databázi řeknete, aby aktualizovala 288 milionů záznamů (60 update queries * 16 jazyků * 300 000 položek.) True story.
Co s tím? Když budeme mazat položky z databáze, nesmíme si dle principů OOP „zjednodušit práci“ – je nutné použít kód, který identifikuje, o kolik se mají vlastně left a right parametry snížit. Stačí nám tedy následující kód:
// Smažeme položku a všechny její potomky
dibi::query("DELETE FROM [mptt] WHERE [id] = %i", $this->id);
$descendants = MPTT::getDescendants($this->left, $this->right);
foreach($descendants as $one) {
dibi::query("DELETE FROM [mptt] WHERE [id] = %i", $one['id']);
}
// Vypočítáme rozdíl, aktualizujeme strom
$difference = $this->right - $this->left + 1;
dibi::query("UPDATE [mptt] SET [left] = [left] - %i WHERE [left] > %i", $difference, $this->right);
dibi::query("UPDATE [mptt] SET [right] = [right] - %i WHERE [right] > %i", $difference, $this->right);
Takto spustíme skutečně pouze příslušný počet DELETE příkazů + dva příkazy na aktualizaci stromu. A ano – pokud neimplementujeme MPTT přímo na úrovni databáze (což nedoporučuji – viz další bod), pak musíme použít abstrakci.
Hromadný import položek
Obecně doporučuji MPTT implementovat v rámci PHP abstrakce nad databází. Algoritmus lze samozřejmě implementovat i v rámci databáze přímo, například pomocí triggerů nebo funkcí, nicméně pokud to uděláme, musíme mít možnost aktualizaci stromu vypnout.
Příklad z praxe: implementovali jsme možnost hromadného importu do určitých modulů – to není na škodu a automatizovaný import se běžně používá; nicméně nepoužili jsme funkcionalitu pouze na začátku projektu (prvotní import dat); implementovali jsme ji přímo do modulu jako takového. Problémy nebyly do té doby, než přišel klient a do živé databáze (s cca 50 000 položkami) chtěl naimportovat chabé 2000.
Import jsme měli vytvořený dle zásad OOP ,a tak jsme vždy vytvářeli new Item();, který jsme následně ukládali do databáze. Četli jste detailně předchozí část článku? Ano, stalo se přesně to, na co myslíte – pro každou novou položku jsme posílali do databáze dva updaty. Naštěstí jsme si toho všimli sami a nemuseli čekat na klienta, až se ozve „on je ten import nějaký tentononc – pomalý…“
Je obecně dobrá strategie mít možnost MPTT vypnout – třeba konstantou, statickou proměnnou, či jinak – tak, jak vám to sedí. Vypínejte ji přesně pro takovéto případy a na konci importu celý strom přepočítejte. Věřte tomu nebo ne – ale i při 300 000 položek (v 16 jazycích) přepočítání stromu netrvá nějak dlouho. Navíc u hromadného importu klient očekává, že si počká – takže 30s skript není překážkou. (tak jako tak bych obecně doporučil hromadný import implementovat s pomocí AJAXu, kdy klient vidí, „že se něco děje“ – opravdu nechcete, aby začal zběsile mačkat F5.)
Prioritizace a rozdělení stromu
Při opravdu velkých stromech se může stát ještě jedna věc – strom je prostě už moc velký na to, aby ho databáze „utáhla“. I když bych si představil e-shop typu kasa.cz, můžete s tím přijít do styku také. Pro mne existují dva způsoby, jak se s velkým stromem vyrovnat: doplnit ještě jedno dílčí dělení stromu, a nebo implementovat prioritizaci stromu.
Dílčí dělení bych si představil například pomocí parametru mptt_group – nebo jazyku, tak jak ho máme implementován my. V takovém případě by se parametr mptt_group používal společně s parametry left a right, tedy například nějak takto:
$descendants = MPTT::getDescendants($left, $right, $group);
Tím se efektivně strom zmenší – platilo by ale, že top-level-root je přítomen (duplikován) do všech skupin. Databáze by pak vypadala nějak následovně:
Druhou metodou, zajímavější, by mohla být prioritizace stromů – nemuseli bychom přepisovat všechny kódy tak, aby obsahovaly mptt_group – přepsali bychom pouze přepočítávací metodu. V podstatě by při selektování počítala s parametrem „priority“, který by určoval, „jak moc napravo“ má daný strom být:
SELECT * FROM `mptt` WHERE `parent` = %i ORDER BY `priority` ASC
Poté bychom dali nejnižší prioritu modulům, které mají nejvíce položek – jakkoli to může znít jako protimluv, nejvíce položek obsahuje například modul kategorií atp. Díky tomu, že tyto moduly nejsou tak často aktualizované, nebude docházet k neustálému UPDATE nad položkami kategorií – prostě proto, že by od nově přidané položky byly „nalevo“ a tím pádem nezapadaly do update podmínek.
Jedna složka na více místech = rozbitý strom
Naše CMS má jednu naprosto geniální funkci – jedna položka může být na více místech ve stromu, a přitom v databázi existovat jenom jednou. A věřím tomu, že nejsme jediní. Nicméně – na tohle si je třeba dávat setsakramentský pozor při implementaci. Dejme si názvosloví: složka obsahuje další pod-položky, položka neobsahuje nic dalšího.
Pokud je položka na více místech, pak má logicky více záznamů ve stromu. Tady je vše vše v pohodě. Problém nastane, pokud složce umožníme, aby byla na více místech.
Guru Implementace^TM velí, aby se zbytečně neduplikovali záznamy v databázi. Zároveň, abychom to vůbec umožnili, budeme mít jednu tabulku na položky a jednu samostatnou na strom. Takže položka.id je unikátní, ale strom.id není s položka.id svázané – k tomu se používá parametr strom.položka_id . A aby vše bylo jednoduché, „parent“ není odkaz na strom.id, ale na položka.id:

Cesta nejmenšího odporu velí: složku do stromu vložíme dvakrát, a je to.
U MPTT tomu ale v tomto případě tak není – pokud „parent“ odkazuje na položka.id, pak nás nic nenutí k tomu, aby struktura složky byla ve stromu duplikovaná. Vzhledem k tomu, že MPTT údaje udržujeme v tabulce stromu, pak nám dojde k re-indexaci dílčích položek dané složky a to přesně ve chvíli, kdy indexační skript do dané složky „vleze“ podruhé.
Toto zní složitě – a dokud nebudete mít CMS postavené právě tak, aby jste mohli mít jednu položku na více místech ve stromu, tak se k tomuto problému ani nedostanete. Nebudu proto příliš ztrácet čas nad tímto problémem, dám vám pouze radu:
Pokud máte strom oddělený od obsahu položek, pak jako „parent“ používejte odkaz na ID v tabulce stromu. I když se to může zdát jako nešikovné, ve skutečnosti vás to zachrání právě od tohoto problému – a tohle se sekne do kódu velmi jednoduše, prostou nepozorností.
Statická implementace MPTT class
Nakonec pro Vás mám lahůdku – vytvořil jsem vám knihovnu pro práci s MPTT. V kombinaci s mptt.sql souborem v rámci přiloženého příkladu si můžete sami vyzkoušet, jak knihovna funguje a hlavně jestli vám celý princip sedí. Pokud si dáte pozor na implementační chyby, které jsem se pokusil popsat v tomto závěrečném díle, pak vám skutečně nic nebrání v používání MPTT v projektech, kde jeho užití dává smysl.
Celkově zastávám názor, že MPTT je dobrá metoda – při tvorbě front-end ji používám takřka denně s vědomím, že se jedná o vysoce optimalizovanou metodiku získávání výsledků ze stromové databáze.
Přeji mnoho úspěchů!



Dobrý den,
nebylo by lepší využít k mazání spíše delete pracující pomocí left a right ala:
mysql_query(„DELETE FROM strom WHERE lft >= $row[lft] AND rgt <= $row[rgt]“); ?
viz http://php.vrana.cz/traverzovani-kolem-stromu-prakticky.php
Nemuselo by se pak volat mazání každé položky podstromu zvlášť, ale obstaral by to jeden sql query.
No tady jde asi o to, ze ke kazde polozce ve stromu potrebuju smazat taky polozku z jine tabulky, tak asi proto.
A kde je problém?
1) delete …. where polozka_id in (select polozka_id from ….between … and …)
2) delete from strom where strom_id between … and …
Nebo ještě lépe: cizí klíče a kaskáda.
Autorovo řešení mazání ve foreach cyklu mi přijde zbytečně neoptimální.
Pokud se nepletu, pro každého potomka ( $descendants ) v uvedeném příkladu zasílán jednu query na DELETE (viz: dibi::query(„DELETE FROM [mptt] WHERE [id] = %i“, $one[‚id‘]); ), což při počtu např. 1000 potomků znamená 1001 dotazů na db.
Tudíž se mi zdá lepší výše uvedené řešení (to v prvním příspěvku), které používá 1 query na DELETE ať už mažeme jakýkoli počet potomků.
Současně díky cizím klíčům a cascade delete jsou mazány i referencující položky v jiných tabulkách.
Z trochu jiného soudku, netuší někdo, jak napsat query tak, aby posunula UZEL stromu (vč. jeho podstromu) níže ve stejné úrovni?
Tzn. prohodit jej s následujícím uzlem (pokud má následníka).
Znamená to přepočítat left a right obou těch uzlů, zatím se mi však nepodařilo najít ten správný algoritmus, fungují mi pouze posuny uzlů směrem vzhůru ( na stejné úrovni).
My to řešili obecným přesunem ve stromu. Tzn. že dovedeme přesunout jakýkoliv uzel kamkoliv. Z hlediska prohození dvou uzlů na stejné úrovni to není nejoptimálnější řešení, ale funguje to dobře. K většímu rozdílu ve výkonu mezi nejoptimálnější a naší verzi dojde pokud vpravo od přesouvaných položek je hodně uzlů.
Pokud by jste chtěl modifikovat pouze lft/rgt přesouvaných uzlů a jejich potomků, musel by jste řešit problém chvilkové duplicity lft/rgt přesouvaných stromů a nebo dočasně jeden strom přesouvaného uzlu odklidit mimo aktuální rozsah (např. použít záporná čísla).
Vymyslet to by asi nebyl problém, ale u nás to byla jen podmnožina celkového problému přesunu uzlů. Stejně jsme potřebovali řešit obecné přesuny, takže jsme vyřešili přesuny a optimalizaci nechali na příště ;-). Výkonostní problémy máme nyní jinde (např přidávání uzlu do stromu pokud má strom 100k položek).
Nakonec pro Vás mám lahůdku – vytvořil jsem vám knihovnu pro práci s MPTT…. já ji tam prostě nevidím :)
Toto je lepsie:
http://www.sideralis.org/baobab/index.html
alter table TREE add column NodePath VARCHAR(1024)
insert into TREE (NodeId, NodeName, NodePath) values(newId, newName, parentPath + sprintf(‚%5d“,newId))
create index ix_node_path on TREE(NodePath)
…
pak všechny uzly pod daným uzlem:
select * from TREE where NodePath LIKE ‚xxxxx%‘
Omezení – hloubka stromu, počet položek, storage
Výhody – performance boost, jak čtení tak zápis je rychlý (žádný traversal), jednoduché hromadné operace
MS SQL 2008 R2+ umí T-TREE indexy, umí opravdu překvapivě rychle i
select * from TREE where NodePath LIKE ‚%xxxxxyyyyy%‘
tedy operace se subtrees