Vyvíjíme pro Android: Content providery
Content providery na Androidu umožňují aplikaci poskytnout svá data ostatním aplikacím. Dnes si je představíme a potom přepíšeme aplikaci Poznámkový blok z dílu Fragmenty a SQLite databáze tak, aby uměla poznámky poskytnout ostatním aplikacím. Zároveň si procvičíme intent filtry.
Seriál: Vyvíjíme pro Android (14 dílů)
- Vyvíjíme pro Android: Začínáme 15. 6. 2012
- Vyvíjíme pro Android: První krůčky 22. 6. 2012
- Vyvíjíme pro Android: Suroviny, Intenty a jednotky 29. 6. 2012
- Vyvíjíme pro Android: Bližší pohled na pohledy – 1. díl 13. 7. 2012
- Vyvíjíme pro Android: Bližší pohled na pohledy – 2. díl 13. 7. 2012
- Vyvíjíme pro Android: Fragmenty a SQLite databáze 20. 7. 2012
- Vyvíjíme pro Android: Preference, menu a vlastní Adapter 27. 7. 2012
- Vyvíjíme pro Android: Intenty, intent filtry a permissions 3. 8. 2012
- Vyvíjíme pro Android: Content providery 10. 8. 2012
- Vyvíjíme pro Android: Dialogy a activity 17. 8. 2012
- Vyvíjíme pro Android: Stylování a design 24. 8. 2012
- Vyvíjíme pro Android: Notifikace, broadcast receivery a Internet 31. 8. 2012
- Vyvíjíme pro Android: Nahraváme aplikaci na Google Play Store 7. 9. 2012
- Vyvíjíme pro Android: Epilog 14. 9. 2012
Nálepky:
Před týdnem jsme si ukázali, jak používat intenty, intent filtry, a co to jsou permissions. Původně to mělo být v jednom článku společně s dnešním tématem, ale nakonec jsem to kvůli rozsahu rozdělil. Předem říkám, že na rozdíl od předchozích sedmi dílů věci probírané dnes nemusíte znát, abyste mohli něco smysluplného naprogramovat. U mnoha typů aplikací se s content providery vůbec nesetkáte, u dalších jen použijete cizí content provider (ale to je prakticky shodné s prací s databází) a u všech ostatních absence content provideru způsobí jen to, že nedodržíte androidí standard, kdy se snažíme dát uživateli možnost zvolit si alternativní rozhraní a ostatním aplikacím umožnit použít data z naší aplikace k poskytnutí co nejlepšího výsledku.
Proto sice doporučuji dnešní článek přečíst, neboť content providery jsou přese všechno poměrně časté, ale není bezpodmínečně nutné všechno znát. Stačí vědět, kde to najít.
Později budeme rozšiřovat aplikaci Poznámkový blok, kterou jsme naprogramovali ve článku Fragmenty a SQLite databáze. Pokud jste ten článek ještě nečetli, doporučuji to udělat.
Tímto článkem také zakončíme sekci o ukládání a práci s daty. V dalších dílech se můžete těšit na mnohem různorodější témata od stylování aplikace přes práci se senzory až po nahrání aplikace na Play Store.
Dnes si nejprve povíme něco o content providerech obecně a vyzkoušíme si práci s nejjednodušším z vestavěných, UserDictionary. Potom předěláme Poznámkový blok tak, aby používal content providery a aby přijímal implicitní intenty (jako ukázka minule nabytých znalostí v praxi). A nakonec přidám návod, jak v nové verzi ADT pluginu vytvořit projekt.
Co to je content provider?
Content providery jsou, jak už jsem řekl, způsob, jak v Androidu sdílet data mezi aplikacemi. A to nejen mezi aplikacemi se stejným userID, ale mezi všemi aplikacemi na zařízení (které případně vlastní permission). Data v content providerech musí být uspořádaná ve formě tabulky, a tím podobnost s databází nekončí. Content providery totiž dokonce vrací objekty Cursor. Abyste dostali data z nějakého content provideru, musíte mít příslušnou permission (pokud ji provider vyžaduje) a musíte znát URI tabulky, z níž chcete data získat. Situace je ještě trochu zkomplikovaná tím, že jelikož bývají content providery z jiných aplikací a každá aplikace běží ve svém procesu, dokonce pod speciálním linuxovým uživatelem, musí se ještě řešit komunikace mezi procesy, tzv. IPC.
S těmi Cursory to není úplně přesné, content providery mohou poskytovat i soubory, ale to vůbec řešit nebudeme a můžete to pustit z hlavy.
Kvůli tomu existuje třída nazvaná ContentResolver. Tu získáte metodou Context.getContentResolver() a má stejné rozhraní jako ContentProvider (co se pro nás dnes důležitých metod týče). A právě tyto dvě třídy zajišťují IPC, takže se o nic nemusíte starat. Ve své aplikaci získáte content resolver a poprosíte ho o získání nějakých dat (nebo přidání nových atp.). Pomocí URI mu sdělíte, o kterou tabulku (či o který záznam) kterého content provideru máte zájem. Content resolver se za vás postará o spuštění toho content provideru a předá mu váš požadavek (první IPC). Content provider získá data z nějakého datového úložiště (v naprosté většině případů SQLite databáze), vytvoří z nich Cursor a ten předá content resolveru (druhé IPC). Content resolver potom Cursor bezpečně doručí vaší aplikaci. To, co jsem popsal, snad výmluvněji ukazuje následující obrázek.

Když jsem povídal, že data se předávají v Cursoru, tak je z toho jasné, že se dají poslat jen některé primitivní datové typy (vč. řetězců).
Vnější struktura content provideru
Jak má data strukturovaná uvnitř je celkem jeho problém, ale navenek funguje analogie s databázemi, neboť content provider se tváří jako databáze, která obsahuje jednu nebo více tabulek. Tabulky mají jména a obsahují sloupce, také pojmenované. V tabulkách jsou jednotlivé záznamy reprezentované jako řádky. Je konvencí, že každý záznam má jednoznačný číselný identifikátor a že je tento identifikátor ve sloupci s názvem _ID. Díky tomu je možné Cursor získaný od content provideru (s pomocí content resolveru) rovnou předat CursorAdapter-u.
Content URI
Content URI je unikátní pro každý content provider, pro jeho každou tabulku, a dokonce pro každý záznam. Skládá se ze tří částí: scheme (vždy povinně content://), authority, což je část, která ukazuje na celý content provider, a path, která identifikuje jednotlivé tabulky popřípadě záznamy.
Vestavěné providery mají authority všelijakou, například UserDictionary má authority user_dictionary. Vaše content providery by, aby nedošlo ke kolizi s cizími, měly mít prefix totožný s namespace vaší aplikace a jako samotný název použít buď provider, pokud je v aplikaci jen jeden a už namespace ho dobře vystihuje, anebo nějaké slovo, které popisuje, co provider nabízí. Content URI našeho provideru bude vypadat takto: content://com.example.notepad.provider. Použili jsme slovo provider, protože už samotný namespace jasně popisuje, co nabízíme.
Samotná path už závisí na content provideru, nicméně je standardem, že u většiny případů ji bude tvořit právě jedna „složka” identifikující jednotlivé tabulky. Ale u složitějších content providerů, které mají třeba dvě tabulky nějakým způsobem příbuzné, můžete použít i delší path pro tabulku ( type/table1 pro table1 a type/table2 pro table2 – konkrétní příklad, kde by to nebylo lepší vyřešit jinak, mě, ač jsem přemýšlel dlouho, nenapadá). Takže pokud chceme získat záznamy z tabulky notes, content URI bude taková: content://com.example.notepad.provider/notes.
Protože si path obhospodařujete sami, příklad s více zanořením by se asi dal použít třeba pro databázi knih, kdybyste chtěli nabídnout pseudotabulky (v MySQL se tomu říká pohledy, jak jinde, nevím) podle jednotlivých žánrů, mohli byste použít path books/novels, books/scifi, books/crime atd. Potom byste, majíce v databázi fakticky jen jednu tabulku books, vytvořili dotaz, který by vrátil jen knihy s odpovídajícím žánrem. To má, je-li zobrazování jednotlivých žánrů časté, určitě opodstatnění.
Je konvencí, že každá položka má unikátní číselný identifikátor. Díky tomu lze vytvořit content URI odkazující na jednu konkrétní položku. Uděláte to přidáním číselného id na konec path. Kdybychom chtěli získat poznámku s id 42, výsledná content URI by byla takováhle: content://com.example.notepad.provider/notes/42. Protože je přidávání id na konec URI velmi častý úkon, existuje na to statická metoda ContentUris.withAppendedId(Uri uri, long id).
MIME types
Každý content provider (potažmo content resolver, ale když budu v uživatelské části (tzn. než budeme vytvářet vlastní content providery) mluvit o tom, že content provider má nějakou metodu, má ji určitě i content resolver) nabízí metodu getType(Uri uri). Ta vrátí MIME type pro data, která se nacházejí na dané URI.
Možná jste si všimli, že ač v textu píšu URI, v kódu používám Uri. Je to proto, že existují třídy android.net.Uri, ale i java.net.URI. Protože my používáme androidí variantu, používáme třídu Uri. Ale protože URI je zkratka Uniform Resource Identifier, používám v souladu s pravidly velká písmena.
Kdyby se náhodou (což jsme ale zapomněli, že existuje) na dané URI nacházel soubor, metoda vrátí normální IANA MIME type. Pokud daná URI ukazuje na tabulku (nebo obecně více záznamů), použije se MIME type speciální pro Android, které má jako type vnd.android.cursor.dir a jako subtype má první prefix vnd, za ním následuje namespace vaší aplikace a potom za další tečkou samotný typ dat. Pro naše poznámky použijeme MIME type vnd.android.cursor.dir/vnd.com.example.notepad.note. Pokud URI zastupuje jen jeden řádek (tzn. má na konci id), použije se úplně stejné MIME type jako pro příslušnou tabulku, jenom místo dir v type se použije item ( vnd.android.cursor.item/vnd.com.example.notepad.note).
Když už jsem nás trochu zmátl se soubory, musím ukonejšit obavy některých z vás, že se budete muset starat o to, jaký soubor se na nějaké URI nachází, kdyby se vás na to náhodou někdo zeptal. To se samozřejmě nestane. Pokud někdo použije metodu ContentResolver.getType(), content resolver zjistí, kdo v manifestu tvrdí, že se o danou URI stará.
Předchozími dvěma podkapitolami jsem vás trochu uvedl do problematiky okolo content providerů a zároveň jsem dnešní článek propojil s minulým, ale teď už se vrhneme na samotné content providery.
UserDictionary
UserDictionary je nejjednodušší z vestavěných content providerů, takže, ač se mi vůbec nelíbí, vyzkoušíme si práci s ním. Budeme dělat dost podobné věci jako dokumentace, která si UserDictionary vybrala také.
Content provider UserDictionary by měl obsahovat uživatelem používaná slova, která by se měla používat k různým predikcím a autocomplete. U mě ovšem obsahoval pouze jedno slovo – „Hello” –, a to ještě jako české slovo. Je možné, že třeba vestavěná klávesnice UserDictionary používá, ale žádná aplikace, s níž přicházím do styku já, tak nečiní. To je také důvod, proč tenhle provider nemám rád.
Jak jsme si řekli, content providery poskytují data v tabulkách. Tak činí i UserDictionary. Kdybych vám měl ukázat, jako taková tabulka může vypadat, ukázal bych vám něco takového (další příklad můžete najít na již odkazované stránce dokumentace, která mi mimochodem přijde trochu zmatená):
| _ID | word | frequency | locale | appid |
|---|---|---|---|---|
| 1 | polib | 8535 | cs_CZ | user5 |
| 2 | mi | 8899 | cs_CZ | user5 |
| 3 | naleštěnej | 9125 | cs_CZ | user5 |
| 4 | cimprcampr | 10536 | cs_CZ | user5 |
| 5 | zadek | 169342 | cs_CZ | user5 |
Sloupce _ID, word i frequency jsou jasné, locale určuje, v jakém jazyce dané slovo je, a k čemu nám může být appid, to netuším. Všimněte si, že první id je jednička. To není chyba, je to vlastnost (nejen) SQLite databáze, že AUTOINCREMENT sloupce obvykle začínají jedničkou.
Možná jste si také všimli, že třída UserDictionary, na niž tak vehementně odkazuju a o níž mluvím jako o content provideru, ve skutečnosti dědí přímo od Object-u. Není to proto, že by to byl nějaký speciální content provider, nebo že by dokonce neexistoval. Příslušný content provider jen není v dokumentaci, protože s ním nikdy přímo nepřijdeme do styku. Místo toho content providery obvykle nabízejí třídy, na nichž jsou definovány různé konstanty – URI provideru, názvy jednotlivých sloupců, časté způsoby řazení výsledků, možné hodnoty nějakého sloupce jako náhrada za datový typ enum, a tak podobně. Někdy taky (zrovna i v našem případě) nabízejí tyto třídy statické metody pro zjednodušení přidávání dat.
Takovým třídám se říká contract classes a měly by existovat pro každý provider plus pro každou jeho tabulku. Android pro své providery contract classes poskytuje, v balíčku android.provider. Vy byste u svých providerů měli udělat to samé, aby jejich uživatelé (a konec konců i vy) neměli své třídy zaplevelené různými trochu magickými řetězci. Ale má to jeden háček – jedna aplikace nemůže nijak přistupovat k souborům druhé. Své contract classes proto musíte nabídnout někde ke stažení.
Práce s content providery
Teď už víme všechno podstatné, a tak si konečně můžeme naprogramovat aplikaci, v níž si vyzkoušíme UserDictionary používat. Ta se bude skládat z jedné ListActivity, která zobrazí seznam všech slov. Kromě toho bude obsahovat menu se dvěma položkami: přidat slovo, která přidá slovo „howgh“, a odebrat slovo, která odebere slovo s nejvyšším id.
Vytvořme si nový projekt s jednou Activity, pojmenovanou třeba MainActivity. Její soubor upravíme, aby dědil od ListActivity. Zároveň si nachystáme metodu onCreate, aby zavolala metodu, která vytvoří Adapter a nastaví ho ListView, a také si nachystáme metody obhospodařující options menu:
public class MainActivity extends ListActivity {
@Override
public void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
fillListView();
}
@Override
public boolean onCreateOptionsMenu(Menu menu) {
getMenuInflater().inflate(R.menu.activity_main, menu);
return true;
}
@Override
public boolean onOptionsItemSelected(MenuItem item) {
switch (item.getItemId()) {
case R.id.add_word:
addWord();
return true;
case R.id.remove_last_word:
removeLastWord();
return true;
default:
return super.onOptionsItemSelected(item);
}
}
Soubor /res/menu/activity_main.xml (který se vám mimochodem, pokud máte ADT v20, vytvořil už při vytváření projektu, jen s jiným obsahem) vypadá takto:
<menu xmlns:android="http://schemas.android.com/apk/res/android" >
<item
android:id="@+id/add_word"
android:title="@string/add_word"/>
<item
android:id="@+id/remove_last_word"
android:title="@string/remove_last_word"/>
</menu>
Abychom mohli pokračovat, potřebujeme ještě dvě věci: permissions pro user dictionary a layout pro jednotlivé záznamy.
Začneme permissions. V jejich případě je to opravdu jednoduché, prostě do manifestu přidáme tyto dva řádky:
<uses-permission android:name="android.permission.READ_USER_DICTIONARY" /> <uses-permission android:name="android.permission.WRITE_USER_DICTIONARY" />
Technická poznámka: určitě jste si všimli, že už dlouho sem nevypisuji například strings.xml. Nebo že u většiny výpisů neříkám jména souboru. Dělám to tak záměrně. Možná vám to způsobí trochu komplikací a zjišťování, jak máte co pojmenovat, jak má soubor strings.xml vypadat a tak podobně. Ale jsem přesvědčen o tom, že vám to dlouhodobě prospěje. Pokud věcem, které vynechávám, bez problému rozumíte, žádný problém byste mít neměli. Pokud jim nerozumíte, alespoň to zjistíte a to, že bez toho nevytvoříte funkční ukázkovou aplikaci, vás donutí je pochopit.
Nikdy nevynechávám žádné záludnosti nebo věci, se kterými se nebudete setkávat. Vždycky jsou to jenom takové případy, jež budete potřebovat dnes a denně.
A zrovna na tomto místě o tom píšu, protože <uses-permission> či menu jsou ideální kandidáti na vynechání.
Layout pro jednotlivé záznamy
Když se podíváme na tabulku, vidíme, že UserDictionary má pět sloupců. My bychom, kdybychom chtěli a dali si s tím tu práci, mohli samozřejmě použít třeba TableLayout, ale pak bychom nemohli využít adaptery. Nebo bychom mohli jednotlivé sloupce alespoň nějak hezky uspořádat. Ale protože si dnes povídáme o content providerech, layout pro jednotlivé položky odbudeme a bude to prostě vertikální LinearLayout s pěti TextView uvnitř:
<LinearLayout xmlns:android="http://schemas.android.com/apk/res/android"
android:layout_width="match_parent"
android:layout_height="match_parent"
android:orientation="vertical" >
<TextView
android:id="@+id/id"
android:layout_width="match_parent"
android:layout_height="wrap_content" />
<TextView
android:id="@+id/word"
android:layout_width="match_parent"
android:layout_height="wrap_content" />
<TextView
android:id="@+id/frequency"
android:layout_width="match_parent"
android:layout_height="wrap_content" />
<TextView
android:id="@+id/locale"
android:layout_width="match_parent"
android:layout_height="wrap_content" />
<TextView
android:id="@+id/app_id"
android:layout_width="match_parent"
android:layout_height="wrap_content" />
</LinearLayout>
Důležité funkce naší MainActivity
Konečně se dostáváme k tomu zajímavému. Ve fillListView() získáme objekt ContentResolver metodou getContentResolver(), a na něm potom zavoláme metodu query(Uri uri, String[] projection, String selection, String[] selectionArgs, String sortOrder). Jak vidíte, metoda je velmi podobná SQLiteDatabase.query(String table, String[] columns, String selection, String selectionArgs, String groupBy, String having, String orderBy), až na to, že v SQLite místo URI předáváme název tabulky, druhý parametr, ač znamená to samé, se jmenuje jinak a SQLite navíc nabízí možnost seskupení a klauzuli HAVING.
Jako URI metodě query() získaného content resolveru předáme URI tabulky words content provideru UserDictionary. Tabulka words je reprezentována contract třídou UserDictionary.Words, na níž je definována konstanta s URI a konstanty se všemi důležitými řetězci. Konstanta s URI se jmenuje CONTENT_URI. Atribut projection určuje, které sloupce chceme vrátit. My chceme všechny, takže předáme pole názvů všech sloupců (konstanty UserDictionary.Words). Chceme i všechny řádky, takže jako selection i selectionArgs předáme null. Seřadit chceme vzestupně podle id.
Potom zkusíme zalogovat počet řádků a MIME type tabulky (o logování jsem se zmínil na konci Preference, menu a vlastní Adapter), vytvoříme SimpleCursorAdapter (ze Support Library!), o němž jsem povídal ve článku Fragmenty a SQLite databáze, a ten nastavíme ListView:
private void fillListView() {
String[] projection = {
UserDictionary.Words._ID,
UserDictionary.Words.WORD,
UserDictionary.Words.LOCALE,
UserDictionary.Words.FREQUENCY,
UserDictionary.Words.APP_ID,
};
int[] to = {
R.id.id,
R.id.word,
R.id.locale,
R.id.frequency,
R.id.app_id
};
ContentResolver cr = getContentResolver();
Cursor c = cr.query(UserDictionary.Words.CONTENT_URI, projection,
null, null, UserDictionary.Words._ID + " ASC");
Log.d("size", String.valueOf(c.getCount()));
Log.d("type", cr.getType(UserDictionary.Words.CONTENT_URI));
SimpleCursorAdapter adapter = new SimpleCursorAdapter(this,
R.layout.list_item, c, projection, to, 0);
setListAdapter(adapter);
}
A teď už nám stačí jen vytvořit metody addWord() a removeLastWord().
Začneme s addWord(), která je jednodušší. Správně bychom sice určitě měli použít metodu UserDictionary.Words.addWord(), ale to bychom se nenaučili zacházet s content resolverem.
Budeme potřebovat metodu insert(Uri uri, ContentValues contentValues), která je, jak jste si určitě všimli velmi podobná metodě SQLiteDatabase.insert(). S tou umíme, v content resolverové jen chybí nullColumnHack a místo názvu tabulky předáváme URI tabulky, takže můžeme addWord() rovnou naimplementovat:
private void addWord() {
// Správně bychom měli použít UserDictionary.Words.addWord()
ContentValues values = new ContentValues();
values.put(UserDictionary.Words.WORD, "howgh");
values.put(UserDictionary.Words.LOCALE, "cs_CZ");
getContentResolver().insert(UserDictionary.Words.CONTENT_URI, values);
fillListView();
}
Protože tabulku přesně neznám, nevím, jestli bychom neměli předat ještě nějaká další data, ale s word a locale to funguje, tak to nebudeme komplikovat.
Nakonec metoda removeLastWord(). Ta je trochu složitější. Nejdříve totiž získáme id řádku s nejvyšším id. Pokud takový řádek existuje, vytvoříme content URI speciálně pro něj ( ContentUris.withAppendedId(Uri uri, long id)) a tu předáme metodě ContentResolver.delete(Uri uri, String where, String selectionArgs). Protože už máme URI, která ukazuje na ten jeden řádek, který chceme odstranit, místo where a selectionArgs předáme null. Znovu vyzkoušíme zalogovat MIME type dat na dané URI, tentokrát je tam ale jen jeden řádek (→ místo dir tam bude item):
private void removeLastWord() {
ContentResolver cr = getContentResolver();
Cursor maxIdCursor = cr.query(
UserDictionary.Words.CONTENT_URI,
new String[]{UserDictionary.Words._ID},
null,
null,
UserDictionary.Words._ID + " DESC");
long maxId = 0;
if (maxIdCursor.moveToFirst())
maxId = maxIdCursor.getLong(0);
maxIdCursor.close();
if (maxId > 0) {
Uri deleteUri = ContentUris.withAppendedId(
UserDictionary.Words.CONTENT_URI, maxId);
Log.d("deleteType", cr.getType(deleteUri));
cr.delete(deleteUri, null, null);
fillListView();
}
}
Ta 0 u Cursor.getLong() není žádné magické číslo. Cursor.getLong() přebírá index sloupce, jehož data chceme získat. Poněvadž jsme chtěli pouze jeden sloupec, bude mít určitě index 0. Takhle se to z lenosti dělá často, stejně dobře by fungovala i metoda getColumnIndex.
FillListView() voláme na konci obou metod proto, aby se seznam aktualizoval.
Tím máme aplikaci používající content provider hotovou, můžeme ji spustit a pokochat se. Neřešte to, že tabulku určitě nepoužíváme správně, protože přidáváme-li stejné slovo, které už tam je, měli bychom místo toho zvýšit četnost toho už přítomného. Ale my se jen chtěli naučit pracovat s content providerem a UserDictionary je zdaleka nejjednodušší. Nezapomeňte ho pro jistotu vrátit do původního stavu poté, co si s aplikací vyhrajete.

Upravujeme Poznámkový blok
Předem upozorňuji, že to nebude jednoduché. A ještě je to trochu zkomplikované o to, že budeme upravovat něco, co jsme naprogramovali o něco dříve. Bohužel bychom se s novou aplikací do jednoho článku nevešli. Proto opravdu doporučuju mít při čtení tohoto článku staženou a otevřenou původní aplikaci (odkaz na konci) a dívat se, co se kde mění.
Týkat se to bude hlavně třídy Notes. Tu přejmenujeme na NotesProvider a bude dědit od ContentProvider. DatabaseHelper zůstane, kód z konstruktoru se přesune do metody onCreate. Naše metody pro práci s databází se změní, místo toho se budou jmenovat jako content providerové metody a budou přijímat více argumentů, které vesměs ale jen předají databázi.
@Override
public boolean onCreate() {
openHelper = new DatabaseHelper(getContext());
}
Contract classes
Ačkoliv bychom měli vytvořit dvě contract classes, jednu pro celý content provider ( NotesContract) a druhou pro tabulku notes ( NotesContract.Notes), trochu si to zjednodušíme a vytvoříme jen NotesContract. Tam jednak přesuneme definici konstant z NotesProvider-u a jednak musíme vymyslet, jaká bude content URI pro naši tabulku. O tom jsme si ale už povídali a vlastně jsme ji dokonce vymysleli – content://com.example.notepad.provider/notes. A NotesContract bude vypadat takhle:
public final class NotesContract {
public static final String AUTHORITY = "com.example.notepad.provider";
public static final String NOTES = "notes";
public static final Uri CONTENT_URI = Uri.parse("content://" + AUTHORITY);
public static final Uri CONTENT_URI_NOTES = Uri.parse("content://"
+ AUTHORITY + "/" + NOTES);
public static final String _ID = "_id";
public static final String TITLE = "title";
public static final String NOTE = "note";
public static final String[] PROJECTION = { _ID, NOTE, TITLE };
public static final String DEFAULT_SORT_ORDER = _ID + " DESC";
public static final String MIME_TYPE_ITEM =
"vnd.android.cursor.item/vnd.com.example.notepad.note";
public static final String MIME_TYPE_DIR =
"vnd.android.cursor.dir/vnd.com.example.notepad.note";
}
Konstanta s názvem databáze a tabulky je interní, takže je necháme v NotesProvider.
Určitě jste si všimli, že jsme do NotesContract přidali i konstanty s MIME typy, přesně takové, jaké jsme navrhli dříve v tomto článku.
UriMatcher
Ještě než se pustíme do implementování těch nejzajímavějších metod, musíme vyřešit jednu věc: Jak už jsem se zmínil, o path content URI se musí postarat content provider. A ten to dělá pomocí třídy UriMatcher. Ta má dvě metody: První z nich se jmenuje addURI(String authority, String path, int code) a umí přidat URI. Jako authority se předá authority dané URI, jako path se předá potřebná path, přičemž můžeme použít * jako wildcard pro jakýkoli text a # jako wildcard pro jakákoli čísla. Code je nějaké číslo, které si spojíme s popsanou URI. Metoda match() přebírá jako argument nějakou URI a vrátí číslo, které odpovídá code u té URI předané addURI(), jež podpovídá URI předané match(), anebo číslo předané konstruktoru, pokud URI, jíž dostala metoda match() neodpovídá žádnému uloženému vzoru. Hezky je to ukázané právě v dokumentaci třídy UriMatcher .
My, protože máme jen jednu tabulku, to budeme mít docela jednoduché. Jednak potřebujeme nějaké číslo, které předáme konstruktoru a které znamená, že požadovanou URI neznáme (na to použijeme konstantu UriMatcher.NO_MATCH. Potom musíme přidat URI pro tabulku notes bez id a URI pro notes s id. Takže někam na začátek třídy NotesProvider přidáme následující řádky:
private static final int NOTES = 0;
private static final int NOTES_ID = 1;
private static final UriMatcher uriMatcher = new UriMatcher(UriMatcher.NO_MATCH);
static {
uriMatcher.addURI(NotesContract.AUTHORITY, NotesContract.NOTES, NOTES);
uriMatcher.addURI(NotesContract.AUTHORITY, NotesContract.NOTES + "/#", NOTES_ID);
}
Abychom si vyzkoušeli, jak UriMatcher funguje, implementujeme metodu getType(). Ta přebírá URI a vrátí MIME type dat na ní se nacházejících. V našem případě, bude-li to URI tabulky notes, vrátíme NotesContract.MIME_TYPE_DIR, bude-li to URI jednoho záznamu, vrátíme NotesContract.MIME_TYPE_ITEM, a jinak vyhodíme IllegalArgumentException:
@Override
public String getType(Uri uri) {
switch (uriMatcher.match(uri)) {
case NOTES:
return NotesContract.MIME_TYPE_DIR;
case NOTE_ID:
return NotesContract.MIME_TYPE_ITEM;
default:
throw new IllegalArgumentException("Unknown URI " + uri);
}
}
A zbývají nám už jen metody query, insert, delete a update. Jak už jsme si řekli, jejich argumenty jsou podobné argumentům stejně se jmenujících metod třídy SQLiteDatabase, takže půjde jen o to ošetřit některé vstupy a případně některé argumenty poupravit. Začneme s delete().
Metoda delete()
Metoda delete() vrací počet smazaných řádků, takže vrátíme to, co nám vrátí metoda SQLiteDatabase.delete(). A dále se nám dělí na dva případy:
Pokud uživatel předá URI celé tabulky a o podmínky se postará sám, máme to jednoduché:
@Override
public int delete(Uri uri, String selection, String[] selectionArgs) {
SQLiteDatabase db = openHelper.getWritableDatabase();
int count;
switch (uriMatcher.match(uri)) {
case NOTES:
count = db.delete(TB_NAME, selection, selectionArgs);
break;
Ale pokud předá URI jednoho jediného záznamu, máme práci složitější. Uživatel totiž i přesto může předat nějakou podmínku WHERE, tedy parametr selection, a tudíž i selectionArgs. SQLite databáze žádné URI nemá, takže podmínku pro id musíme vytvořit v kaluzuli WHERE. A to nás staví před problém správného spojení dvou podmínek. Já postupoval následovně: Vytvořil jsem si kopii selectionArgs o jedno větší (případně řetězcové pole s délkou 1, pokud je selectionArgs null. Na poslední místo oné kopie jsem umístil id z URI. Potom jsem vytvořil jednoduchou klauzuli where _ID = ?, a pokud selection nebylo null ani prázdný řetězec, umístil jsem ho před mou původní klauzuli where a spojil jsem je spojkou AND. Na tyto pomocné úkony jsem samozřejmě vytvořil vlastní pomocné metody, ukážu je, jen co uzavřu deklaraci delete().
case NOTE_ID:
// .get(1), protože id je v path na pozici č. 1 (číslováno od nuly)
// Na pozici 0 je "notes". Celá path vypadá třeba takto:
// /notes/44
String[] newArgs = createSelectionArgsWithId(selectionArgs, uri
.getPathSegments().get(1));
String where = createSelectionWithId(selection);
count = db.delete(TB_NAME, where, newArgs);
break;
Na tvorbu SQL řetězců se dá použít SQLiteQueryBuilder. Musím se však přiznat, že se mi nelíbí, nepřijde mi příliš intuitivní, a tak s ním neumím a nepoužívám ho.
Poslední, jednoduchý případ je, když UriMatcher žádnou shodu nenašel. Potom vyhodíme IllegalArgumentException. Pak ještě musíme uzavřít blok switch, vrátit počet smazaných řádek a ukončit definici metody:
default:
throw new IllegalArgumentException("Unknown URI " + uri);
}
// Vrátíme počet smazaných řádků
return count;
}
A ještě ty slíbené metody. Metoda copyOfArray je má vlastní implementace Arrays.copyOf(), která je v Androidu až od API 9.
private String[] createSelectionArgsWithId(String[] oldArgs, String id) {
String[] newArgs;
if (oldArgs != null)
newArgs = copyOfArray(oldArgs, oldArgs.length + 1);
else
newArgs = new String[1];
newArgs[newArgs.length - 1] = id;
return newArgs;
}
private String createSelectionWithId(String oldSelection) {
String where = NotesContract._ID + " = ?";
if (oldSelection != null && !oldSelection.equals("")) {
where = oldSelection + " AND " + where;
}
return where;
}
Metoda insert()
Když jsme si vysvětlili delete(), ostatní metody už budou jednoduché. U insert() jde hlavně o kontrolu, zdali jsou v předaných content values všechny vyžadované hodnoty a případné nastavení výchozích hodnot těch ostatních. Pokud chybí nějaká povinná, můžeme vyhodit výjimku.
Ale s těmi výjimkami to není tak úplně jednoduché. Protože se data přenáší skrz procesy, musíme zvolit takovou výjimku, kterou umí Android přenést. A ty jsou podle dokumentace dvě: IllegalArgumentException a NullPointerException.
Ještě než budeme testovat content values, zjistíme, jestli je předané URI URI tabulky notes.
@Override
public Uri insert(Uri uri, ContentValues values) {
if (uriMatcher.match(uri) != NOTES) {
throw new IllegalArgumentException("Unknown URI " + uri);
}
if (!values.containsKey(NotesContract.TITLE)) {
throw new NullPointerException("ContentValues must contain key "
+ NotesContract.TITLE);
}
if (!values.containsKey(NotesContract.NOTE)) {
throw new NullPointerException("ContentValues must contain key "
+ NotesContract.NOTE);
}
SQLiteDatabase db = openHelper.getWritableDatabase();
long id = db.insert(TB_NAME, null, values);
if (id > 0) {
return ContentUris.withAppendedId(NotesContract.CONTENT_URI_NOTES,
id);
} else {
return null;
}
}
A teď nám už zbývají jen dvě metody: query() a update(). Začneme třeba s update().
Metoda update()
Metoda update() přebírá URI, WHERE, tedy selection a selectionArgs, a content values. Budeme ale dělat v podstatě to samé jako u mětody delete(), neboť content values kontrolovat nemusíme, výchozí hodnoty jsou v databázi. Ohromně se nám tudíž budou hodit metody createSelectionArgsWithId() a createSelectionWithId():
@Override
public int update(Uri uri, ContentValues values, String selection, String[] selectionArgs) {
SQLiteDatabase db = openHelper.getWritableDatabase();
int count;
switch (uriMatcher.match(uri)) {
case NOTES:
count = db.update(TB_NAME, values, selection, selectionArgs);
break;
case NOTE_ID:
// Musíme vytvořít podmínku WHERE pro dané ID, ale zároveň musíme
// zachovat případné where předané uživatelem.
String[] newArgs = createSelectionArgsWithId(selectionArgs, uri
.getPathSegments().get(1));
String where = createSelectionWithId(selection);
count = db.update(TB_NAME, values, where, newArgs);
break;
default:
throw new IllegalArgumentException("Unknown URI " + uri);
}
// Vrátíme počet smazaných řádků
return count;
}
Metoda query()
Nakonec jsme si nechali metodu query(), ale to neznamená, že by byla nějak složitá. Opět se musíme (a opět stejným způsobem) poprat s URI s id. Navíc umožníme uživateli předat jako sortOrder null, přičemž použijeme náš výchozí. A potom zavoláme SQLiteDatabase.query(), přičemž jako groupBy a having předáme null. Toť vše.
@Override
public Cursor query(Uri uri, String[] projection, String selection,
String[] selectionArgs, String sortOrder) {
SQLiteDatabase db = openHelper.getReadableDatabase();
if(sortOrder == null || sortOrder.equals(""))
sortOrder = NotesContract.DEFAULT_SORT_ORDER;
switch (uriMatcher.match(uri)) {
case NOTES:
break;
case NOTE_ID:
selectionArgs = createSelectionArgsWithId(selectionArgs, uri
.getPathSegments().get(1));
selection = createSelectionWithId(selection);
break;
default:
throw new IllegalArgumentException("Unknown URI " + uri);
}
return db.query(TB_NAME, projection, selection, selectionArgs, null, null, sortOrder);
}
Permissions a manifest
Každý content provider musí být zaregistrován v manifestu, aby s ním Android dokázal pracovat. A také by se asi hodilo, kdyby aplikace pro přístup k našemu content provideru musely požádat o nějaké permissions. <provider> je potomkem <application>, permissions umíte vytvořit.
<provider
android:name=".NotesProvider"
android:authorities="com.example.notepad.provider"
android:readPermission="com.example.notepad.READ_NOTES"
android:writePermission="com.example.notepad.WRITE_NOTES" />
Element <provider> si asi zaslouží být popsán trochu důkladněji. Atribut android:name specifikuje, která třída je providerem. Android:authorities obsahuje authority daného provideru. Android:readPermission obsahuje název permission potřebné pro čtení provideru (tzn. query()), zatímco android:writePermission obsahuje název permission potřebné pro zapisování do provideru (tedy insert(), update() a delete()). Ještě snad řeknu, že aplikace, v níž je provider definován, si samozřejmě o permissions explicitně žádat nemusí.
A tím máme, dámy a pánové, náš provider hotový.
Intent filtry
Tím, že máme data reprezentovaná jako Uri, se nám nabízí možnost vytvořit i intentový, resp. intent filterový protokol. Má to však jeden háček. Nikdy jsem nenašel, jak jednoduše udělat něco takového, máme-li naši aplikaci založenou na fragmentech. Problém je totiž ten, že v manifestu nemůžu filtrovat na základě velikosti displeje. Nejde tedy nijak říci, že pokud má displej na šířku alespoň 660dp, má se pro zobrazovací Intent s určitou URI spustit NotepadActivity, která se už nějak postará o své fragmenty, ale pokud je displej menší, má se spustit SingleNoteActivity. My to vyřešíme tak, že pro každý zobrazovací Intent se spustí SingleNoteActivity, která rozhodne, co dál. Takže nejdříve intent filter (všimněte si, jak jsme chytře využili MIME type):
<activity android:name=".SingleNoteActivity" >
<intent-filter>
<action android:name="android.intent.action.VIEW" />
<category android:name="android.intent.category.DEFAULT" />
<category android:name="android.intent.category.BROWSABLE" />
<data android:mimeType="vnd.android.cursor.item/vnd.com.example.notepad.note" />
</intent-filter>
</activity>
Všimněte si, že přestože nikde nebudeme Intentu MIME type nastavovat, můžeme ho v intent filteru použít. Android totiž z content provideru umí MIME type získat.
Aby mohla SingleNoteActivity rozhodnout, zda se o Intent postará sama, anebo se vypne a místo sebe spustí NotepadActivity, musí vědět, jestli má dvousloupcový layout. Za nejjednodušší považuju v /res/layout-w660dp vytvořit layoutový XML soubor single_note_container.xml (tak se jmenuje layoutový soubor SingleNoteActivity), které bude s jednosloupcovým totožné, až na skryté View s nějakým id. Pokud bude existovat, jsme dvousloupcoví, jinak jednosloupcoví.
Třídu SingleNoteActivity změníme takto:
public class SingleNoteActivity extends FragmentActivity {
@Override
public void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.single_note_container);
boolean dualPane = findViewById(R.id.are_we_dual_pane) != null;
Intent i = getIntent();
if(dualPane){
i.setClass(this, NotepadActivity.class);
startActivity(i);
finish();
} else{
Fragment f = new SingleNoteFragment(i.getData());
FragmentTransaction ft = getSupportFragmentManager().beginTransaction();
ft.replace(R.id.container, f);
ft.commit();
}
}
}
To nám bude házet chybu kvůli SingleNoteFragment-u, který nepřijímá URI, ale to vyřešíme okamžitě.
SingleNoteFragment
U něj je to jednoduché – řádky
NotesProvider notes = new NotesProvider(getActivity()); Cursor note = notes.getNote(id); int titleIndex = note.getColumnIndex(NotesProvider.COLUMN_TITLE); int textIndex = note.getColumnIndex(NotesProvider.COLUMN_NOTE);
změníme na
Cursor note = getActivity().getContentResolver().query(uri,
NotesContract.PROJECTION, null, null, null);
int titleIndex = note.getColumnIndex(NotesContract.TITLE);
int textIndex = note.getColumnIndex(NotesContract.NOTE);
a ještě smažeme řádek notes.close().
NotesListFragment
Další na řadu přijde třeba NotesListFragment. Tam budeme měnit jen metody updateList() a deleteNote(), tedy ty, které pracovaly s databází. Teď budou pracovat s content providerem.
public void updateList() {
Context ctx = getActivity();
String[] projection = { NotesContract._ID, NotesContract.TITLE };
String[] from = { NotesContract.TITLE };
int[] to = { android.R.id.text1 };
Cursor c = ctx.getContentResolver().query(
NotesContract.CONTENT_URI_NOTES, projection, null, null, null);
// Jako předtím...
}
private void deleteNote(long id) {
Context ctx = getActivity();
Uri uri = ContentUris.withAppendedId(NotesContract.CONTENT_URI_NOTES,
id);
boolean deleted = ctx.getContentResolver().delete(uri, null, null) > 0;
if (deleted)
// Jako předtím...
}
NotepadActivity
Jako poslední nám zbyla NotepadActivity. Tam je toho na změnu více. Začneme metodou onCreate(). Ta od SingleNoteActivity může dostat Intent s URI poznámky ke zobrazení. Takže musíme zjistit, jestli takový Intent máme, a pokud ano, tak ho zobrazit (případně znovu spustit SingleNoteActivity, pokud se mezitím změnil počet sloupců):
@Override
public void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.main);
dualPane = findViewById(R.id.right_column) != null;
Intent i = getIntent();
if (i.getAction() == Intent.ACTION_VIEW) {
Uri uri = i.getData();
// Zkontrolovat, jestli je tam URI
if(uri == null)
return;
// a jestli je to URI NotesProvideru.
if(!uri.getAuthority().equals(NotesContract.AUTHORITY))
return;
// Nakonec poznámku z dané URI zobrazit.
showNote(uri);
}
}
O zobrazení se stará metoda showNote():
private void showNote(Uri uri) {
if (dualPane) {
Fragment f = new SingleNoteFragment(uri);
FragmentTransaction ft = getSupportFragmentManager()
.beginTransaction();
ft.replace(R.id.right_column, f);
ft.addToBackStack(null);
ft.commit();
} else {
Intent i = new Intent(Intent.ACTION_VIEW, uri);
startActivity(i);
}
}
Když jsme ale změnili typ argumentu metody showNote(), objevily se hned dvě chyby, které ji dále chtějí předávat id poznámky. Jednu z nich ( onAddNote) budeme stejně předělávat, ale onNoteClicked to dělá naprosto legitimně. Asi je dobrý nápad metodu showNote() přetížit, aby přebírala i id poznámky:
private void showNote(long id){
Uri uri = ContentUris.withAppendedId(NotesContract.CONTENT_URI_NOTES, id);
showNote(uri);
}
Poslední problémy jsou v metodě onAddNote(). Ty jsou způsobeny změnou úložného systému na content provider:
public void onAddNote(String title, String text) {
ContentValues values = new ContentValues();
values.put(NotesContract.TITLE, title);
values.put(NotesContract.NOTE, text);
Uri uri = getContentResolver().insert(NotesContract.CONTENT_URI_NOTES,
values);
if (uri != null) {
((NotesListFragment) getSupportFragmentManager().findFragmentById(
R.id.notes_list)).updateList();
if (dualPane)
showNote(uri);
} else {
Toast.makeText(this, R.string.note_not_added, Toast.LENGTH_LONG)
.show();
}
}
A tím máme náš poznámkový blok hotový. Navenek vypadá úplně stejně jako před třemi týdny, ale uvnitř je notně vylepšený. Původně jsem chtěl ještě vytvořit widget, který by uměl zobrazit poznámku a po klepnutí ji zobrazit celou v Poznámkovém bloku, ale bohužel na to už zase není prostor. Ale třeba se k tomu někdy dostaneme, widgety jsou celkem zajímavé :).
Nový ADT Plugin
Už jsem se o tom zmínil i minule, Google vydal novou verzi ADT Pluginu pro Eclipse. Dnes vám jednak ukážu, jak updatovat, a jednak poskytnu aktualizovaný návod, jak vytvořit nový projekt.
Jak aktualizovat?
Spusťe Android SDK Manager ( Window → Android SDK Manager) a aktualizujte všechno ve složce Tools. Až se to podaří (možná bude potřeba restartovat Eclipse), klikněte na Help → Check for updates a updatujte. Po restartu Eclipse máte ADT Plugin v20.
Jak vytvořit nový projekt?
Velká změna je v průvodci vytvoření nového projektu. Je mnohem příjemnější.
Chcete-li vytvořit nový projekt, klikněte na File → New → Project → Android Application Project. vyskočí vám takovéhle okno:

Nejdříve si všimněme (většinou) modrých ikonek vlevo vedle vstupních políček. Po najetí myší na některou z nich se zobrazí nápověda pro dané políčko.
Do Application Name přijde jméno aplikace, které chcete, aby se zobrazilo třeba v Play Store.
Do Project Name patří jméno projektu – to se zobrazí jen v Eclipse v seznamu projektů. Většinou budou tato dvě jména asi stejná (obě můžete případně kdykoli změnit).
Package Name se vyplnilo samo, tak jak jste vyplňovali jméno aplikace. Pokud jen něco zkoušíte, můžete package name takové nechat. Kdybyste ale chtěli aplikaci zvěřejňovat, místo com.example dejte nějakou vaši url, kterou určitě nikdo jiný na světě nepoužije.
Build SDK je verze Androidu, na níž se bude aplikace kompilovat. Já volím vždy tu nejvyšší, v tomto seriálu dělám výjimku, neboť jsem začal, když byl nejnovější Android 4.0.3 – API 15 –, a tak to na něm chci také dokončit. V tipu tvrdí, že toto je buď nejvyšší možná verze, anebo naopak nejnižší, která obsahuje všechny pro nás důležité API. Otázce, co spíše zvolit, jsem se věnoval ve článku První krůčky.
Minimum Required SDK je nejnižší verze Androidu, na které aplikace běží. Na rozdíl od ADT pluginu v18 už ji můžete bezpečně nastavit bez toho, aby to způsobilo paseku. (Toto je důležité pro ty, co přicházejí z prvního dílu. Až vám budu v následujících článcích tvrdit, že máte v manifestu upravit Minimum SDK nebo něco takového, ignorujte mě.) Nižší než 4 nemá moc smysl, starší Androidy se v některých věcech chovaly zvláštně. Pokud použijete API 8, dostane se vaše aplikace na cca 93 % zařízení (a toto číslo stále roste) – alespoň pokud můžeme věřit tooltipu.
Na Minimum Required SDK je zatímavé také to, že Eclipse vás upozorní (ale mě upozorňuje často až po nějaké době), když používáte něco, co v nejnižší podporované SDK verzi ještě není.
Další novinkou je zaškrtávátko Create custom launcher icon. Dříve vám Android prostě přidělil jako výchozí ikonu zeleného Androida s krychlí na břiše. Teď máte možnost vytvořit si ikonu vlastní, kterou ADT plugin vytvoří ve všech potřebných rozměrech. Určitě se tím nedá vytvořit krásná ikona do Play Store, ale je to velmi šikovné u různých pokusných projektů, které potom lépe rozlišíte jeden od druhého.
Mark this project as a library a Create Project in Workspace nás teď nezajímají.
Klikněte na Next >.
Pokud jste zatrhli Create custom launcher icon, zobrazí se vám obrazovka s možností vytvoření ikonky, jako na následujícím obrázku.

Tam můžete buď vybrat obrázek z disku, nějaký klipart, anebo text. Dá se nastavit několik dalších věcí, s tím si určitě pohrajete a porozumíte tomu. Pro samotný projekt to není důležité (ve smyslu zda půjde spustit).
Po dalším kliknutí na Next >, anebo pokud jste nezaškrtli Create custom launcher icon, vás přivítá tato obrazovka:

Pokud jste přišli z prvního dílu, tak vás tahle obrazovka vůbec nezajímá, nechte zvolené BlankActivity a klikněte na Next >.
Pokud máte ale za sebou už díl o fragmentech, vězte, že MasterDetailFlow vytvoří kostru „fragmentové” aplikace, tzn. dva sloupce pro větší displeje, jeden sloupec pro menší. Problém ale je, že nepoužívá Support library, takže musíte mít nastavené minimální API na 11.
Vybrali jsme BlankActivity a klikli na Next >. Tam nás přivítala zase jiná obrazovka.
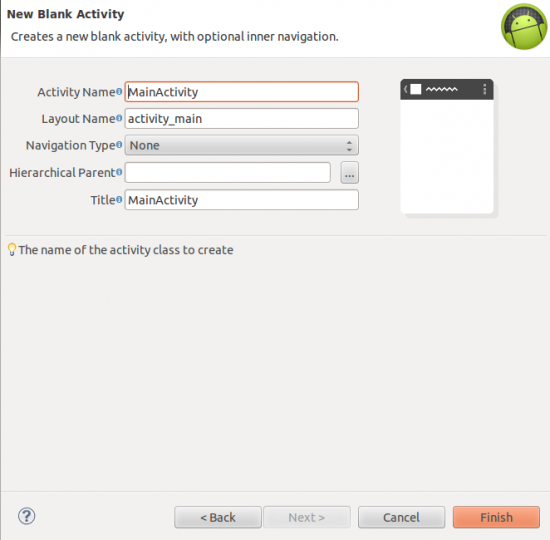
Tam nás zajímají jen tři položky. (A vy, co přicházíte z prvního článku, zatím nebudete rozumět ani těm.)
Activity Name určije název třídy dané Activity. Určitě by měl končit na Activity.
Layout Name definuje název layoutu, který se pro vytvořenou Activity vyrobí. Vy prvočlánkaři budete v následujících článcích narážet na to, že vám říkám něco o /res/layout/main.xml. Ve starší verzi ADT se totiž právě takhle jmenoval na začátku vytvořený layoutový soubor. Dnes si ho už můžete pojmenovat, jak chcete.
Title určuje název Activity, který se zobrazí v jejím titulku a také v seznamu aplikací. Často bude stejný jako název celého projektu (nebo snad chcete, aby se vám v launcheru zobrazilo MainActivity, přestože jde o poznámkový blok?).
Klikněte na Finish a máte vytvořený projekt. S prvočlánkaři se loučím.
S ostatními se ještě podělím o jeden svůj postřeh. Protože mám Support library přes Android SDK Manager stáhnutou, nový vytvářeč projektů mi ji automaticky do každého projektu přidává. I kdyby ten projekt měl minimální verzi API 16.
Závěr
Dnes jsme si představili content providery. A zdaleka jsme neobsáhli všechno. Je poměrně jednoduché zařídit, aby se AdapterView automaticky obnovilo při změně dat v content provideru (my to řešili opětovným voláním metody fillListView()). Cursory by určitě bylo šikovnější získávat asynchronně. Zajímavé jsou dočasné (temporary) permissions.
Zdrojové kódy dnes vytvořených a upravovaných aplikací jsou k dostaní tady.
Tip na konec
Pro ty, které napadlo vytvořit content provider, který by data získával a vracel z nějaké databáze či API na internetu, mám vzkaz: Nedělejte to. Content provider, jehož funkčnost závisí na připojení k internetu, je špatný (a ještě k tomu pomalý). Buď nabídněte přidanou hodnotu (data průběžně synchronizujte, ale vždycky mějte kopii i offline na telefonu), anebo se na content provider úplně vykašlete a nabídněte webovou API. Je dobré, když uživatel content provideru ví, s čím pracuje.
Matěj Konečný
Matěj začal programovat ve třinácti v PHP, pak v JavaScriptu a Lispu. Nakonec si koupil Androida, a tak programuje hlavně pro něj.


Hlavně vydrž.
Pár nepřesností, kvůli kterým se Eclipse nechová přátelsky:
– třída NotesContract by měla být static
– definujete NOTES_ID = 1; ale používáte NOTE_ID
I já se připojuji k přání dlouhopsavosti.