Kompletní průvodce po CouchDB – VI – Využití pohledů

Základní součástí dokumentové databáze CouchDB jsou takzvané pohledy (views). Jedná se o velmi mocný nástroj založený na algoritmu Map-Reduce, pomocí kterého přistupujeme k uloženým datům, pomocí kterého můžeme zpracovávat jen vybrané dokumenty, řadit je a vyhledávat dle určitých kritérií a počítat s nimi.
Seriál: Kompletní průvodce po CouchDB (6 dílů)
- Kompletní průvodce po CouchDB – I 11. 4. 2011
- Kompletní průvodce po CouchDB – II 18. 4. 2011
- Kompletní průvodce po CouchDB – III 26. 4. 2011
- Kompletní průvodce po CouchDB – IV 2. 5. 2011
- Kompletní průvodce po CouchDB – V – Návrhové dokumenty 30. 5. 2011
- Kompletní průvodce po CouchDB – VI – Využití pohledů 27. 6. 2011
Pohledy (Views) jsou užitečné v celé řadě případů:
- Filtrování dokumentů v databázi a hledání záznamů pro další zpracování.
- Vybrání dat z dokumentů a prezentování v určitém pořadí.
- Vytváření efektivních indexů pro nalezení dokumentů podle nejrůznějších hodnot či struktur v nich uložených.
- Použití těchto indexů k vyjádření vztahu mezi dokumenty.
- V neposlední řadě můžete pomocí pohledů provádět nejrůznější výpočty s daty v dokumentech. Pohledem můžete například odpovědět na otázku „Jaké byly výdaje vaší společnosti za poslední týden, měsíc, rok?“
Co je pohled?
Pojďme si projít různé případy použití. První příklad získává data z dokumentů v určitém pořadí pro další použití. Na titulní stránce budeme chtít seznam blogpostů seřazený podle dat. V příkladech budeme pracovat se sadou zápisků:
{
"_id":"biking",
"_rev":"AE19EBC7654",
"title":"Biking",
"body":"My biggest hobby is mountainbiking. The other day...",
"date":"2009/01/30 18:04:11"
}
{
"_id":"bought-a-cat",
"_rev":"4A3BBEE711",
"title":"Bought a Cat",
"body":"I went to the the pet store earlier and brought home a little kitty...",
"date":"2009/02/17 21:13:39"
}
{
"_id":"hello-world",
"_rev":"43FBA4E7AB",
"title":"Hello World",
"body":"Well hello and welcome to my new blog...",
"date":"2009/01/15 15:52:20"
}
Tři nám k ukázce stačí. Všimněte si, že dokumenty jsou setříděné podle "_id", a v tomto pořadí jsou uložené v databázi. Teď si definujeme pohled. V kapitole III jsme si ukazovali, jak vytvořit pohled pomocí Futonu, administrátorské konzole pro CouchDB. Ukažme si, zatím bez vysvětlení, jednoduchý pohled:
function(doc) {
if(doc.date && doc.title) {
emit(doc.date, doc.title);
}
}
Toto je mapovací funkce, napsaná v JavaScriptu. Mapovací funkce poskytujete CouchDB jako řetězce, uložené v poli views návrhového dokumentu. Nespouštíte je přímo. Místo toho když položíte pohledu dotaz, CouchDB vezme tuto funkci a spustí ji pro každý dokument v databázi, ve které jste pohled definovali. Vy se dotazujete pohledů a tím získáváte výsledky pohledu.
Každá mapovací funkce má jeden parametr doc. V něm je předán jeden každý dokument (nezapomínejme, že dokumenty jsou JSON objekty). Naše mapovací funkce zkontroluje, jestli dokument má atributy date a title – naštěstí všechny naše dokumenty je mají – a pak zavolá zabudovanou funkci emit(), které předá tyto dva atributy jako argumenty.
Funkce emit() vyžaduje vždy dva argumenty: první je key, klíč, a druhý hodnota, value. Funkce emit(key, value) zapisuje záznam do výsledků pohledu. Ještě jedna věc: funkci emit() můžete z mapovací funkce zavolat víckrát a vytvořit tak víc položek do seznamu výsledků pohledu z jednoho dokumentu.
CouchDB vezme cokoli, co předáte funkci emit(), a uloží to do seznamu (viz Tabulka 1, “View results”). Každý řádek tohoto seznamu obsahuje položky key a value. Důležité je, že seznam je řazen podle klíče key (v našem případě podle doc.date). Tato vlastnost je nejdůležitější vlastností výsledků pohledu. Budeme ji často využívat k vytvoření zajímavých věcí.
"2009/01/15 15:52:20" |
"Hello World" |
"2009/01/30 18:04:11" |
"Biking" |
"2009/02/17 21:13:39" |
"Bought a Cat" |
Jestliže jste četli předchozí pasáže důkladně, všimli jste si jedné věci: „když položíte pohledu dotaz, CouchDB vezme tuto funkci a spustí ji pro každý dokument v databázi“ Když máte spoustu dokumentů, zabere to spoustu času a možná pochybujete o efektivitě takového přístupu. Ano, mohlo by to zpomalit, ale CouchDB je navržena tak, aby se vyhnula práci navíc. Ve skutečnosti jsou procházeny všechny dokumenty jen při prvním položení dotazu. Pokud se následně nějaký dokument změní či přidá, je spuštěna mapovací funkce pouze pro tento dokument.
Výsledky pohledu jsou uloženy v B-stromu, stejně jako běžné dokumenty. B-stromy s výsledky pohledů jsou uloženy ve vlastním souboru, takže není problém zvyšovat výkon databáze např. jejich přesunem na samostatný disk. B-strom umožňuje velmi rychlé hledání záznamů podle klíčů, stejně jako extrakci záznamů s klíčem v daném rozsahu. V našem příkladu dokáže pohled odpovědět na všechny otázky, kde figuruje čas: „Dej mi všechny blogposty za poslední týden“ nebo „poslední měsíc“ nebo „tento rok“. Šikovné. Více se dočtete v příloze F – síla B-stromů.
Když se dotazujeme pohledu, dostaneme seznam všech dokumentů, setříděný podle času. Každý řádek obsahuje také titulek příspěvku, pomocí kterého můžeme rekonstruovat odkaz. Na obrázku 1 je grafická reprezentace výsledku. V podobě JSON obsahuje ještě nějaká metadata navíc:
{
"total_rows": 3,
"offset": 0,
"rows": [
{
"key": "2009/01/15 15:52:20",
"id": "hello-world",
"value": "Hello World"
},
{
"key": "2009/02/17 21:13:39",
"id": "bought-a-cat",
"value": "Bought a Cat"
},
{
"key": "2009/01/30 18:04:11",
"id": "biking",
"value": "Biking"
}
]
}
Ve skutečnosti není výsledek takhle hezky formátovaný a neobsahuje žádné odsazovací mezery ani nové řádky, ale takto je pro nás čitelnější. A kde se vzal ve výsledcích prvek "id"? Vždyť jsme ho tam nezadávali. Je tam správně, jen jsme o něm zatím nehovořili, aby byl výklad jednodušší. CouchDB totiž automaticky vkládá ID dokumentu k záznamům, které z tohoto dokumentu vzniknou. Tuhle vlastnost využijeme později.
Efektivní procházení
Pojďme se podívat na druhý příklad použití pohledů: “Vytváření efektivních indexů pro nalezení dokumentů podle nejrůznějších hodnot či struktur v nich uložených.” Už jsme si vysvětlili efektivitu indexování, ale pár detailů jsme přeskočili. Teď je vhodná chvíle vrátit se k přeskočeným pasážím a vysvětlit si mapovací funkce podrobněji.
Nejprve se vraťme k B-stromům! Vysvětlili jsme si, že B-strom, který obsahuje výsledky pohledu setříděné podle hodnoty key, se vytváří pouze jednou, při prvním dotazu na tento pohled, a všechny další dotazy přistupují k už vytvořeným výsledkům namísto toho, aby se vše spouštělo znovu. Co se ale stane, když nějaký dokument přidáme, změníme, smažeme? To je snadné: CouchDB je natolik chytrá databáze, aby našla řádky v sadě výsledků, které se vztahují k danému dokumentu. Označí je jako neplatné, takže se už ve výsledcích neobjevují. Pokud byl dokument smazán, je to OK – B-strom odráží aktuální stav databáze. Při změně dokumentu je nová verze předhozena mapovací funkci a výsledné záznamy jsou umístěny na správná místa v B-stromu. Nový dokument je obsloužen stejným způsobem.
Ještě přidejme jeden střípek do diskuse o efektivitě: obvykle bývá mezi dotazy na pohledy změněno víc dokumentů. Výše popsaný mechanismus je aplikován na všechny dokumenty, které se změnily od posledního dotazu na pohled, a to najednou při dalším dotazu. Výsledkem je další zrychlení práce a lepší využití prostředků.
Najdi jeden
Půjdeme ještě víc do hloubky. Říkáme „nalezení dokumentů podle nejrůznějších hodnot či struktur v nich uložených“. Už jsme si vysvětlili, jak určit hodnotu, podle které budou výsledky řazené (pole date). Stejný mechanismus využijeme i pro rychlé vyhledání. URI, kterým pokládáme dotaz pohledu, je /database/_design/designdocname/_view/viewname. Toto URI obsahuje seznam všech řádků výsledku. Máme v databázi jen tři dokumenty, takže to ještě jde, ale s tisíci dokumentů bude tento seznam dlouhý. Proto můžete přidat parametry pohledu k tomuto URI a omezit tak seznam výsledků. Řekněme že znáte datum blogpostu. Pokud chcete nalézt konkrétní záznam, můžete použít např. /blog/_design/docs/_view/by_date?key="2009/01/30 18:04:11" a získáte zápisek “Biking”. Vzpomeňte si, že jako parametr key můžete předat funkci emit() cokoli. Cokoli tam zadáte, to můžete později snadno a rychle najít.
Pokud má víc řádků ve výsledku stejný klíč (například v pohledu, kde budeme třídit podle jména autora), vrátí takový dotaz více záznamů.
Najít víc
Mluvili jsme o “získání záznamů za poslední měsíc.” Jestliže je teď červen, můžeme to snadno zařídit zadáním /blog/_design/docs/_view/by_date?startkey="2011/05/01 00:00:00"&endkey="2011/06/00 00:00:00". Parametry startkey a endkey specifikují rozsah, v němž se budou nacházet klíče výsledků.
Abychom si udělali hledání o něco jednodušší a připravili si databázi na další příklady, změníme formát data. Namísto řetězce použijeme pole, kde jednotlivé položky budou části data a času v sestupném pořadí důležitosti. Zní to divoce, ale je to jednoduché. Namísto:
{
"date": "2009/01/31 00:00:00"
}
použijeme:
"date": [2009, 1, 31, 0, 0, 0]
Naše mapovací funkce může zůstat tak jak byla, ale vrácené výsledky budou trochu jiné. Viz Tabulka 2, “Nové výsledky pohledu”.
| Key | Value |
|---|---|
[2009, 1, 15, 15, 52, 20] |
"Hello World" |
[2009, 2, 17, 21, 13, 39] |
"Biking" |
[2009, 1, 30, 18, 4, 11] |
"Bought a Cat" |
Naše dotazy se změní na /blog/_design/docs/_view/by_date?key=[2009, 1, 1, 0, 0, 0] a /blog/_design/docs/_view/by_date?key=[2009, 01, 31, 0, 0, 0]. Jde o změnu syntaxe, nikoli o změnu významu. Na druhou stranu to ukazuje sílu pohledů. Klíče nemusí být jen skaláry, řetězce a čísla, ale můžeme použít jakékoli JSON konstrukce. Řekněme, že do dokumentů přidáme seznam tagů a chceme vypsat všechny tagy, ale nezajímají nás dokumenty, co jsou bez tagů.
{
...
tags: ["cool", "freak", "plankton"],
...
}
{
...
tags: [],
...
}
function(doc) {
if(doc.tags.length > 0) {
for(var idx in doc.tags) {
emit(doc.tags[idx], null);
}
}
}
Zde vidíme několik nových věcí. Lze použít i podmínky ( if(doc.tags.length > 0)) namísto pouhého vypsání hodnoty. Zároveň je tu vidět, jak mapovací funkce volá emit() vícenásobně. A konečně vidíte, že lze předat null jako hodnotu parametru value. Totéž platí i pro parametr key. Ukážeme si, k čemu to může být dobré.
Obrácené řazení výsledků
Pokud chceme získat výsledky v opačném pořadí, použijeme parametr descending=true. Když zároveň použijeme parametr startkey, zjistíme, že CouchDB vrací jiné výsledky, nebo dokonce žádné. Co s tím?
Pokud pochopíte, jak tyto parametry pracují, bude řešení velmi jednoduché. Výsledky pohledu jsou uložené ve stromové struktuře kvůli rychlému vyhledávání. Kdykoli je vyvolán pohled, provede CouchDB tyto operace:
- Začne číst od prvního záznamu, nebo od záznamu určeného parametrem
startkey, pokud je uveden. - Vrátí řádek po řádku, dokud nedojde na konec výsledků nebo k záznamu odpovídajícímu parametru
endkey.
Pokud uvedete descending=true, je obráceno pořadí čtení výsledků, nikoli pořadí výsledků samotných. Následně jsou provedeny výše citované operace.
Řekněme že výsledky vypadají takto:
| Key | Value |
|---|---|
0 |
"foo" |
1 |
"bar" |
2 |
"baz" |
Položíme dotaz s parametry: ?startkey=1&descending=true. Co CouchDB udělá? Viz krok 1: skočí na záznam startkey, což je řádek s klíčem 1, a začne číst záznamy v obráceném pořadí, dokud nenarazí na konec seznamu. Výsledek tedy bude:
| Key | Value |
|---|---|
1 |
"bar" |
0 |
"foo" |
Velmi pravděpodobně to je to, co jste nechtěli. Pokud chcete získat řádky 1 a 2 v obráceném pořadí, musíte zaměnit startkey za endkey: endkey=1&descending=true:
| Key | Value |
|---|---|
2 |
"baz" |
1 |
"bar" |
To už vypadá lépe. CouchDB začne číst od posledního záznamu a pokračuje k začátku, dokud nenarazí na záznam endkey.
Pohled pro získání komentářů k článkům
Použijeme zde klíč v podobě pole, který využijeme pro parametr group_level funkce reduce. Pohledy jsou ukládány ve struktuře, zvané B-strom. Díky způsobu strukturování B-stromu si můžeme ukládat mezivýsledky reduce funkcí do uzlů stromu, takže dotazy s reduce mohou být vypočítány z těchto mezivýsledků v logaritmickém čase.
V blogové aplikaci použijeme group_level dotazy ke zjištění počtu komentářů u jednotlivých zápisků nebo u všech zápisků, k čemuž nám postačí jeden pohled volaný různými způsoby. Předpokládejme, že klíče výsledků pohledu jsou pole a hodnota je vždy 1:
["a","b","c"] ["a","b","e"] ["a","c","m"] ["b","a","c"] ["b","a","g"]
Reduce funkce:
function(keys, values, rereduce) {
return sum(values)
}
vrátí celkový počet záznamů v určeném rozsahu. Pomocí startkey=["a","b"]&endkey=["b"] (což odpovídá prvním třem záznamům) bude výsledek rovný třem. Takovýmto způsobem jsme spočítali řádky. Pokud chcete spočítat řádky bez ohledu na to, jaká je u nich hodnota, můžete využít parametru rereduce:
function(keys, values, rereduce) {
if (rereduce) {
return sum(values);
} else {
return values.length;
}
}

Figure 1. Comments map function
Takto vypadá náš pohled s reduce, použitý v ukázkové aplikaci, když pomocí map vypíšeme přímo komentář, což je užitečnější než pouhá jednička stále dokola. Vyplatí se strávit nějaký čas hraním si s funkcemi map a reduce. Můžete k tomu použít Futon, ale v něm nelze získat plný přístup ke všem query parametrům. Lepší způsob je napsat si vlastní testovací kód v oblíbeném jazyce, pak mnohem lépe vyniknou výhody inkrementálního MapReduce systému, použitého v CouchDB.
Pomocí parametru group_level spustíme reduce vícekrát, jednou pro každou skupinu výsledků, která se objeví na dané úrovni. Ukažme si výsledky výše, sdružené na úrovni 1:
["a"] 3 ["b"] 2
A s group_level=2:
["a","b"] 2 ["a","c"] 1 ["b","a"] 2
Použití parametru group=true vyvolá chování, odpovídající group_level=Exact, tedy sdružení pouze duplikovaných klíčů. Ve výše uvedeném případě by výsledek pro všechny položky byl 1.
Reduce/Rereduce
Stručně jsme zmínili parametr rereduce u reduce funkcí. V této části si popíšeme, k čemu slouží. Nejprve si ukážeme, jak pracuje vyhledávání v B-stromu. Důvod existence a použití parametru rereduce je úzce svázáno s tím, jak fungují indexy v B-stromu.
Předpokládejme, že výsledkem nějaké map funkce je takováto struktura (řekněme že jde o jídelní lístek a my pracujeme se zeměmi původu receptů):
"afrikan", 1 "afrikan", 1 "chinese", 1 "chinese", 1 "chinese", 1 "chinese", 1 "french", 1 "italian", 1 "italian", 1 "spanish", 1 "vietnamese", 1 "vietnamese", 1
Pokud chceme spočítat, kolik jídel pochází z jednotlivých oblastí, můžeme použít jednoduchou reduce funkci, kterou jsme si již ukazovali:
function(keys, values, rereduce) {
return sum(values);
}
Následující obrázek ukazuje, jak je procházen B-strom. Názvy zemí jsme si zkrátili.
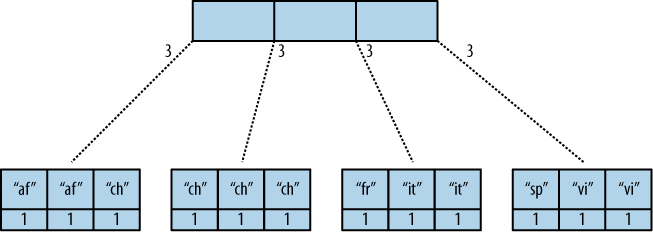
Začínáme pohledem na každý element každého uzlu, počínaje zleva. Kdykoli zjistíme poduzel, sestoupíme o úroveň dolů a čteme elementy v poduzlu. Když takto projdeme celý strom, máme hotovo.
Můžete vidět, že CouchDB ukládá klíče i hodnoty v každém koncovém uzlu. V našem případě je to vždy 1, ale můžete mít výsledky, kde jsou hodnoty různé. Co je důležité: CouchDB předává všechny elementy z uzlu funkci reduce (a parametr rereduce je false) a ukládá si výsledky do rodičovského uzlu, k hraně vedoucí k poduzlu. V našem případě má každá hrana hodnotu 3, která reprezentuje hodnotu funkce reduce pro každý poduzel, k němuž daná hrana vede.
Ve skutečnosti obsahují uzly víc než 1600 elementů. CouchDB počítá výsledky pro všechny elementy vícenásobnými iteracemi, nepočítá vše najednou, to by představovalo neúměrnou zátěž.
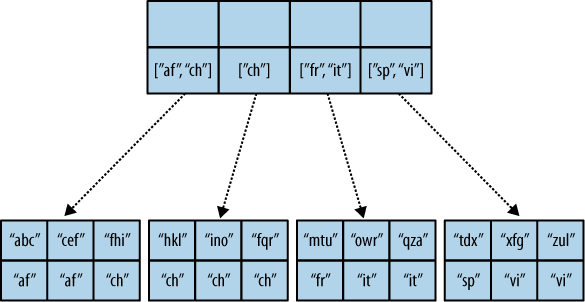
Pojďme se podívat, co se stane, když spustíme dotaz. Budeme chtít vědět, kolik je na jídelním lístku čínských jídel ( "chinese"). Dotaz bude prostý: ?key="chinese". Viz následující obrázek:

CouchDB zjistí, že všechny položky v jednom poduzlu mají klíč „chinese“. To znamená, že lze použít přímo hodnotu dané hrany – 3. Zjistí, že u uzlu nalevo je sada hodnot, kde splňují podmínku jen některé. Pro ni spustí znovu funkci reduce s parametrem rereduce nastaveným na true.
Výsledek reduce funkce je roven součtu 3 + 1. Další příklad ukazuje pseudokód, který odpovídá poslednímu volání funkce reduce.
function(null, [3, 1], true) {
return sum([3, 1]);
}
Teď jsme si řekli, že funkce reduce by měla redukovat hodnoty. Pokud se podíváte na B-strom, mělo by být jasné, co se stane, když nebudete hodnoty redukovat. Předpokládejme následující výsledek funkce map a následující funkci reduce. Tentokrát se budeme snažit získat všechny unikátní země původu:
"abc", "afrikan" "cef", "afrikan" "fhi", "chinese" "hkl", "chinese" "ino", "chinese" "lqr", "chinese" "mtu", "french" "owx", "italian" "qza", "italian" "tdx", "spanish" "xfg", "vietnamese" "zul", "vietnamese"
Nestaráme se o hodnotu klíčů, pouze o výpis všech zemí původu. Naše funkce reduce odstraní duplicity – podívejte se na její příklad, který je záměrně napsaný špatně (tedy takto to nedělejte)
function(keys, values, rereduce) {
var unique_labels = {};
values.forEach(function(label) {
if(!unique_labels[label]) {
unique_labels[label] = true;
}
});
return unique_labels;
}
Toto vede k přeplnění indexového stromu.
Doufáme, že máte představu o tom, co se stane. Způsob, jakým B-strom ukládá data vede k tomu, že pokud svá data neredukujete, bude výsledkem nesmírné množství mezidat, jejichž počet a objem poroste lineárně, ne-li rychleji než počet řádků výsledku.
CouchDB i v takovém případě spočítá výsledek, ale jen pro pohledy s malým počtem řádků výsledku. Cokoli většího zpomalí databázi. CouchDB od verze 0.10.0 proto vyhazuje chybu, pokud funkce reduce neredukuje svá vstupní data.
V Kapitole 21, Kuchařka pohledů pro SQL mistry naleznete příklad toho, jak spočítat seznamy jedinečných hodnot pomocí pohledů.
Co jsme se naučili?
- Pokud nepoužíváte pole key ve funkci map, pravděpodobně to děláte špatně.
- Pokud se pokoušíte vytvořit seznam jedinečných hodnot ve funkci reduce, děláte to pravděpodobně špatně.
- Pokud neredukujete hodnoty na jednoduchou skalární veličinu nebo na malé pole či objekt s pevným počtem skalárních veličin, děláte to pravděpodobně špatně.
Shrnutí
Mapovací funkce jsou funkce bez postranních efektů, které přijímají dokument jako argument a vrací dvojici klíč-hodnota. CouchDB si tyto dvojice hodnot ukládá do řazeného B-stromu, takže k vrácení určitého záznamu nebo k procházení určitého rozsahu lze realizovat s malými nároky na paměť a výpočetní kapacitu. Vytvoření sady výsledků zabere O(N), kde N je celkový počet výsledků v pohledu. Dotazování u pohledů je stále rychlé, i když B-strom obsahuje opravdu velké množství klíčů.
Reduce funkce pracují nad tříděným seznamem výsledků mapovací funkce. CouchDB využívá pro reduce jednu ze základních vlastností B-stromu: pro každý list existuje řetězec uzlů, který nás dovede zpět ke kořeni. Každý list v B-stromu nese pár řádků (řádově desítky, podle velikosti řádku) a každý vnitřní uzel může odkazovat na několik listů nebo jiných vnitřních uzlů.
Reduce funkce je spouštěna pro každý uzel stromu, až k výsledné hodnotě. Výsledná hodnota může být neustále upravována při změnách seznamu výsledků map funkce, takže přepočítání představuje vždy jen několik málo operací. Úvodní reduce je počítáno pro každý list i vnitřní uzel.
Když je funkce reduce volána pro listy (které obsahují výsledky funkce map), je třetí parametr funkce, rereduce, nastaven na false. V tomto případě jsou dalšími argumenty pole klíčů a pole hodnot tak, jak je vrátila funkce map. Funkce reduce vrátí jednu hodnotu, a tu si databáze uloží do vnitřního uzlu, které v tomto případě slouží jako cache pro další redukce.
Když běží reduce funkce ve vnitřních uzlech, je parametr rereduce roven true. To dává funkci vědět, že nezpracovává originální hodnoty z funkce map, ale mezivýsledky funkce reduce. Pokud má strom více než dvě úrovně, je fáze rereduce opakována a dostává výsledky z předchozích úrovní tak dlouho, dokud není vypočítána výsledná hodnota.
Běžná chyba začátečníků v CouchDB je, že vytvářejí reduce funkcí komplexní agregované výstupy. Plná redukce by měla vést k jediné skalární hodnotě, třeba 5, ne k, řekněme, JSON poli se sadou unikátních klíčů a s počtem výskytů každého z nich. Problém s tímto postupem je, že výsledkem je velká sada hodnot, v extrémním případě jeden záznam pro každý výsledek, pokud jsou všechny klíše unikátní. V reduce funkcích je v pořádku počítat víc výsledků – například počet, součet a odchylku pro sadu hodnot můžeme klidně počítat jednou funkcí. Počet dat tam nijak neroste, zůstává konstantní.
Pokud vás zajímá fungování inkrementální funkce reduce, podívejte se na Google’s paper on Sawzall, kde naleznete příklady některých exotických reduce funkcí, které lze vytvořit v systémech s takovými omezeními.
Tento text je součástí překladu knihy CouchDB: The Definitive Guide. Stejně jako autoři originálu oceníme věcné připomínky a pomoc s textem, za které předem děkujeme.
Martin Malý
Začal programovat v roce 1984 s programovatelnou kalkulačkou. Pokračoval k BASICu, assembleru Z80, Forthu, Pascalu, Céčku, dalším assemblerům, před časem v PHP a teď by rád neprogramoval a radši se věnoval starým počítačům.



Náhodou jsem nahlédl, drobná poznámka k překladu: v češtině se normálně říká B-strom.
Hledal jsem, jak moc je běžné v češtině „B-strom“, a nabyl jsem dojmu, že se používá běžně B-tree, a když někdo použije B-strom, tak stejně do závorky napíše, že se jedná o B-tree, aby bylo naprosto jasno. Takže jsem nakonec nechal „B-tree“. Myslíte, že by B-strom byl lepší?
U nás na škole se běžně B-strom používá. Navíc v tomto případě se překladem do češtiny neztratí žádná informace a je jasné, co termín B-strom značí, takže bych byl pro český překlad.
Zvláštní, já v žádném českém textu B-tree ještě neviděl :-) Rychlý průzkum Googlem sice potvrzuje, že to někdo občas použije, ale je to spíš výjimka. Osobně jsem pro překlad.
OK, dobrá…
Neuveritelny.
V zivote jsem nevidel, aby se na cizim foru resili takovy nesmyslny kraviny
Navic by bylo vhodne psat B+ strom, protoze B stromy se temer nepouzivaji.
Vycházím z originálu, kde je důsledně „B-tree“. Ale podívám se podrobněji, jestli používají B+strom, a kdyžtak to změním.
Jo, ve skutečnosti je to B+ strom, ale to není až tak důležité (a v originále se opravdu používá „B-tree“).
Teď ještě přemýšlím a minimálně v případě pohledů to není tak úplně B+ strom, protože částečné výsledky redukcí se ukládají do vnitřních (nelistových) uzlů. Asi bych to neřešil.
Kdyz o tom tak premyslim, docela by se hodila, kombinace relacni a dokumentove databaze.