Přístupnost dynamických webových aplikací – úvod

Asistivní technologie, nové verze prohlížečů a pracovní skupina WAI u W3C pomalu boří další bariéru na webu. I dynamické webové aplikace už v poměrně blízké budoucnosti mohou být bez problémů přístupné např. pro uživatele screenreaderů. Pojďme se podívat, jaké jsou hlavní překážky RIA aplikací a jak může handicapovaným uživatelům pomoci nová specifikace WAI-ARIA a její použití na webu.
Seriál: Přístupnost dynamických webových aplikací (4 díly)
- Přístupnost dynamických webových aplikací – úvod 6. 5. 2009
- Přístupnost RIA – strukturování dokumentu a přístupnost z klávesnice 10. 6. 2009
- Přístupnost RIA – dynamické změny obsahu 10. 7. 2009
- Přístupnost RIA – přístupnost widgetů 21. 9. 2009
Nálepky:
Nástup a rozvoj RIA s sebou přinesl mimo jiné i nové problémy a výzvy v oblasti přístupnosti. Zatímco zpřístupnit čisté HTML dnes zpravidla není při dodržování pravidel přístupnosti problém, u RIA je to trošku složitější.„Web 1.0“ byl postaven na konceptu statického obsahu, který se měnil stránku od stránky. Původní pravidla přístupnosti (například WCAG 1.0) byla napsána tak, aby odpovídala tomuto způsobu zobrazování obsahu.
Web 2.0 zahrnuje tvorbu mnohem komplikovanějších uživatelských rozhraní, která získávají informace dynamicky z různých informačních zdrojů, V reálu to tedy znamená, že stávající asistivní technologie si s dynamickými webovými aplikacemi zpravidla neporadí tak, aby je mohli bez obtíží používat i uživatelé screenreaderů.
Jaké jsou hlavní překážky dynamických webových aplikací?
- Problematické jsou situace, kdy při události (ať už nastane automaticky nebo jako výsledek interakce uživatele) není znovunačtena celá stránka, ale novým obsahem je nahrazena jen její část. Odečítač obrazovky je sice schopen změny identifikovat, ovšem neexistuje obecný postup, jak uživatele o těchto změnách informovat (odečítač neumí změněnou oblast implicitně pojmenovat), nehledě na to, že provedená změna může být nedůležitá a informace o ní může uživatele spíše obtěžovat, než mu být k užitku (příkladem takové nedůležité změny může být obnova reklamního banneru). V současnosti u nás běžně používané odečítače umí identifikovat a pojmenovat na základě titulku jen změny v rámech (iframe).
- Ovladatelnost z klávesnice. Protože webová aplikace si žádá sofistikovanější ovládání, nevystačí si jen s klasickými odkazy a potřebuje i jiné elementy k zobrazení těchto ovládacích prvků. Ty ale často při své aktivaci vyvolávají události voláním skriptu. Odkazy tedy nevyvolávají odskok na cílové místo v pravém slova smyslu, což uživatele neseznámené s prací v takové aplikaci může značně zmást. Častější je ovšem využití jiných elementů, jakými je například značka <div>, která je z hlediska skriptování nejtvárnější a která také mimo jiné postrádá jakoukoliv sémantickou informaci o svém obsahu. Události jsou potom asociovány s elementem pomocí atributu onclick, v horším případě onmouseover (událost přejetí myší nemá ekvivalent v ovládání z klávesnice). Fakt, že na element je navěšena událost při kliknutí (onclick), je schopen odečítač odhalit a nabídnout možnost simulace kliknutí na toto místo. Protože však takovému elementu není dán fokus v pravém slova smyslu, jde o metodu, jež nemusí fungovat stoprocentně. Z nemožnosti udělit elementu fokus vyplývá, že ovládací prvek tvořený elementem <div> či jiným, určeným pouze pro prezentaci, není zahrnut do tab order (klávesou tabulátor jsou ve všech prohlížečích dosažitelné pouze odkazy a formulářové prvky).
- Webová aplikace dělí své rozhraní na několik obsahově specifických sekcí (navigační část, hlavní obsah, vyhledávání atp.), pro něž neexistuje jednotný způsob vyznačení v kódu. Dnes je již obvyklé používat systém navigačních odkazů na počátku stránky a uvozování jednotlivých sekcí pomocnými (skrytými) nadpisy, nicméně webová aplikace je často vyvíjena ve frameworcích a sestavována z widgetů, které nemají sémantickou stránku přizpůsobenu obsahu, což opět vychází z nasazení skriptování (masivní generování obsahu skripty).
RIA jsou proto problematické hlavně pro uživatele, kteří nejsou schopni některou z výše uvedených překážek obejít (jedná se například o uživatele screenreaderů či uživatele, kteří ovládají web pouze z klávesnice).
Existuje řešení?
Naštěstí ano. Pokud mají být výše uvedené problémy řešeny systematicky, je nutné mít nový přístupnostní framework, který zajistí přístup k informacím na Web 2.0 webech. Takový framework už dnes existuje a schyluje se k vydání jeho finální verze. Jmenuje se WAI-ARIA a jedná se o specifikaci W3C, která si klade za cíl zpřístupnit dynamicky tvořený obsah.
ARIA poskytuje:
- přístupné interaktivní ovládací prvky (stromové seznamy, drag & drop, posuvníky atp.);
- možnost přiřadit jednotlivým částem stránky sémantickou informaci (tzn. autor může definovat, která část stránky je navigace, vyhledávání, hlavní obsah atp.);
- oblasti, které mohou být dynamicky obnovovány (ve WAI-ARIA jsou nazývány jako „živé oblasti“ – live regions);
- lepší podporu pro přístupnost z klávesnice.
Na straně klienta je pak třeba, aby tyto funkcionality dokázaly využívat prohlížeče a asistivní technologie. Z prohlížečů podporují ARIA Firefox od verze 1.5, Opera od verze 9.5, Internet Explorer verze 8 a WebKit. Z asistivních technologií pak JAWS 7 a vyšší (nejlepší podpora je ve verzi 10), Windows-Eyes 5.5 a vyšší, NVDA, ZoomText 9 a vyšší a FireVox. Podpora ARIA není ještě všudypřítomná a komplexní, ale s každou novou verzí asistivní technologie se výrazně zlepšuje (u nižších verzí asistivních technologií se jednalo spíše o dílčí podporu některých situací – například vylepšené zjišťování dynamických změn stránky u JAWS 7 bez návaznosti na ARIA, protože v té době ještě tato specifikace neexistovala).

Schéma pochází ze specifikace WAI-ARIA 1.0
Jak WAI-ARIA funguje v praxi?
Závěrem tohoto článku si ukažme, že zavedení ARIA do praxe není nikterak složité. Pokud chceme RIA zpřístupnit, je třeba stránku v XHTML rozšířit o jmenný prostor atributů ARIA, které popisují struktury důležité pro přístupnost dynamických webových aplikací. V případě HTML můžeme používat ARIA atributy s prefixem „aria-“, tato možnost je ovšem validní až od HTML5:
<html lang="en" xml:lang="en"
xmlns="http://www.w3.org/1999/xhtml"
xmlns:aaa="http://www.w3.org/2005/07/aaa">
...
</html> Pokud například chceme vytvořit sledovanou oblast (tzv. live region), postupujeme následovně.
XHTML:
<div id="live-news" aaa:live="notify" title="novinky">
...
</div> HTML:
<div id="live-news" aria-live="notify" title="novinky">
...
</div> Daná oblast je od této chvíle sledována a pokud je její obsah změněn, bude uživatel o této změně informován.
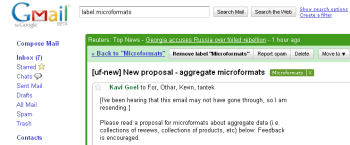
To, jak ARIA již pomáhá v praxi, si můžete vyzkoušet za pomoci FireVoxu (open source hlasová čtečka pro Firefox) například u formuláře pro přihlášení do služby WebVisum či AJAXové výsledkové tabuli. Podporu ARIA už mají i některé aplikace Googlu, například GMail či Google Reader.
Příště si projdeme další praktické příklady a vyzkoušíme, jak si s ARIA poradí nejnovější verze screenreaderu JAWS 10, u které už by měla být podpora ARIA na solidní úrovni.
Radek Pavlíček
Radek vystudoval informatiku na Fakultě informatiky Masarykovy univerzity v Brně. Od roku 1998 se věnuje přístupnosti a speciální informatice pro lidi s těžkým postižením zraku.


presne taketo clanky treba. dufam ze sa dockame aj nejakej video? ukazky ako funguje specialny hardware ktory pouzivaju slepci. diky
O takovém videu uvažujeme. Zatím doporučiji projít archiv naší rubriky o přístupnosti http://zdrojak.root.cz/r/pristupnost/ kde lze nalézt řadu materiálů popisujích, jak vypadá web z pohledu handicapovaných uživatelů a to včetně několika videí.
Chtěl bych se zeptat, jak to pak je s validací stránky. W3C validátor mi tvrdí, že attribute "aaa:live" is not a valid attribute (což podle specifikace xhtml je zřejmě správně).
Do jaké míry je pak takový dokument stále ještě validní?
Díky.
To je pomerne kuriozni situace. Jedna se jiste validni XML dokument, kazdopadne o nevalidni XHTML1 dokument, ktere ackoliv jmenne prostory podporuje, ve specifikaci dokumenty pouzivajici jmenne prostory (resp. jinne jmenne prostory nez XHTML) nepovazuje ve striktni podobe za validni, viz http://www.w3.org/TR/xhtml1/#normative
Zkuste si zvalidovat ukazkove priklady se jmennymi prostory z vlastni XHTML1 specifikace, nepodari se vam to. Proc tomu tak je nevysvetlim, nikdy jsem myslenkove pochody tvurcu XHTML moc nechapal, ale mozna se tu zastavi Jirka Kosek a nabidne nejake vysvetleni.
Pokud je mi znamo, tak v tuhle chcili nelze vytvorit W3C validni XHTML dokument pouzivajici jmenne prostory – hledal jsem cestu a nenasel, klidne me opravte – (to se melo puvodne zmenit az v XHTML2, tj. zmeni se to az v XHTML5). Vyjimkou je XHTML1.1, ktere pomoci "finty" umoznuje validni XHTML pouzivajici MathML a SVG (mkrnete se na podporovane typy dokumentu ve validatoru, najdete je v nem).
Kazdopadne tohle se tyka opravdu jen W3C validatoru. V realu neni zadny duvod, aby prohlizec nepodporoval jmenne prostory v XHTML, pokud jej jiz zpracovava jako XML dokument (zcela jiste je v takovem pripade podporovat bude).
Pokud je nekdo na validaci z nejakych duvodu vazan, je tu stale reseni, ktere se uz pomerne bezne pouziva, tj. napsat validni dokument a teprve pomoci JavaScriptu pridat ony spravne, ale nevalidni zalezitosti (tu pujde pouzivat i zde v pripade ARIA). Jedna se o jakesi obchazeni zakonu, ale pohybujete se v takovem pripade v legalni zone (byt sede), nikoliv v cerne zone.
Specifikace XHTML 1.0 je napsaná blbě.
Nicméně řešení problému je jednoduché, nepoužívejte na začátku XHTML dokumentu DOCTYPE a tím se vám otevře cesta pro používání dalších jmenných prostorů včetně ARIA. Dokument pak sice nebude "strictly conforming", ale to nikoho nezajímá.
Pro validaci pak můžete použít třeba http://validator.nu/
Lze použít i http://relaxed.vse.cz/ (ale většinou je server přetížený a neodpovídá), který umí v XHTML ignorovat atributy z ciczích jmenných prostorů.
To mě taky napadlo, jenže s vynecháím DOCTYPE browsery začnou padat do quirks modu. Takže nezbývá zřejmě nic jiného, než jim o typu dokumentu lhát.
Jestli nechcete, aby padaly do quirks, můžete použít něco jako
<!DOCTYPE html>
Důležité je, aby !DOCTYPE neukazovalo na DTD, které definuje pevnou sadu elementů a nejde používat další elementy/atributy z jiných jmenných prostorů.
A ještě jeden dotaz — ony vám prohlížeče padají do quirks, když XHTML posíláte jako application/xml+xhtml nebo text/xml?
Máte pravdu, tohle jsem přehlídl. Opera i FF jedou ve standardním modu i bez DOCTYPE, pokud se jim pošle i správný content-type.
Tohle jsem taky nikdy nepochopil: Proč byl v XML ponechán institut DTD, když bylo od začátku jasné, že nebude slučitelný se jmennými prostory?
Jmenné prostory nejsou v XML od začátku, je to nadstavba nad XML.
Navíc za jistých okolností jsou jmenné prostory a DTD slučitelné, stačí používat stejné prefixy jaké předpokládá DTD.