Protokol HTTP

HTTP je jedním z těch starých dobrých protokolů (jako třeba SMTP nebo POP3), u kterých člověk nepotřebuje žádný zvláštní klientský program a k tomu, aby se serverem navázal smysluplnou komunikaci a získal od něj odpověď, mu stačí telnet. V textu se podíváme na HTTP trochu techničtěji, „pod kapotu“.
Seriál: Webdesignérův průvodce po exotických krajích (3 díly)
- Datová URL pomohou s malými soubory 8. 8. 2011
- Protokol HTTP 12. 9. 2011
- Novinky protokolu WebSocket a režim fullscreen 7. 11. 2011
Nálepky:
V následujícím textu nebudeme objevovat nějaké žhavé novinky poslední doby, ostatně RFC, ze kterých budeme převážně čerpat, pocházejí z let 1996 a 1999, půjde tedy hlavně o opakování základů, které by měl znát každý, kdo se kolem webu pohybuje.
HTTP je aplikační protokol nad transportním protokolem TCP a je založen na principu požadavek/odpověď – klient pošle požadavek (typicky cestu ke stránce, kterou chce) a server mu odpoví. Pro většinu čtenářů to nebude žádná novinka, ale pro pořádek si ukážeme, jak taková komunikace vypadá (tučně: telnet klient, kurzivou: náš požadavek, zbytek: odpověď serveru):
$ telnet example.com http
Trying 2a01:430:2e::161...
Connected to example.com.
Escape character is '^]'.
GET /pokus.xhtml HTTP/1.0
Host: example.com
HTTP/1.1 200 OK
Server: nginx/0.7.67
Date: Sun, 28 Aug 2011 13:18:10 GMT
Content-Type: application/xhtml+xml
Content-Length: 153
Last-Modified: Sun, 28 Aug 2011 13:16:54 GMT
Connection: close
Accept-Ranges: bytes
<html xmlns="http://www.w3.org/1999/xhtml">
<head>
<title>Pokusná stránka</title>
</head>
<body>
<p>Ahoj světe!</p>
</body>
</html>
Connection closed by foreign host.
Pomocí telnet klienta navážeme TCP spojení se serverem na HTTP portu (80). Pomocí nejběžnější HTTP metody (GET) si vyžádáme stránku /pokus.xhtml. V klientské HTTP hlavičce Host uvedeme název domény (jedna IP adresa může obsluhovat více domén – tzv. virtualhosty). Prázdný řádek značí konec požadavku a následuje odpověď serveru – HTTP hlavičky odpovědi, opět dva konce řádku (CRLF) a samotné tělo odpovědi.
Zachováme spojení
HTTP protokolu bývá někdy vyčítána neefektivita (částečně právem, protože hlavičky odpovědi/požadavku mohou představovat nadměrnou režii), ovšem není pravda, že by kvůli každé dvojici požadavek/odpověď bylo potřeba navazovat nové TCP spojení (což je poměrně drahá operace, při které je potřeba mj. přeložit doménové jméno a vyhodnotit pravidla na všech firewallech po cestě).
Během jedné relace (TCP spojení) můžeme přenést neomezené množství požadavků a odpovědí. Ve verzi 1.0 HTTP protokolu se k tomu používala (neoficiální) hlavička klienta Connection: Keep-Alive, server pak věděl, že po vrácení odpovědi nemá uzavírat spojení, ale čekat na další příkazy. Ve verzi protokolu 1.1 se všechna spojení považují za trvalá, pokud není uvedeno jinak (hlavičkou Connection: close).
Trvalá spojení implikují nutnost uvádět délku odpovědi ( Content-Length, více viz RFC 2616), protože klient v tomto případě nemůže jednoduše číst data dokud nedojde k zavření spojení (protože k němu nedojde).
U běžně používaných HTTP démonů (Apache, Nginx atd.) je tato funkce samozřejmostí, ovšem u některých např. testovacích nástrojů, které simulují HTTP server případně klienta, nebo u některých knihoven trvalá spojení nejsou implementována a můžeme pak narazit na problémy s výkonem (např. při nahrávání většího objemu dat přes SOAP či REST rozhraní).
Vstup jen pro zvané
U mnoha stránek nebo aplikací potřebujeme nějak řešit přístupová práva a ověřovat uživatele. Tato funkcionalita je v protokolu HTTP přímo zabudovaná (viz RFC 2617), takže ji můžeme použít, aniž bychom znovu objevovali kolo (vymýšleli vlastní způsob předávání jména a hesla – např. pomocí POST parametrů). Komunikace mezi klientem a serverem pak vypadá takto:
- klient si vyžádá nějaké URL (stejně jako kterékoli jiné)
- server mu odpoví stavovým kódem 401 (Authorization Required) a hlavičkou
WWW-Authenticate: Basic realm="Prisne tajne" - www prohlížeč si od uživatele vyžádá jméno a heslo a pošle znovu požadavek na stejné URL, tentokrát ale s HTTP hlavičkou ve tvaru
Authorization: Basic ZnJhbnRhOm1vamUgaGVzbG8= - server zkontroluje přihlašovací údaje a pokud jsou platné, vrátí ve standardní odpovědi požadovanou stránku
Přihlašovací dialog v prohlížeči Chromium:
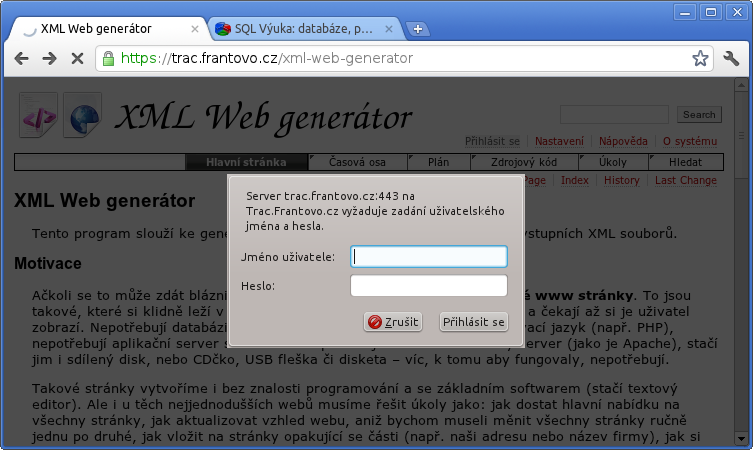
Za výhody HTTP autentizace můžeme považovat:
- použijeme hotové řešení
- standardní dialog (vypadá u všech webů stejně)
- velmi vhodné i pro API, situace, kdy na straně klienta není uživatel s prohlížečem, ale nějaký jiný systém
naopak nevýhodou je:
- uživatelská přívětivost přihlašovacích dialogů se v jednotlivých prohlížečích liší (někde např. přihlašovací dialog jedné stránky blokuje práci v jiných panelech)
- horší přizpůsobitelnost – např. když bychom při každém přihlášení chtěli po uživateli opsat CAPTCHA obrázek (do standardního dialogu ho nedostaneme)
Tip: jestliže píšete v Javě EE, můžete mezi jednotlivými způsoby autentizace (formulářová vs. HTTP) snadno přepínat – není potřeba upravovat aplikaci, stačí jen změnit konfiguraci aplikačního serveru.
Nenechme se zmást tím, že řetězec ZnJhbnRhOm1vamUgaGVzbG8= je na první pohled nečitelný – nejedná se o hash, ale o pouze o data v kódování Base64. Můžeme ho snadno rozkódovat příkazem base64:
$ echo ZnJhbnRhOm1vamUgaGVzbG8= | base64 -d franta:moje heslo
a získáme jméno a heslo v čitelném tvaru oddělené dvojtečkou. Bez ohledu na to, zda používáme formulářovou nebo HTTP autentizaci, je potřeba komunikaci šifrovat – použijeme protokol HTTPS (HTTP zabalený do SSL/TLS a běžící standardně na TCP portu 443). Jinak by totiž kdokoli, kde „jde kolem“, mohl odposlouchávat hesla uživatelů nebo jim posílat svoje data (podvržené stránky) a tvářit se, že to jsou data z našeho serveru.
Kromě „Basic“ autentizace umí protokol HTTP i „Digest“ autentizaci, při které se neposílá čitelné heslo, ale hash, a dále pak možnost pohodlného přihlašování se pomocí klientských certifikátů (jedna z nejbezpečnějších metod).
Náš zákazník, náš pán
Klient ve svém HTTP požadavku uvádí URL stránky, o kterou má zájem, ale může svůj požadavek upřesnit a uvést i další svoje přání – ta slouží k vyjednání optimálního formátu dat, který bude vyhovovat serveru i klientovi.
Jazyk
Jistě se vám již stalo, že na vás nějaká stránka, u které jste to vůbec nečekali, začala mluvit česky. Pravděpodobně se jednalo o nějaký redakční systém nebo jiný software, který je lokalizovaný i do češtiny, a jelikož WWW prohlížeč posílá spolu s požadavkem i preferované jazyky, může se aplikace na straně serveru přepnout do správné lokalizace. Preferovaný jazyk se uvádí v hlavičce:
Accept-Language: cs, en-gb;q=0.8, en;q=0.7, fr;q=0.6, de;q=0.5
Jazyků můžeme uvést více a můžeme jim nastavit váhy (platí i pro další hlavičky níže). Výše uvedenou hlavičkou klient serveru říká: dávám přednost češtině, dále pak britské angličtině, jakékoli angličtině, francouzštině, případně němčině. Pro označení jazyků a zemí se používají dobře známé dvoupísmenné kódy: ISO-639 (jazyky) a ISO-3166 (země).
Díky tomu můžeme automaticky lokalizovat ovládací prvky (tlačítka na webu, nabídky atd.), ale i samotný obsah (např. články, popisy zboží), pokud máme daný překlad. Přesto je ale vhodné umožnit i ruční přepnutí jazyka – uživatel může např. sedět u cizího nebo špatně nastaveného prohlížeče.
Kódování (češtiny)
Kromě jazyka může HTTP klient upřesnit i další údaje. Dříve bylo zvykem poskytovat stránky s různým kódováním češtiny: ISO 8859–2 (tzv. Latin 2), Kódování bratrů Kamenických (KEYBCS2), CP-1250 (Windows-1250) aj. Dělalo se to poměrně neohrabaným způsobem – soubor byl na disku serveru vícekrát v různých kódováních a uživatel musel kliknout na správný odkaz, podle toho, jaké kódování jeho zařízení podporovalo. Dnes sice téměř všude dominuje kódování UTF-8, ale pokud by bylo potřeba poskytovat stránky v různých kódováních, můžeme využít schopností protokolu HTTP. Klient (WWW prohlížeč) odešle požadavek s hlavičkou např.
Accept-Charset: utf-8
a server může stránku dynamicky překódovat do požadovaného tvaru.
MIME typ (formát)
Pomocí hlavičky Accept může klient požadovat určitý MIME typ. Takže při požadavku na stejné URL, ale s jinou hlavičkou může dostat v případě
Accept: text/plain
stránku převedenou na prostý text, zatímco v případě
Accept: application/xhtml+xml
dostane hypertext.
Stejně tak pomocí této hlavičky můžeme vyjednat se serverem vhodný formát obrázků nebo třeba videa.
Kódování (komprese)
Jednou z užitečných vlastností HTTP protokolu je možnost komprese dat. Oceníme ji zejména u textových formátů, jako jsou (X)HTML, CSS, JavaScript. Klient musí dát nejprve najevo, že kompresi podporuje – k tomu slouží hlavička:
Accept-Encoding: gzip, deflate
a server mu pak může poslat komprimovanou odpověď – v hlavičce odpovědi pak musí uvést, jakou kompresi zvolil (klient jich může deklarovat více):
Content-Encoding: gzip
Jelikož komprese se provádí při odesílání stejného souboru pro každého klienta znovu, umožňují některé HTTP servery jako např. Nginx, abychom měli zkomprimovaný soubor ( .gz) na disku vedle nezkomprimovaného a server pak pošle klientovi v HTTP odpovědi rovnou ten zkomprimovaný. V případě hodně navštěvovaných webů tím ušetříme nějaký ten procesorový čas serveru (vhodné pro JavaScripty a kaskádové styly).
Komprese je šikovná, ale musíme si na ni dát pozor, pokud před webový server resp. aplikaci přidáváme ještě nějaké filtry, které např. provádějí dodatečné úpravy textu stránky. V takovém případě musíme proud dat nejprve dekomprimovat a po úpravě zase zkomprimovat – proto je lepší kompresi provádět až v úplně posledním kroku těsně před odesláním klientovi.
Nebudeme to posílat znovu
Když navštívíme nějaké webové sídlo a procházíme jednotlivé jeho stránky, většina jeho obsahu – loga, pozadí, JavaScripty atd. – se nemění a bylo by hloupé je stahovat při každém přechodu na novou stránku znovu a znovu.
Klient (prohlížeč) proto může ve svém požadavku poslat hlavičku jako
If-Modified-Since: Thu, 13 Jan 2011 08:06:21 GMT
a server mu pošle daný obsah (např. obrázek), jen pokud byl po tomto datu na serveru změněn. V opačném případě pošle prázdnou odpověď se stavovým kódem 304 Not Modified a žádná zbytečná data se nepřenáší. Prohlížeč pak uživateli zobrazí data z mezipaměti.
Aby to mohlo fungovat, musí klient vědět, jak stará data minule stáhl. K tomu slouží hlavička odpovědi:
Last-Modified: Thu, 13 Jan 2011 08:06:21 GMT
Podle toho se pozná, že má klient staženou stejnou verzi souboru, jako je na serveru, a není potřeba ji přenášet znova.
V případě statických souborů, které servíruje přímo HTTP démon s tímto chováním nebudeme mít žádnou práci – pravděpodobně bude fungovat samo od sebe ve výchozím nastavení. Horší je to s dynamickým obsahem, který generujeme sami.
Dejme tomu, že vyrobíme obrázek, který si budou moci dát naši uživatelé na své stránky, a na něm bude logo našeho programu a pořadové číslo uživatele (nebo třeba člena nějakého klubu). Vezmeme statický obrázek z disku, dopíšeme do něj skriptem nějaký dynamický text a výsledek pošleme klientovi.
Jenže zjistíme, že tento obrázek se generuje pokaždé znovu a vždy se posílá po síti. Objem dat je sice malý a zátěž na serveru také, ale když uživatel stiskne F5 nebo přejde z jedné stránky na jinou, cítí ten rozdíl – zatímco jiné obrázky se vykreslí okamžitě, naše ikona jakoby problikne, je na ní vidět, že se stahovala znovu. Kvůli tomuto pocitu je dobré používat mezipaměť i u takto malých obrázků. Potřebujeme tedy přidat příslušné HTTP hlavičky a kontrolovat, zda má klient poslední verzi, nebo zda mu máme poslat novou. Implementace v PHP může vypadat přibližně takto:
<?php
$soubor = "grafika/logo.png";
$datum = filemtime($soubor);
$logo = imagecreatefrompng($soubor);
$pismo = "/usr/share/fonts/truetype/ttf-dejavu/DejaVuSans.ttf";
$barva = imagecolorallocate($logo, 0xAA, 0xAA, 0xAA);
$id = $_GET["id"]; // TODO: kontrolovat vstup
$headers = apache_request_headers();
if (isset($headers['If-Modified-Since']) && (strtotime($headers['If-Modified-Since']) == $datum)) {
/** Uživatel má načtenou poslední verzi obrázku → nemusíme posílat znovu */
header("Last-Modified: ".gmdate("D, d M Y H:i:s", $datum)." GMT", true, 304);
} else {
/** Uživatel nemá poslední aktuální verzi nebo nemá žádnou → pošleme obrázek */
imagefttext($logo, 8, 0, 15, 20, $barva, $pismo, "Uživatel č.".$_GET["id"]);
header("Content-type: image/png");
header("Last-Modified: ".gmdate("D, d M Y H:i:s", $datum)." GMT", true, 200);
imagepng($logo);
imagedestroy($logo);
}
?>
Skript můžeme vylepšit tak, že nebudeme kontrolovat jen datum poslední změny souboru logo.png, ale i samotného PHP skriptu (pro případ, že bychom např. změnili písmo nebo chování programu).
A v javovském servletu můžeme s HTTP hlavičkami pracovat takto:
protected void doGet(HttpServletRequest pozadavek, HttpServletResponse odpoved) throws ServletException, IOException {
String cesta = zkontrolujParametr(pozadavek.getPathInfo());
File soubor = new File(adresar, cesta);
if (soubor.isFile() && soubor.canRead()) {
if (soubor.lastModified() > pozadavek.getDateHeader("If-Modified-Since")) {
/** Soubor se změnil nebo ho klient ještě nemá načtený. */
odpoved.setContentType(MIME_TYP);
odpoved.setContentLength((int) soubor.length());
odpoved.setDateHeader("Last-Modified", soubor.lastModified());
/** Odešleme data… */
} else {
/** Soubor se od posledního načtení klientem nezměnil → není potřeba ho posílat znova. */
odpoved.setStatus(HttpServletResponse.SC_NOT_MODIFIED);
}
} else {
/** Neexistující nebo nečitelný soubor → HTTP 404 chyba */
odpoved.sendError(HttpServletResponse.SC_NOT_FOUND);
}
}
U statických souborů je používání mezipaměti prohlížeče samozřejmé, navíc to máme bez práce (postará se o něj HTTP démon). U dynamicky generovaných obrázků si podporu dopíšeme. Ale poměrně diskutabilní je využití mezipaměti pro samotné (X)HTML stránky. Jde o to, že mezipaměť nám u nich ušetří minimum prostředků (hypertext zabírá obvykle zlomek toho, co obrázky a další data) a zároveň správná implementace dá nejvíc práce – hlavně u složitějších stránek, které jsou poskládané „z mnoha různých kousků“, je velice pracné nebo až téměř nemožné zjistit datum poslední aktualizace celku. Obvykle tedy dojdeme k závěru, že takové řešení je neekonomické – buď bychom strávili neúměrně mnoho času implementací, nebo bychom dosáhli nedokonalého řešení, které bude pouze mást uživatele a způsobovat problémy.
Kromě výše zmíněných hlaviček Last-Modified a If-Modified-Since máme ještě další možnost: místo data můžeme použít hash/otisk dat: ETag: "686897696a7c876b7e" a klient se pak při opakovaném požadavku ptá s hlavičkou If-None-Match: "686897696a7c876b7e", na kterou opět může dostat odpověď 304 Not Modified, pokud se data na serveru nezměnila.
Klidně od prostředka
Většinu souborů přenášených HTTP protokolem (stránky, obrázky, ISO obrazy atd.) má smysl poslat po síti jen vcelku od začátku do konce. Jinak je tomu ale u multimediálních dat (filmy, hudba). Uživatel totiž může chtít skočit doprostřed záznamu, aniž by čekal, až se stáhne celý soubor. Opět nemusíme vymýšlet vlastní řešení (např. předání požadovaného úseku souboru přes GET parametry) a vystačíme si s vlastnostmi protokolu HTTP.
Požadavek může obsahovat hlavičku Range, ve které uvedeme, o jakou část souboru máme zájem. Např. pomocí hlavičky:
Range: bytes=500-999
si vyžádáme druhých 500 bajtů ze souboru na serveru.
Výhodou tohoto řešení je jeho standardizovanost – na straně klienta nemusí být nějaký náš speciální program, můžeme použít třeba multimediální přehrávač VLC (nebo video přehrávat rovnou v prohlížeči) a uživatel může přistupovat k náhodným částem filmu, aniž by ho musel stahovat celý.
Další využití má hlavička Range v případě stahování velkých souborů – pokud nám např. spadne WiFi spojení, nemusíme soubor stahovat celý znovu, ale navážeme ho – webové prohlížeče to většinou umí. Stahujeme-li soubor programem wget, slouží k tomu přepínač -c:
wget -c http://example.com/velky-soubor.tar.gz
Zde můžeme narazit na jedno úskalí: co když se soubor mezi tím na serveru změnil a my teď stahujeme druhou půlku jiné verze, než kterou jsme stahovali předtím? Výsledkem pak bude nekonsistentní a pravděpodobně nepoužitelný soubor.
Můžeme si pomoci hlavičkou If-Unmodified-Since – soubor stáhneme, jen pokud nebyl od určitého data měněn. Nebo můžeme integritu souboru zkontrolovat dodatečně – pokud nám server pošle jeho hash:
Content-MD5: Q2hlY2sgSW50ZWdyaXR5IQ==
Algoritmus MD5 je sice zastaralý a z bezpečnostního hlediska překonaný, ale pro potřeby kontroly integrity souboru (kde nepředpokládáme žádný zlý úmysl) ho stále můžeme používat.
Podpora Range hlavičky na straně HTTP démonů bývá dobrá a obvykle ve výchozím nastavení jednoduše funguje. To se týká servírování statických souborů – pokud ale soubory poskytujeme skrze nějaký náš vlastní skript nebo třeba servlet (např. je načítáme z databáze nebo programově ověřujeme uživatelská oprávnění), musíme podporu Range implementovat sami.
Uložit jako
Někdy nechceme, aby se obsah (obrázek, PDF dokument atd.) po kliknutí na odkaz uživateli neotvíral ve webovém prohlížeči, ale aby se zobrazil dialog pro uložení souboru na disk. V HTTP odpovědi můžeme klientovi poslat následující hlavičku:
Content-Disposition: attachment; filename=soubor.png
Ta se postará jednak o zobrazení souborového dialogu a jednak umožňuje nastavit nějaký přívětivý a smysluplný název (bez toho by pravděpodobně prohlížeč použil název skriptu a špatnou příponu).
Nástroje
V úvodu jsme si uvedli, že pro experimentování s HTTP protokolem nám stačí pouhý telnet klient, což je sice pravda, ale není to zrovna dvakrát pohodlné – můžeme proto využít i sofistikovanější nástroje.
Socat
Asi nás nebude bavit věčně psát:
GET /soubor.txt HTTP/1.1 Host: example.com
a vypisovat další hlavičky. Místo telnetu použijeme Socat – to je zjednodušeně řečeno nástroj, který umožňuje spojit dva konce libovolných „rour“ a nechat mezi nimi proudit data. Jedním koncem bude v našem případě TCP soket a druhým koncem standardní vstup/výstup (ale Socat toho umí daleko více – viz man socat). Takto můžeme pomocí socatu zhruba emulovat chování telnet klienta:
socat TCP:example.com:80 STDIO
Ale tím jsme si nijak nepomohli – příkazy musíme stále vypisovat ručně a vždy znovu. Kouzlo tkví v tom, že jako druhý konec můžeme místo STDIO napojit GNU Readline:
socat TCP:example.com:80 READLINE,history=$HOME/.http_historie
A teď nám zde bude fungovat historie příkazů podobně jako v BASH shellu – příkazy můžeme listovat pomocí šipek nahoru a dolů, velmi užitečné je také vyhledávání v historii (Ctrl+R), kde stačí napsat kousek dříve zadaného příkazu a stisknout Enter pro jeho odeslání. Historie příkazů se bude ukládat do souboru ~/.http_historie, takže se k ní můžeme vracet i po odpojení od serveru.
Wget a curl
Dalšími oblíbenými nástroji jsou Wget a curl – zde už nemusíme ručně vypisovat příkazy a hlavičky HTTP protokolu, ale jen zadáme URL a případně další parametry a nástroj provede tuto práci za nás. Stažení stránky wgetem s ručním zadáním jedné hlavičky:
wget --header='Accept-Language: cs' http://example.com/index.xhtml
Nebo pomocí curlu můžeme posílat data metodou POST – např. komunikovat s webovou službou:
curl -H "Content-Type: text/xml" -d @požadavek.xml http://example.com/webovaSluzba
Možnosti obou programů jsou takřka neomezené a nemá smysl je tu všechny vypisovat – viz man wget a man curl.
Firebug
Tento doplněk pro Firefox asi není potřeba webovým vývojářům představovat. Hodí se pro zkoumání kódu stránky a provádění okamžitých zásahů do DOMu, CSS stylů a JavaScriptu. Další jeho užitečnou funkcí, která nás teď bude zajímat nejvíc, je sledování síťového provozu. Díky ní se můžeme podívat na konkrétní hlavičky jednotlivých HTTP požadavků a odpovědí a pohodlně ladit. Na následujícím obrázku např. vidíme, že většina odkázaných souborů (obrázky, styly atd.) se nemusela ze serveru při obnovení stránky stahovat – server pouze odpověděl 304 Not Modified a webový prohlížeč použil dříve stažený soubor ze své mezipaměti:
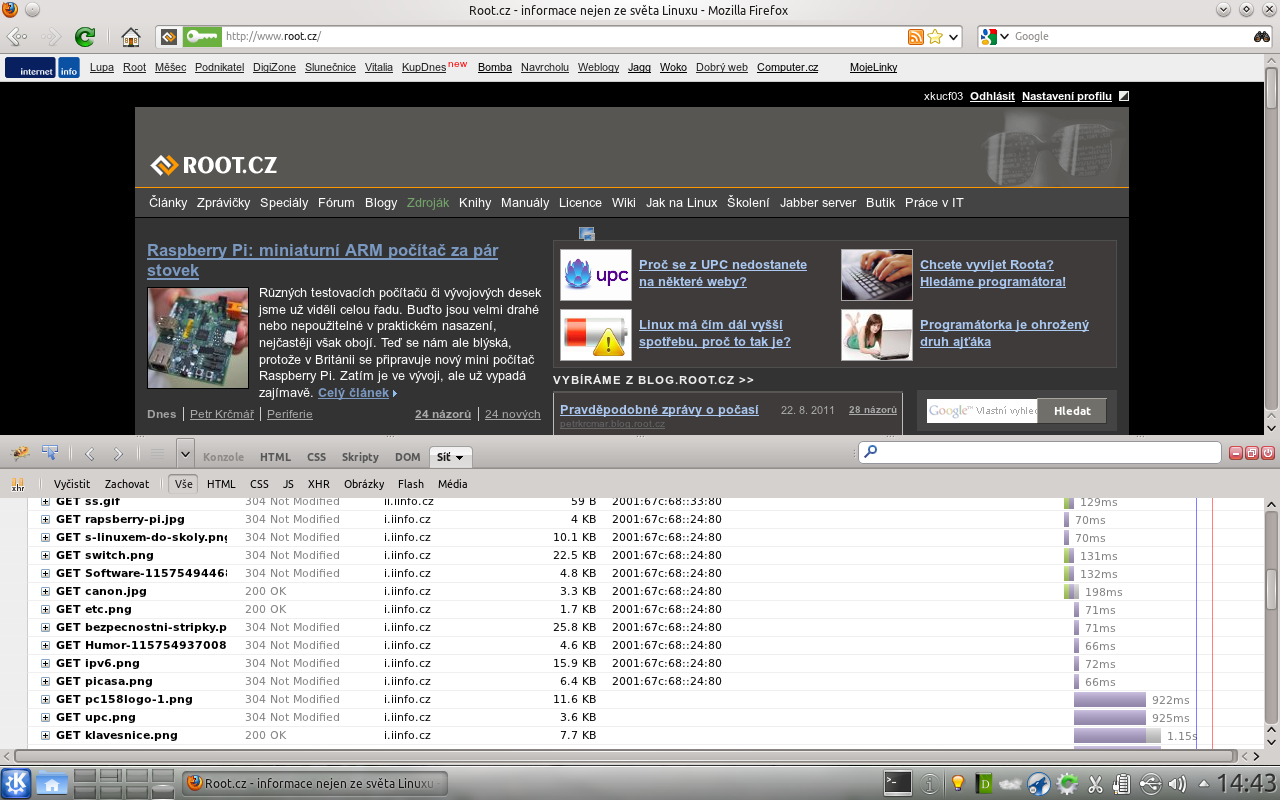
Firebug nám umožní dívat se i do šifrované HTTPS komunikace (jelikož prohlížeč přirozeně má k dispozici i nezašifrovaná data), ke které bychom se jinak nedostali (museli bychom použít vlastní proxy server, který by komunikaci šifroval/dešifroval). Ale jelikož HTTP klientem nebývá zdaleka jen webový prohlížeč, bude se nám k ladění hodit i následující nástroj:
Wireshark
Wireshark (dříve Ethereal) a jeho kamarád tshark jsou nástroje pro odchytávání síťového provozu a jeho následnou analýzu. Jelikož síťový provoz nemůže zachytávat obyčejný uživatel (to by byla velká bezpečnostní díra) a jsou potřeba práva superuživatele (roota), musíme pustit Wireshark přes sudo ( gksudo, kdesudo…). Ale vhodnější bude pustit pod rootem jen program tshark, který odposlechne komunikaci a předá ji do pojmenované roury (zde jsme ji nazvali shark). Z této roury pak budeme data číst Wiresharkem, který už běží s právy obyčejného uživatele:
$ mkfifo shark # tshark -w - > shark $ wireshark -k -i shark
Kromě jiného to má výhodu v tom, že oba programy můžou běžet na různých počítačích – tshark pustíme třeba na vzdáleném směrovači nebo serveru a Wireshark hezky u sebe na desktopu (k přesměrování proudu dat použijeme SSH místo lokální pojmenované roury).
Jelikož dat přenášených po síti může být poměrně hodně, je dobré data filtrovat už na vstupu při zachytávání. Např. takto si vyfiltrujeme jen provoz na TCP portu 80 (HTTP):
tshark -f "tcp port 80" -w - > shark
Další možnosti filtrování jsou v GUI Wiresharku.
Takto vypadá HTTP komunikace zachycená Wiresharkem:
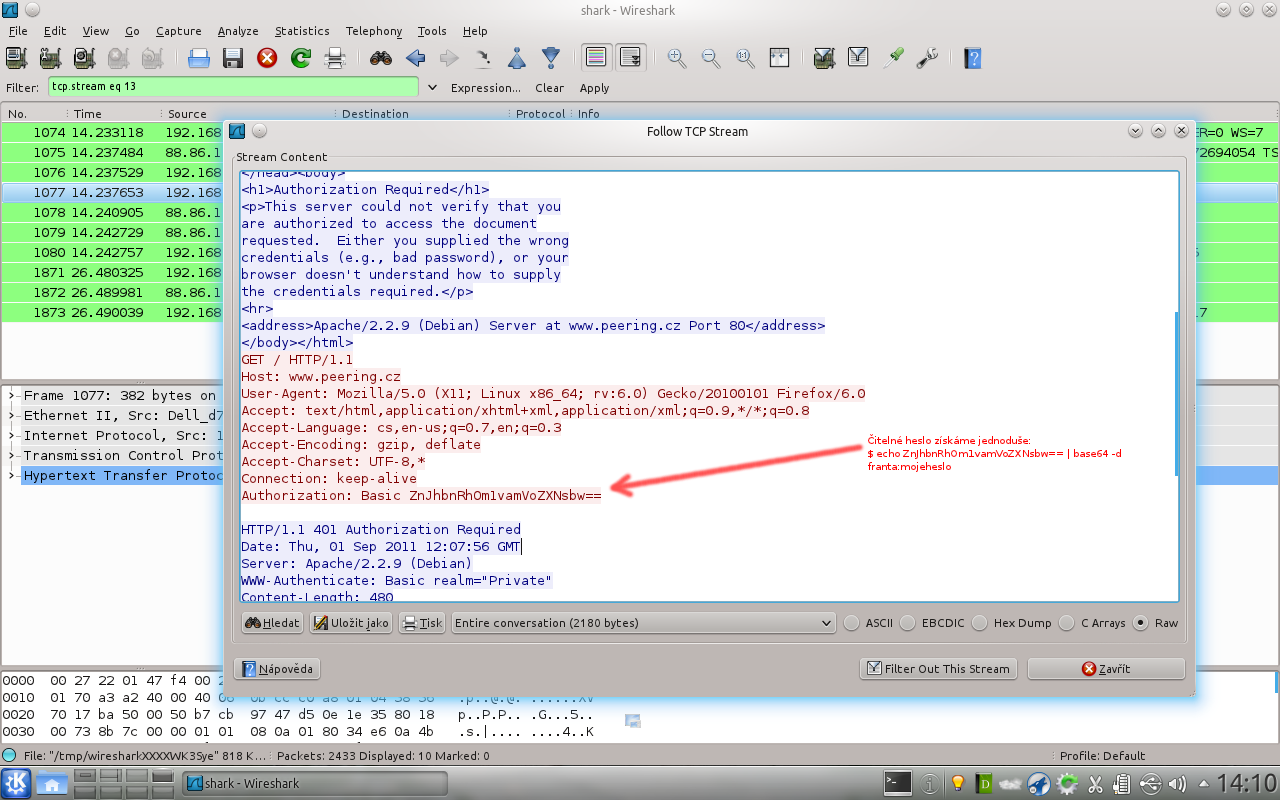
O Wiresharku by se dal napsat celý článek nebo seriál, proto se zatím spokojte s touto ochutnávkou.
Závěr
Protokol HTTP, který původně vznikl pro přenos hypertextových stránek, se dnes díky svému dobrému návrhu používá i k mnoha jiným úlohám (i když někdy můžeme hovořit o nadužívání). Je totiž zároveň jednoduchý i mocný – v dnešním článku jsme si ukázali např. možnosti vyjednávání vhodného formátu mezi klientem a serverem, efektivní datové přenosy (nepřenášení již přenesených dat), nebo náhodný přístup k částem souborů (vhodné pro audio/video záznamy nebo obnovu přerušeného stahování).
Odkazy a zdroje
- RFC 1945: Hypertext Transfer Protocol – HTTP/1.0
- RFC 2616: Hypertext Transfer Protocol – HTTP/1.1
- RFC 2617: HTTP Authentication: Basic and Digest Access Authentication
- RFC 6266: Use of the Content-Disposition Header Field in the HTTP
- List of HTTP header fields – Wikipedia
- Key Differences between HTTP/1.0 and HTTP/1.1 – hlavní rozdíly ve verzích protokolu 1.0 a 1.1
- ISO-639 – Kódy jazyků – seznam na Wikipedii.
- ISO-3166 – Kódy států – seznam na Wikipedii.
- Nginx: HttpGzipStaticModule – servírování předkomprimovaných souborů
- Socat – ultimátní síťový nástroj, lepší než telnet a netcat dohromady :-)
- GNU Readline – uživatečná knihovna pro příkazovou řádku
- Firebug – vývojářský nástroj pro Firefox
- Wireshark – analyzátor síťového provozu
František Kučera
Franta Kučera působí jako Java vývojář na volné noze. Programování je jeho koníčkem už od dětství. Kromě toho má rád Linux, relační SŘBD a XML.



Kdyz neni dostupny wireshark (tshark) tak stejne dobre poslouzi i tcpdump.
Vytratilo se tam CRLF hned v uvodnim prikladu…
GET /pokus.xhtml HTTP/1.0Host: example.com
Ano, chybí tam konec řádku. Prosím někoho z redakce o opravu, já už se k editaci nedostanu.
Jeste bych zduraznil, ze podle RFC popisujicich HTTP protokol se radky oddeluji dvojici znaku CR a LF.
Vetsina HTTP serveru toleruje i samotne LF, ktere se pouziva v Unixovych textovych souborech (a mozna i jine kombinace). Ale nektere to vyhodnoti jako syntaktickou chybu a zavrou spojeni.
Linuxovy „telnet“, ktery je pravdepodobne uveden v prikladu na zacatku, zrovna pri stisku klavesy Enter posle napsany radek a k nemu CR a LF (aspon v mem Debian Squeeze, overeno pred chvili tcpdumpem, ani jsem nemusel pouzit „set crlf“).
Ale ten priklad se „socat“ bude imho posilat pouze LF…
Normálně socat posílá jen LF, což tedy taky funguje :-), většinou. Ale abychom to měli správně podle RFC, můžeme napsat:
a socat pak posílá hezky CRLF
Opraveno, díky.
Opravte mne jestli se pletu, ale kdyz uz se do dotazu dava „Host:“ … nemelo by to byt spis HTTP/1.1 kdyz v 1.0 jeste nebyla?
1.0 je tam pro jednoduchost, aby se spojení hned ukončilo (
Connection closed by foreign host.) a nezůstalo tam viset (museli bychom použítConnection: close) nebo ho shodit z klienta pomocí Ctrl+C (případně ^] a Ctrl+D v telnetu).Hlavička
Host:je od 1.1 povinná a v 1.0 může a nemusí fungovat – tam platí, že:„However, new or experimental header fields may be given the semantics of request header fields if all parties in the communication recognize them to be request header fields.“
a často fungovat bude – rozdíl je pak hlavně v tom výchozím chování ohledně zavírání spojení: v 1.0 se zavře, pokud není uvedeno
Connection: Keep-Alivea v 1.1 se nezavře, pokud nedámeConnection: close.Aaha, diky.
Velmi pekny clanek, skvele a srozumitelne napsany. Dekuji.
Mimochodem – myslim, ze clanek o wiresharku by uvitalo hodne lidi:-), vcetne me.
Odkaz na „GNU Readline“ nefunguje, protože před názvem serveru vypadlo „http://“.
Děkuji za příjemný článek shrnující známé věci s odkazy na zdroje.
Opraveno, díky.
Všem autorům, kteří chtějí používat kódy jazyka, bych rád připomenul, že čeština má kód „cs“, nikoliv „cz“ (zato „CZ“ je kód pro ČR). Linuxoví uživatelé to asi budou znát (čeština je v locales „cs_CZ“), ale u spousty webů jsem to viděl špatně a z vlastní zkušenosti vím, že je pak často zatraceně těžké takové aplikace opravit.
Aktualna tema: kedy pouzit HTTP (synchornne/asynchronne), a kedy Websocket.
Až ho bude podporovat významná část uživatelů dané aplikace :-)
Ale jinak Websocket přišel trochu s křížkem po funuse, protože tenhle druh komunikace se do HTTP už podařilo dobastlit, resp. ohnout komunikaci tak, aby nebylo potřeba upravovat protokol (pořád je to formálně na principu požadavek/odpověď, akorát ta odpověď je hooodně dlouhá a přichází postupně).
se obávám, že se mýlíte… full duplex se nedá pomocí http simulovat… samozřejmě, pokud nepotřebujete full duplex, ale stačí vám např. long pooling, tak http použit můžete….
potřebujete full duplex a nepotřebujete, aby to běželo na „všech“ (áčkových) pohlížečích? Použijte WS. Nepotřebujete full duplex nebo potřebujete aby to běželo skoro všude? Budete muset použít http
Diky
Tak si testuju, co jsem se dneska dozvěděl a nějak se nemůžu domáknout toho Content-MD5.
Chápu tu správně, že z uvedených příkladů je
Range: bytes=500-999hlavička požadavku, kdežto
Content-MD5: Q2hlY2sgSW50ZWdyaXR5IQ==je hlavička odpovědi?
V tom případě, dá se
Content-MD5nějak vyžádat v požadavku? Protože nevím o žádném serveru, který by takovou hlavičku sám od sebe posílal.Content-MD5může posílat i klient, pokud posílá tělo požadavku (při POST). Vynutit se nedá a kvůli výkonu se moc nepoužívá.jj, např. v Apachovi jde úplně vypnout nebo úplně zapnout, nic mezi tím (posílat volitelně) a ve výchozím stavu je to vypnuté. Ona už jen představa, že si uživatel vyžádá stažení nějakého CD/DVD obrazu a nejdřív se bude muset spočítat MD5 ze stovek MB dat a pak se teprve můžou poslat hlavičky a vlastní data…
Chtělo by to modul, který by ten hash nepočítal pokaždé znova, ale bral ho např. z rozšířených atributů nebo z pomocného souboru (*.md5). Podobně jako to dělá ten Nginx s gzipováním (.gz soubor může být připravený předem a nekomprimuje se pokaždé znova).
Zapnout generování Content-MD5 se dá v nějakém bezpečném prostředí (menší soubory, interní systémy, API, které z těch hashů bude čerpat nějaké výhody…), ale i tak by bylo vhodnější to spočítat jen jednou (a pak jen kontrolovat, jestli se změnilo datum/velikost souboru).
pekny ozav v kusku pekny clanok, blahozelam autorovy, dakujem
Jak řekl Jan Lehnardt na IRC: haha, I’m sitting in an „“HTTP Architecture“ session, and all the two speakers do is tell the audience how CouchDB gets it all right. :-)
A co tím chtěl básník říct? :-)