Třetí důvod proč zvolit Git : Decentralizace
Na Gitu nás dosud zajímala zejména jeho jednoduchost a flexibilita při každodenním používání. Nevěnovali jsme však pozornost tomu, co jej definuje: faktu, že se jedná o distribuovaný systém na správu verzí. V tomto článku se tedy zamyslíme nad tím, co to znamená, a jaké důsledky z toho pro naši práci vyplývají.
Seriál: Pět důvodů, proč zvolit Git (5 dílů)
- První důvod, proč zvolit Git: Neříká vám, jak máte pracovat 21. 12. 2009
- Druhý důvod proč zvolit Git: Snadné vytváření a slučování větví 28. 12. 2009
- Třetí důvod proč zvolit Git : Decentralizace 4. 1. 2010
- Čtvrtý důvod proč zvolit Git : Úpravy a opravy historie 11. 1. 2010
- Pátý důvod, proč zvolit Git : Zkušenosti uživatelů Gitu 18. 1. 2010
Nálepky:
Decentralizace
První článek našeho seriálu o Gitu jsme začali pozastavením nad tím, že „lidé od počítačů“ jsou paradoxně často konzervativní a nedůvěřiví k „novotám“. Podobně důležitým rozhodovacím faktorem je určitá obava ze ztráty kontroly. V případě verzovacích systémů je to ztráta kontroly nad hierarchií uživatelů, nad systémem oprávnění, a především nad jedním, autoritativním repositářem, v němž se skrývá „jedna pravda“, a žádná není nikde „bokem.“
Ale minulé století přineslo velký rozpad centralizovaných hodnotových systémů. Sigmund Freud ukázal, že lidskou duši nedefinuje „jeden příběh“ a po něm dekonstruktivisté ukázali, že text nemá jeden autoritativní smysl. A s velkým zpožděním decentralizace přichází i do „světa počítačů“; katalyzátorem je přitom, tak jako v případě většiny dalších změn, příchod internetu a webu.
Jedním z příkladů může být protokol BitTorrent, který otočil na hlavu tezi „čím více lidí stahuje nějaký soubor, tím pomalejší je stahování“. Rapidně rostoucí popularita decentralizovaných, nerelačních databází a key:value úložišť, která je motivována právě problémy se škálovatelností a flexibilitou tradičních databází, chystá podobnou revoluci ve vývoji pro web.
Co tedy znamená, že Git je distribuovaný, resp. decentralizovaný verzovací systém? Především to, že každá kopie repositáře je doslova jeho klonem, tedy plnohodnotným repositářem, který může technicky vzato kdykoliv nahradit jiný. Obsahuje celou historii, všechny publikované větve a tagy. Některý repositář samozřejmě může být a často bývá „centrální“ a slouží tedy ke sdílení mezi členy týmu, jak je obvyklé při používání centralizovaného verzovacího systému. Je to ale pouhá konvence a možností, jak si data vyměňovat, je mnohem více.
To, že každá kopie repositáře je dokonalým klonem, má radikální důsledky zejména pro zálohování: neexistuje pověstné „jedno zranitelné místo“ (single point of failure), které je třeba střežit jako oko v hlavě. V případě poškození „centrálního“ repositáře jej prostě smažeme, nahradíme jiným a chybějící data doplníme z ostatních klonů. Zálohování repositáře můžeme přitom provést i skrze infrastrukturu Gitu: při každé aktualizaci repositáře data odešleme příkazem git push do repositáře záložního, např. díky hookům.
Mnohem citelnějším důsledkem je ale to, že většina práce probíhá v lokální kopii repositáře. Kromě výměny revizí s ostatními Git nekomunikuje se vzdáleným repositářem: pokud je tedy vzdálený repositář nedostupný, mohu relativně dlouho v repositáři dále pracovat.
Pokud vám tedy vadí, že nemůžete prohlížet historii nebo commitovat ve vlaku z Brna do Prahy, decentralizované verzovací systémy vám otevřou úplně jiné možnosti. Platí to samozřejmě nejen pro „žádné připojení“, ale i pro „slabé připojení“ — tedy pokud vám commitování přes GPRS nepřijde jako zajímavé dobrodružství.
Nedostupnost repositáře ale nemusí být způsobena jen na mé straně, jak ji popisují příklady s vlaky a letadly. V praxi bývá často způsobena výpadkem konektivity na straně serveru s repositářem: „nejde repo, běžte domů“. Pokud používáte decentralizovaný verzovací systém, můžete velmi snadno nahradit „centrální“, sdílený repositář jiným. V závislosti na vaší infrastruktuře a potřebách tak můžete učinit přesunem repositáře na jiný server, zřízením dočasného sdíleného repositáře na libovolném serveru, kam mají ostatní SSH přístup, domluvou, že „centrální“ repositář je teď na chvíli „u Františka“, nebo prostým rozhodnutím, že synchronizaci uděláme zítra, „až to zase půjde“.
Z pohledu každodenní práce je ale nejvýznamnějším důsledkem úplně jiný rozměr: rychlost. Díky tomu, že pracujeme v lokálním repositáři, je většina operací daleko rychlejší než při práci v centralizovaných systémech, protože nedochází ke komunikaci přes síť. Rychlost je přitom kumulativní veličina: pět sekund může být docela málo, ale pokud trvá pět sekund operace, kterou dělám několikrát za čtvrthodinku, začne to hodně vadit. Navíc dochází k mentálnímu bloku: mám tendenci se takovým operacím vyhýbat. V Gitu probíhá prohlížení historie, práce s větvemi a další operace v řádu milisekund.
Tím, že práce probíhá lokálně, ale získáváme ještě jinou výhodu pro každodenní práci: tou je právě soukromá povaha repositáře. Dokud výslovně neřekneme „tohle pošli na server“, vše je jen lokálně a „bokem“. Už jen tento fakt je pro mnoho vývojářů hlavním důvodem přechodu na decentralizovaný verzovací systém (nejen tehdy, pokud vyvíjejí open source software). Pokud jste někdy jen trochu chtěli mít soukromé „pískoviště“, kam byste si po kouskách commitovali rozdělanou práci, zkoušeli bláznivá řešení, aniž by je hned viděli ostatní, a teprve potom se rozhodli, zda takové věci „pošlete dál“, Git a ostatní distribuované verzovací systémy vám opět otevřou úplně jiné možnosti práce.
Git tyto možnosti ještě násobí díky jeho schopnostem interaktivně upravovat historii, o nichž si povíme v následujícím článku. Zjednodušeně řečeno, umožňuje nám commitovat cokoliv, a teprve při publikování práce ji „učesat“ do prezentovatelné podoby.
Svoboda, nebo anarchie?
To někoho samozřejmě může už úplně vyděsit z pohledu „ztráty kontroly“. „Učesat“! Úpravy historie!! Soukromé „pískoviště“!!! Je to ale dáno zejména omezenou perspektivou. Může to znít překvapivě, software se ale nevyvíjí jen v korporacích s biometrickými čipovými kartami nebo firmách, které se takovými chtějí stát. Mnoho software vytvářejí jednotlivci či volně organizovaná společenství. Mnoho software se vytváří v přirozeně decentralizovaném prostředí, a jedním z hlavních příkladů je vývoj open source software (nejčastěji za přispění nejen „nadšenců“, ale i softwarových gigantů).
Git má toto prostředí „v genech“, neboť vzniknul pro správu verzí linuxového kernelu, jednoho z nejvýznamějších příkladů úspěchu F/OSS. Původní design Gitu je odvozen z workflow založené na výměně patchů e-mailem, jakkoliv bláznivé se vám to může zdát. (Mimochodem, dodnes Git nepotřebuje pro výměnu revizí přímé spojení s jiným repositářem, ale umožnuje revize začleňovat skrze přílohy e-mailů.)
Samotný fakt, že Git používají pro správu verzí velké či přímo gigantické projekty — ať již z pohledu počtu vývojářů, velikosti repositáře či jeho složitosti — jako je Ruby On Rails či Linux, je pádným důvodem, proč se nebát zvolit Git.
Při vývoji open source software je jedním z oblíbených oříšků otázka „kdo dostane klíče od repositáře?“ Okamžitě dělí přispěvatele do projektu na ty „s přístupem“ a na ty „bez přístupu“, vyžaduje obratné odpovídání na žádosti o „přístup“, složitou správu oprávnění všech těch „přístupů“, a tak dále. V Gitu je otázka „přístupu“ technicky a filosoficky vzato bezobsažná a nezajímavá. Protože každý repositář je dokonalým klonem, probíhá začleňování změn klidně tak, že správce projektu — nebo častěji správce části projektu, u větších repositářů — dostane upozornění na potenciálně zajímavou změnu ve forku repositáře, a pokud se mu taková zdá doopravdy, začlení ji do repositáře a „pošle dál“.
Podobně radikálně decentralizované workflow zpopularizoval mimo kruhy kernelových vývojářů, mezi běžnými smrtelníky, hlavní poskytovatel Git hostingu, server GitHub. Ten před rokem nabídl i efektivní grafické rozhraní pro správu příspěvků z „forků“ vašeho repositáře, jak vidíte z obrázku níže:
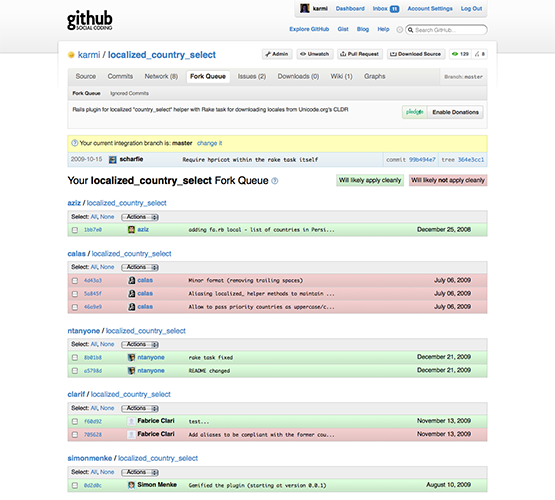
Právě poskytovatel Git hostingu GitHub se velkou měrou podílel na popularizaci Gitu, protože přinesl atraktivní a funkční rozhraní pro práci se sdílenými Git repositáři. Sám o sobě tvoří další z pádných důvodů, proč zvolit Git — přinejmenším pro open source software. Do softwarového vývoje totiž vnesl aspekty známé ze „sociálních platforem“ typu Facebook: možnost „sledovat“ zajímavé projekty nebo vývojáře, komentovat jednotlivé revize, vytvářet vlastní forky projektů a participovat tak na jejich vývoji.
Zaujal vás Git? Vyzkoušejte si spolehlivý a dostupný Git hosting pro soukromé repositáře na www.githosting.cz.
Samozřejmě, že odvrácenou stranou takové „radikální decentralizace“ je, že u mnoha projektů dochází k „rozkolísání“ vývoje a k etapám, kdy není zcela jasné, který fork je vlastně „nejlepší“. Ale zároveň to znamená, že nikdo není vydán všanc nedostupnému nebo nerudnému správci projektu v open source variantě vendor lock-in. Mohu jednoduše udržovat vlastní fork a začleňovat do něj změny z upstream (originálního repositáře). Pokud budou změny užitečné i ostatním, mohou buď žádat správce originálního projektu o jejich začlenění, nebo jej postupně začít ignorovat a začít využívat náš fork, nebo si dokonce vytvořit svůj, „ještě lepší“.
Přestože nejběžnější je „pseudo-centralizované“ workflow, decentralizovaná povaha a flexibilita Gitu přináší možnosti různých variant a vylepšení — nebo zcela odlišných workflow, než které můžeme vymyslet a realizovat v centralizovaných verzovacích nástrojích. Krátké informace v češtině o několika typech workflow najdete v příslušné kapitole na stránce Proč je Git lepší než X nebo v prezentaci z Webexpo 2009. Souvislejší informace v angličtině pak v knize ProGit, která sama je překládána za pomoci decentralizované workflow.
Pro příklad varianty „centralizované“ workflow můžeme uvést kolegy ze společnosti Centrum Holdings, kteří pro vývoj interního CMS Ella využívají decentralizovanou povahu Gitu velmi silně. Každý pracuje v lokálním repositáři, a hotovou práci odesílá do interního sdíleného repositáře (potud funguje koncept „centrálního“ repositáře). Pomocí post-receive hooků se spouští integrační testy, a pokud projdou, revize se odešlou dále do repositáře na GitHubu. Interní repositář přitom obsahuje soukromé větve, které se na GitHub neodesílají a poskytují další funkcionalitu (kupříkladu při odeslání revizí do specifické větve se opět pomocí hooků spustí procesy, které ze zdrojových kódů zkompilují Debian balíčky).
I bez toho, abychom radikálně otočili pohled na svět, nám tedy decentralizovaná povaha Gitu může přinést velké výhody. Příště se podíváme na to, jak ji dále využít při úpravách a opravách historie.
(Autor děkuje Honzovi Královi za cenné připomínky a podněty k článku.)
Karel Minařík
Karel Minařík navrhuje a programuje webové stránky a aplikace, poskytuje konzultace a školení v oblasti vývoje pro web a žije v Praze se svojí ženou a dvěma dcerami.


Zdravím, nemáte někdo radu nebo doporučený postup, jak při komunitních projektech na GitHubu používat začleňování u forknutého repozitáře tak, aby se autorovi původního repozitáře ve Fork Queue nezobrazovaly mnou integrované jeho změny, které jsem přijal pomocí Fork Queue?
Reprodukční postup:
1) Forknu si repozitář projektu, který je veden jen ve větvi master a vydání jednotlivých verzí probíhá otagováním.
2) Provedu si ve svém forku změny.
3) V původním repozitáři mezitím pokračuje dál vývoj.
4) Tyto změny si pomocí Fork Queue průběžně integruju. Ve výsledku mám v jedné větvi změny mé i původního autora, tak aby reflektoval aktuální stav projektu.
Při tomto postupu to dopadne podobně, jako to bylo popisováno v minulém článku ala použití jako Subversion 2.0 (nekoordinovaná práce v master větvi). Původnímu autorovi se ve Fork Queue zobrazí jak moje změny tak i jeho, které jsem průběžně integroval a ještě vzniká ona nepěkná pavučina při zobrazení historie repozitáře grafem.
Zajímalo by mě tedy, jakým postupem (ať už sekvence příkazů nebo struktury větví) lze (nebo zda-li vůbec lze) dosáhnout toho, aby původní autor viděl ve Fork Queue na GitHubu jen mé změny, nikoliv integrace. Pokud ale někdo forkne můj forknutý repozitář a provede změny, které pomocí Fork Queue přijmu, tak aby je původní autor ve své Fork Queue u mě taky viděl.
Nevím, jestli úplně přesně rozumím, kdyžtak zkuste poslat i URL na nějaké repo, kde je to vidět.
Ale obecně, ideální je ty „patche“ dělat v nějaké zvláštní větvi, na kterou pak směřuje pull request. Mnoho projektů vyžaduje zvláštní branch pro každý patch.
Tzn. nenavrhovat, aby přebírali z vašeho master, ale z těch větví, kde je to izolovaně. Tyhle zvláštní větve je pak potřeba pravidelně _rebasovat_ oproti jejich master, takže váš patch je pořád „aktuální“ a maintainer nemá práci s mergem. Github by se sice mohl poprat i s merge commity, ale detaily nevím, stejně jako nevím, jestli dělá cherry-pick nebo merge při zpracování Fork Queue. Chtělo by to ty URL :)
Jde to vidět například u repozitáře dibi u jednoho z jeho forků. GitHub při zpracovávání Fork Queue dělá prý cherry-pick.
Myšlenku jsem z vašeho snad vysvětlení pochopil, horší to bude s realizací, protože v některých věcech stále tápu :)
Netuším například jak přesně vypadají příkazy, které se dějí na pozadí toho grafického klikátka Fork Queue na GitHubu nebo jak mu vnutit, aby přebíral z jiné větve než master. Mohl bych pro jistotu poprosit ještě o případnou kratičkou ukázku sekvencí příkazů tohoto postupu, který jste popsal?
S URLs je to už lepší, už se mi rozsvítilo :) Jde tedy o ty commity, kde se liší autor a commiter, např. http://github.com/…d918825e3523 vs http://github.com/…5d6c67ac51f3
Tím pádem paranoiq aplikoval na ten svůj fork commity od dg přes Fork Queue. A protože tím dělá cherry-pick, commity se začnou zdvojovat, _pokud_ je dg zamerguje.
A tím pádem asi nejjednodušším rešením bude to, co jsem navrhoval minule, tzn. dělat své patche ve zvláštní větvi, a na tu posílat dg pull requesty. Tím pádem se do vašeho master dostanou až když pullnete z upstreamu, od dg. Je to jasnější?
(Kdyžtak pište mail, nebo běžte na IRC Freenode #github, ať z toho tady neděláme fórum o Gitu :)
OK dobře :-) Děkuji za info a za čas.
Rapidně rostoucí popularita decentralizovaných, nerelačních databází …
relačnost a decentralizovanost spolu nějak souvisí?
Mám takový dotaz a je to tak trochu OT, za což se omlouvám, ale tohle je momentálně jeden z nejaktuálnějších článků ohledně GITu. Osobně se asi tak 3. dnem učím git a pomalu na něj přecházím (doposud jsem nepoužíval nic, jen vlastní kopie, což tak nějak vypovídá o mých zkušenostech a znalostech) a chtěl bych se zeptat, jak je to s tagy.
Pomocí metody pokus-omyl jsem zjistil, že nastavování tagů pomocí „git tag xyz“ nastavuje poslední commit a že tag se uloží jen k jednomu commitu. Můj problém je, že nevím, jak zobrazit aktuálně nastavené tagy. Tedy, vím, že to jde pomocí gitk, ale v podstatě s gitem pracuji na příkazové řádce a i když preferuji klikací nástroje, s gitem pracuji v ní a když už, ta bych v ní chtěl dělat všechno, gitk pak používám pro vizuální kontrolu. Když použiji příkaz „git tag“, zobrazí se mi seznam všech tagů, ale neví někdo, prosím, jak zobrazit jen ty aktuální? Vezmu-li v potaz, že k jednomu commitu může být přiřazeno více tagů, padají metody jako „git tag | tail“, což by stejně moc nefungovalo z důvodu abecedního řazení.
Pořád si dokola pročítám ‚git help tag‘, ale na nic nemůžu přijít…
Nejdůležitější otázka je, k čemu přesně ty tagy využíváte, to z vašeho komentáře není úplně jasné.
> nastavování tagů pomocí „git tag xyz“ nastavuje poslední commit a že tag se uloží jen k jednomu commitu.
Tag vytvoříte nějak takto:
git tag -a v.0.1 -m "First version" fccbbk, tedy „vytvoř tag s názvem v.0.1 ukazující na commit s ID fccbbk“. Tag je (víceméně a zjednodušeně) pouze „přezdívka pro commit“ (viz příkazgit show v.0.1).> nevím, jak zobrazit aktuálně nastavené tagy
Tady nerozumím, co jsou „aktuálně nastavené“ nebo „aktuální“ tagy.
Eh, to se omlouvám za nepřesný výraz – myslím tím tagy týkající se posledního commitu.
Obecně jde o to, že když chci označit svůj commit na základě předchozího, udělám něco jako „git ziskej-posledni-tag“ a podle toho jej adekvátně upravím (např. inkrementuji).
> když chci označit svůj commit na základě předchozího, udělám něco jako „git ziskej-posledni-tag“ a podle toho jej adekvátně upravím (např. inkrementuji).
Teď se zas omlouvám já, ale pořád přesně nerozumím :) Ale v každém případě, tagy byste neměl nijak měnit. Pokud chcete „posuvný identifikátor revize“, tak na to je _branch_, tag je „neposuvný identifikátor revize“. Pořád ale není jasné, jak a k čemu ty tagy používáte.
Dobře, dám příklad:
Zadání: číselně označit každý commit jako revizi a to revXYZ, kde XYZ je číslo revize.
> git init
přidání souborů…
> git add .
> git commit -a
napíšu zprávu
> git tag rev0
úpravy
> git commit -a
zpráva…
> git tag rev1
další úpravy
… několik dní práce …
úpravy
> git commit -a
zpráva
! A hele, nepamatuji si číslo revize
> git ???
[výstup] rev123
> git tag rev124
> Zadání: číselně označit každý commit jako revizi a to revXYZ, kde XYZ je číslo revize
Aha, takže děláte tagy
rev0arev1, _po každém commitu_?Chcete mít nějaké „krásně sekvenční“ posloupnosti čísel „jako v SVN“? To nemá v Gitu a dalších DVCS valný smysl. Ten účel (otázka „k čemu“, ne otázka „co“) z toho pořád není jasný.
No, nedělám. I když neříkám, že nebyly časy, kdy jsem doufal, že by to tak šlo :3. Uznávám, že se git teprve spíš učím, každopádně:
– Svoje projekty – jak jsem výše psal – jsem doposud zálohoval do složek a to tak, že jsem měl složku „záloha“ a v ní složky „01“, „02“, „03“ atd. a chtěl bych to převést do gitu (šetří mě to přes 90% místa a je to rychlejší, když chci něco vytáhnout z archivu), ale číslování bych tam chtěl nechat, protože ty staré zálohy už tak mám označené a nemusel si někde dělat tabulku „To, co bylo ve staré záloze 32 je v nové záloze 3d67c…“ (v podstatě ty tagy mi umožní vytvoření této tabulky přímo v gitu)
– Druhá věc je když si chci označit libovolný release – bylo by úžasně pohodlné napsat něco jako „git tag –last-tagged-commit“ a jen inkrementovat dle potřeby
Jinak pokud jde o to „jako v SVN“: svn jsem nikdy nepoužíval a začal (a skončil) jsem se ho učit asi tak před půl týdnem. Pak jsem dospěl k závěru, že git je lepší (i když mě trochu mrzí to, že neukládá rozdíly mezi soubory, ale vždy celé soubory – blbě se tak budou verzovat binární soubory, které se trochu mění, ale co už).
Aha, super.
> „To, co bylo ve staré záloze 32 je v nové záloze 3d67c…“
Jako referenční „slovníček“ mezi „revizemi“ ve starém systému a v Gitu to smysl dává velmi dobrý, a tak je to správně a velmi dobrý nápad.
> bylo by úžasně pohodlné napsat něco jako „git tag –last-tagged-commit“
Aha aha, tak to asi hledáte
git describe[http://www.kernel.org/…escribe.html]Jo jo, to je ono, moc díky :). Nechápu, že jsem si to nenašel ve všech těch tutorialech a manuálech co jsem po netu sehnal :3. Moc díky
Super! :)
Jinak se můžete ptát na anglickém http://freenode.net IRC kanále #git nebo #github, hodně gitsterů taky máme na českém Rails IRC kanále #rubyonrails na serverech http://ircnet.cz.
Fajn, díky za info :)
Pripada mi, ze praci za nekolik dni davate do jednoho commitu. Pri delani zaloh kopirovanim to asi bylo nejschudnejsi, ale ze zkusenosti muzu rict, ze ve VCS je dobre delat vic jednoduchych commitu s kazdou zmenou/opravou/vyvojem. Lepe se pak hleda kde se neco pokazilo, muzete si davat opravy do nejake hlavnejsi vetve atd. Sice nemam takovou disciplinu, abych commitoval casto, ale s gitem jsem uz tak zvlcel, ze po tech par dnech rozcommitovavam do ruznych vetvi a pak je rebasuju :-)
Doporucuju to zkusit az se szijete a dokoncite migraci… (tedy ty male commity)
Popravdě řečeno jak kdy – ale (pokud jsem se do práce fakt „nezažral“) většinou to bývalo minimálně jednou za den. Začal jsem s tím, abych si uložil stabilní verze (bod obnovy) a pak před tím, než jsem se pustil do nějaké větší úpravy, která by to mohla všechno rozbít (k čemuž se v gitu – pokud to chápu správně – používají větve (branch)).
No, rozhodně si teď dělám nesmyslné „projekty“ a testuji, co dělá větvení a tak rebasování (zrovna jsem jednu rebasi potřeboval na migraci projektu – měl jsem tam prázdnou složku, která ovšem byla nutná k chodu a samozřejmě se neuložila, tak jsem tam všude do historie musel strčit nějaký soubor – .htaccess postačil :3).
Pokud jde o to commitování po každé změně – no, právě proto, že jsem si nebyl jistý, jak to dělat jsem si stáhl git repozitáře samotného gitu a pak linux jádra (byl jsem zvědavý, jak vypadá velký projekt) a v gitk jsem si prošel historii, jak se dělají jednotlivé commity (Linus je vážně ukecaný chlapík, většina ostatních vývojářů tam stručně popíše, co se děje, Linus tam u verze gitu 0.99 popisoval, jak kdysi pracoval na jakémsi projektu, kde verzí 0.99 bylo obrovské množství a jedna (asi 0.99.5 nebo tak) prošla všemi písmeny abecedy XD). Nicméně si nejsem jistý, jak by bylo nejideálnější to dělat (spolu s větvemi). Např. pokud chci psát changelogy rychle a snadno, napadlo mě, že bych využil tipu z knihy Git Magic a to „git log > Changelog“. Jenže ten výpis by byl značně nepřehledný kvůli té hromadě malinkých commitů, proto mě napadlo, že bych měl větvi master jen na jednotlivé verze softwaru (0.1, 0.2, …) a dále větev např. working, kde by byly průběžné úpravy, commity a tak (a ze které by se pak větvilo na různé experimenty a tak) a nové commity v master-větvi by vznikali čistě pomocí merge master a working a do popisu daného master commitu bych sepsal základní informace o změnách ve working větvi, což by se pak přeneslo právě do changelogu :).
Eh, omlouvám se, mělo tam být „vznikaly“…
Tak na to, že děláte s Gitem 3 dny, postupujete a přemýšlíte naprosto správně!
(Jinak se koukněte na přepínače pro ten
git log, asi byste z toho changelog mohl generovat docela hezky.)Pekny serial, jen by se podle me pro lepsi nazornost hodil nejaky ten diagram ci obrazek
BTW: abych tu jen pořád nekydal o tom, že Mercurial mám radši než Git :-) Zjistil jsem, že Gitorious je svobodný software (šířený pod licencí GNU Affero GPL). To mi přijde jako dobrý argument pro Git – např. vývojářská* firma si může rozjet svůj vlastní Gitorious (no, často to bude kanón na vrabce**, ale což).
*) nebo jiná skupina, verzovat se nemusí jen zdrojáky, že?
**) chudáci vrabci, mám pocit, že poslední dobou dostávají čím dál víc zabrat :-)
clanek nema nalepku, na rozdil od 1., 2. a 4. dilu.
Díky za upozornění, už ji má.
chtel jsem se zeptat, zda je nejak mozne snadno zjistit po slouceni, co bylo delano ve ktere vetvi – priklad:
Jde nejak snadno zjistit, ze „7e5a3f8 procisteni formalnich warningu“ a „235a345 vyhozeni nepouzitych promennych“ bylo ve vetvi #45″ a „2248269 pridan novy model M1“ bylo ve vetvi master? Jde nejak snadno vypsat _vsechny_ commity, ktere byly ve vetvi #45 (tedy 235a345, 7e5a3f8 a 723446b, ale nikoli 2248269 a nikoli uvodni e29f2b0 ktery vzniknul pred odstepenim vetve)?
Nebo nedavaji tyto otazky rozumny smysl?
(ano, v tomto grafu, kde je par radku je to asi „videt“, ale ja s gitem zacinam a jak to vidim, tak tech vetvi budu pouzivat mraky a commitu v nich taky)