Architektura našeho systému: Angular, Event sourcing a CQRS

Aktuálně vyvíjíme nový video ad server. Plus minus je to systém, pomocí kterého můžete zadávat reklamní kampaně, které se pak budou zobrazovat ve video přehrávačích. V článku popíši, jaké technologie jsme použili a jak jsme je všechny zkombinovali do jednoho funkčního celku.
Nálepky:
Článek původně vyšel na autorově webu Programio.
Celý příběh začíná ve webovém UI/administraci, což je single-page aplikace napsaná v Angularu (promiň, Dane). Web reaguje s backendem přes AJAX na základě vzoru CQRS a backend samotný je postavený na základech Event Sourcingu.
Commandy a Queries
Veškerá interakce mezi webovým UI a backendem probíhá skrze Commandy a Queries:
- Query je ajaxový HTTP GET požadavek, který UI vypálí, když potřebuje zjistit nějaké informace z backendu. Query nikdy nesmí změnit stav systému, jen vrátit data. Typická Query může být Vrať mi seznam kampaní daného uživatele.
- Command je HTTP POST (PUT…) požadavek, který se pokouší změnit stav systému. Typický Command je Vytvoř novou kampaň nebo změň název kampaně. Commandy nikdy nevrací žádná data, v odpovědi máme jen jednoduchý indikátor toho, jestli se Command podařilo zpracovat, nebo jestli nastala chyba.
Některé důsledky předchozích dvou bodů:
Optimistic UI
Pokud vypálíme nějaký Command, předpokládáme, že uspěje. Přejmenuje-li uživatel kampaň, my vypálíme správný Command, ale v UI už všude ukazujeme nové jméno bez ohledu na to, jestli Command na backendu prošel, nebo neprošel. Říká se tomu Optimistic UI updating. Výsledkem je, že UI reaguje okamžitě na akce uživatele, rychlost odezvy backendu na to nemá vliv.
Pokud ale Command na backendu opravdu selže, musíme nějak zareagovat v UI, nemůžeme se celou dobu tvářit, že se název kampaně změnil, i když se ve skutečnosti na backendu nezměnil. Tohle je obecně těžký problém, protože to selhání může nastat třeba až za deset sekund a během té doby už uživatel mohl přejít na jinou stránku a mohl udělat několik dalších akcí. Nemáme to dobře vyřešené pro všechny případy a ještě s tím asi budeme bojovat.
Protože nemáme úplně ideálně vyřešené undo akce Commandů, snažíme se alespoň provádět co nejvíce validací přímo v UI, abychom na backend nepálili Commandy, které jistě neprojdou byznys logikou na backendu. Má-li být zadaná cena kladná, nedovolíme odeslat Command se zápornou cenou. Samozřejmě to ale nikdy nebude stoprocentní, když už nic, tak backend může spadnout.
Performance
Protože Commandy nevrací žádná data a předpokládáme, že projdou, není potřeba, aby jejich zpracování bylo extrémně rychlé. To má za následek, že si při jejich zpracování můžeme dovolit provádět více činností a celkově nemusí být celý kód kolem zpracování Commandů optimalizovný na rychlost. Což je v naprostém protikladu se zpracováním Queries, na které naopak uživatel čeká. Query posíláme, když potřebujeme z backendu zjistit nějaké informace, proto se naopak snažíme, aby zpracování Queries bylo co nejrychlejší.
Generování IDéček
Zajímavá situace nastane, když v UI vytváříme novou kampaň. Člověk by asi čekal, že když pošlu požadavek na vytvoření nové kampaně, backend mi v odpovědi vrátí ID této kampaně, abych ji mohl dále adresovat. Jenže naše Commandy nevrací žádná data. Vyřešili jsme to tak, že ID nově vzniklé kampaně se už posílá v samotném Commandu. V rámci POST požadavku na vytvořením nové kampaně pošleme i její ID. Používáme UUID v4, takže máme prakticky garantované, že toto vygenerované ID bude unikátní. Webové UI zkrátka vygeneruje nové UUID a pošle ho backendu, který případně může zkontrolovat, jestli už dané ID není použito.
Event sourcing
Další buzzword, který máme na skladě, je event sourcing. Základní myšlenkou event sourcingu je, že hlavní databáze obsahuje historii všech změn, které uživatel v systému provedl a jedině od těchto změn se odvíjí stav systému. Historie změn = Single Source of Truth. Historie změn je už z principu neměnná, co se jednou stalo, nemůže se odestát. Přečte-li nějaká aplikace všechny změny, dostane aktuální stav systému. Těmto změnám pak říkáme Eventy neboli Události.
V praxi to u nás funguje takto: uživatel změní v administraci název kampaně, my vypálíme Command na backend, tam ověříme nějakou byznys logiku (dejme tomu jestli název není moc dlouhý) a pokud je vše v pořádku, vytvoříme Událost CampaignNameSet. Tuto Událost uložíme do Event Store, což máme aktuálně implementované jako kolekci v Mongu (v SQL světě by to byla prostě tabulka). V této kolekci máme uchované všechny Události, které kdy v našem systému nastaly. Událost je přitom jednoduchý JSON objekt, něco takového:
{
eventType: "CampaignNameSet",
entityId: "cf3f128e-5051-47fe-a961-da3e55422258",
datetime: "2015-09-27T06:26:51.312Z",
data: {
name: "Nový název kampaně"
}
}Těch dat je tam ve skutečností více, ale to je teď jedno. A proč používáme zrovna Mongo? Potřebovali jsme databázi, která obstojně zvládá replikace a shardování a umí dobře pracovat s JSONem. Mongo to tehdy umělo asi nejlépe.
Instancování entit při zpracování Commandů
Při zpracování Commandu potřebujeme znát aktuální stav systému, abychom mohli vyhodnotit všechna pravidla. Při zpracování Commandu na přejmenování kampaně bychom mohli kontrolovat dvě pravidla: jestli není název moc dlouhý a jestli se liší od předchozího názvu – nemá smysl přejmenovávat kampaň na stejný název. Kód by mohl vypadat přibližně takhle:
Campaign.prototype.handleSetCampaignNameCommand = function(command) {
if (command.data.name.length > 50) {
throw new Error("Campaign name is too long");
}
if (command.data.name !== this.name) {
produceNewEvent(Events.CampaignNameSet, {name: command.data.name});
}
}V command.data.name máme nový název kampaně. Aby tento kód fungoval, je nutné, aby v době zpracování Commandu byl v this.name aktuální název kampaně. Před samotným zpracováním Commandu proto tzv. instancujeme entitu kampaně, na které se Command provádí. To znamená, že z Monga vytáhneme všechny Události, které se týkají dané kampaně, a aplikujeme je na danou entitu. Aplikace Události není o nic složitější než předchozí handle metoda:
Campaign.prototype.applyCampaignNameSet = function(event) {
this.name = event.data.name;
}Pokud uživatel desetkrát přejmenoval danou kampaň, vyvolá se desetkrát metoda applyCampaignNameSet a desetkrát se přepíše hodnota this.name. Na konci zpracování ale budeme mít entitu v aktuálním stavu (taháme všechny Události, ne jen CampaignNameSet), což je to, co chceme.
V tuto chvíli můžeme začít zpracovávat command samotný, tzn. že v tuto chvíli zavoláme předchozí metodu handleSetCampaignNameCommand, ve které se už můžeme kvalifikovaně rozhodnout, jestli vypálíme Událost CampaignNameSet nebo jestli to nemá smysl.
V případě nutnosti si můžeme instancovat další entity. Toto instancování entit není zrovna nejrychlejší operace, ale můžeme využít faktu, který jsme uvedli výše – zpracování Commandů nemusí být superrychlé. V současnosti platí, že vytvoření aktuální instance entity = dotaz do Monga na Události pro tu danou entitu, ale až to bude moc pomalé, dá se to relativně jednoduše cachovat.
Má-li vzniknout Událost, musí to být na popud nějakého Commandu. Není možné, aby vznikla Událost bez Commandu.
Transakční zpracování
Jeden Command může vyprodukovat více než jednu Událost. Příkladem může být třeba pausnutí kampaně. Pausne-li uživatel kampaň, vyvolá se pochopitelně Událost CampaignPausedSet, ale spolu s tím se vyvolá Událost CampaignRunnableStateChanged. CampaignRunnableStateChanged je Událost, která nám říká, jestli může kampaň běžet, nebo jestli je “něco špatně”.
Aby kampaň mohla běžet, musí mít nastaveno, kdy a kde má běžet a nesmí být pausnutá. Pokud splňuje všechny tři parametry, pak je i Runnable, pokud jeden z těch parametrů změníme, už není Runnable. Tím, že vypalujeme Událost CampaignRunnableStateChanged si ulehčujeme práci, protože všude jinde už nám pak stačí reagovat na tuto Událost a nemusíme nikde jinde vyhodnocovat logiku, jestli má kampaň všechny potřebné vlastnosti.
Aby vše fungovalo jak má, je nutné, aby se buď vyprodukovaly obě Události, nebo ani jedna. Proto všechny Události vyprodukované jedním Commandem ukládáme jako jednu transakci, tj. jako jeden Mongo objekt.
Queries a View Buildery
Zpracování Commandů sice nemusí být rychlé, ale zpracování Queries ano. Jak to řešíme? Držíme aktuální stav entit v Mongu v jiných kolekcích. Tyto kolekce jsou vytvářeny aplikacemi, které nazýváme View Builder. View Buildery čtou všechny Události a na některé z nich nějak po svém reagují; typicky aktualizují záznam v Mongu a vytvářejí specifické View. Důležité je, že nemáme předepsané, jak takové View má vypadat.
Každý View Builder může vytvářet View, které se hodí pro nějaký konkrétní specifický účel a dokonce je možné, abychom ve dvou různých Views měli prakticky stejná data jenom v jiné struktuře. Důležité je, aby View bylo optimalizované pro čtení. Příklad: máme Campaigns View, ve kterém máme uloženy všechny informace o všech kampaních (jeden dokument = jedna kampaň); včetně názvu. V jiném View máme zase uložená ID všech entit (kampaně, publishery, …) a jejich názvy, nic víc. Toto View používáme v reportech, protože tam máme na vstupu seznam IDéček a potřebujeme je rychle přeložit na lidská jména.
Kód View Builderů je opět velmi jednoduchý. Vlastně jen vytváříte apply metody těch Událostí, na které chcete reagovat:
CampaignViewBuilder.prototype.applyCampaignNameSet = function(event) {
return mongo.updateDocument(event.entityId, {name: event.data.name});
}
CampaignViewBuilder.prototype.applyCampaignCurrencySet = function(event) {
return mongo.updateDocument(event.entityId, {name: event.data.currency});
}A jak se View Builder dostane k novým Událostem? Řekli jsme si, že po zpracování Commandu se Událost pošle do Event Store. Kromě toho se ještě pošle na Event Bus a skrze něj se Událost dostane do všech View Builderů. Event Bus je implementovaný pomocí ZeroMQ (zkoušeli jsme i nanomsg). ZeroMQ není nic extra složitého, je to jen jednoduchý způsob, jak dostat zprávu z jednoho místa na druhé. Kdybychom celý event sourcing implementovali dnes, asi bychom místo ZeroMQ použili Kafku.
Naše typická Query je proto implementovaná tak, že se jen podívá do předzpracované Mongo kolekce, položí jednoduchý dotaz a vrátí výsledek.
Změna View
Důležitou výhodou je, že View je jen jiný pohled na Události z Event Store. Což znamená, že když se nám současné View nelíbí, můžeme ho změnit. Stačí jen resetovat View Builder a nechat ho znova přečíst všechny Události a naše View můžeme vypadat úplně jinak. Příklad z praxe: zákazník si může v našem webovém UI vytvořit portfolio, což je vlastně web + podsekce. Může to vypadat třeba takto:
idnes.cz
| Kultura
| Technet
| Web
| Věda
| Ekonomika
| ...
My jsme se tuto strukturu na poprvé snažili ve View uložit tak, jak ji vidíte. Tj. jeden dokument = celý web včetně všech podsekcí:
{
name: "idnes.cz",
nodes: {
kultura: { name: "Kultura", nodes: { ... } },
technet: { name: "Technet", nodes: { web: { ... } ... } },
ekonomika: { name: "Ekonomika", nodes: { ... } }
}
}Jenomže časem se ukázalo, že je to blbost a že by bylo lepší uložit to stylem jeden dokument = jedna sekce s tím, že bychom v každém dokumentu měli uložené IDéčka podsekcí. Tj. takto:
{ name: "idnes.cz", id: "187c48ce", nodes: ["846ed763", "3c33863f", "106ba878"] }
{ name: "Kultura", id: "846ed763", nodes: [...] }
{ name: "Technet", id: "3c33863f", nodes: [...] }
{ name: "Ekonomika", id: "106ba878", nodes: [...] }
...Přepsali jsme PortfolioViewBuilder, aby jinak reagoval na Události týkající se sekcí, přepsali jsme Query, která vracela strukturu portfolio a to bylo vše. Kompletně změnit strukturu dat, ze kterých taháme informace o portfolio, byla práce na dva dny i s testy…
Intermezzo
V souvislosti s touto změnou jsme přemýšleli, jak efektivně uložit informaci o portfoliu tak, aby bylo možné jednoduchým dotazem vrátit všechny sekce. V předchozí struktuře totiž platí, že idnes.cz ví jen o svých přímých potomcích, tj. o sekcích “Kultura”, “Technet” a “Ekonomika”. Že existují podsekce “Web” a “Věda” zjistíme až z dokumentu “Technet”. Existuje jeden hezký postup, jak jedním dotazem vrátit všechny své potomky, nehledě na úroveň, viz Model Tree Structures with Nested Sets. Celý princip je pochopitelný z obrázku, který si vypůjčím z odkazované dokumentace:
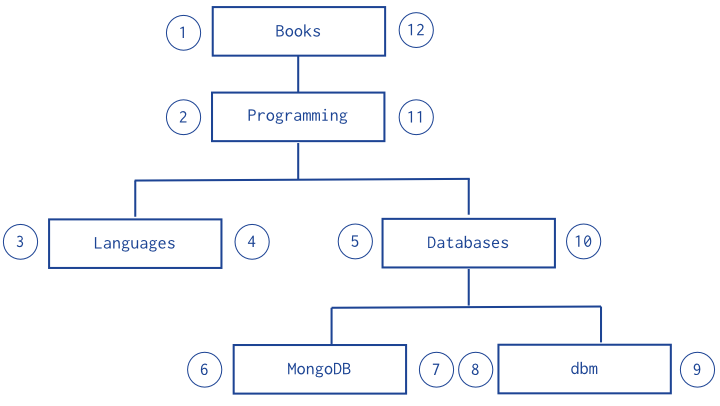
Každý uzel stromu si očíslujeme (projdeme strom do hloubky a očíslujeme jak je vidět z obrázku) a když chceme najít všechny potomky uzlu Programming, nalezneme všechny uzly, které mají levé číslo větší než 2 a pravé číslo menší než 11. To je celé. Dobré, ne?
Ale my jsme to nepoužili, protože nám stačí vždy vrátit celý strom, nepotřebujeme nikdy vracet část podstromu.
Eventual consistency
Command je považován za úspěšně zpracovaný, pokud se podařilo všechny vygenerované Události uložit do Event Store. Ve chvíli, kdy Události jsou v Event Store, nejdou už nijak odstranit, nejdou změnit – zůstanou v systému na věky věků. A naopak – pokud se Událost do Event Store nedostane, jako by se nic nestalo.
Jenomže když se Událost dostane do Event Store, tak to ještě neznamená, že se tato změna projevila ve všech částech systému. Někde vedle existuje View Builder, který čte tyto Události a reaguje na ně. Command ale nemá jak zjistit, jestli už na danou Událost reagovaly všechny View Buildery. Proto se může stát, že uživatel přejmenuje kampaň, Command úspěšně projde, uživatel refreshne webové UI a uvidí starý název kampaně. CampaignViewBuilder zkrátka ještě nestihl přečíst CampaignNameSet Událost a uložit do View aktuální stav.
Obecně proto platí, že Query nemusí vrátit aktuální stav systému, který platil v době, kdy byla Query přijata na backendu. Query vrací stav systému, který je uložený ve View a ten může být zpožděný oproti opravdovému stavu. Pokud bychom nějaký čas neprodukovaly žádné Události, tak by se View nakonec do skutečného aktuálního stavu dostalo, až by všechny View Buildery přečetly a zpracovaly všechny Události. Proto se tomuto principu říká Eventual consistency.
Teoreticky bychom mohli zařídit, aby Query vrátila aktuální stav systému. Museli bychom ale Query implementovat tak, aby se nikdy nedotazovala View, ale aby vždy instancovala entity přímo z Event Store. Jenomže tím bychom se zbavili dvou výhod: bylo by to pomalejší a nemohli bychom si data přeskládat a předzpracovat pro konkrétní Query tak, jak zrovna potřebujeme. Celkově bychom tím řádově více zatěžovali Event Store a stal by se z něj ještě větší single point of failure.
Jedním z pricnipů CQRS je oddělení Read (=Queries) a Write (=Commandy) částí systému, takže by nebylo dobré je míchat.
Lukáš Havrlant
Pracuji ve firmě Internet Billboard jako Node.JS vývojář, píšu blog Programio, občas tweetuju.



ad generování ID: Proč tak přísně bazírovat na tom, že commad nevrací hodnotu? Stejně to není pravda – vrací status zda byl či nebyl úspěšný. Když můžu dodatečně revertovat provedení akce, může stejně dobře updatovat hodnotu ID. IMHO.
Command vrací pouze status zdali byl úspěšně přijat (HTTP 202 vs 5xx) , to nic neříká o úspěšnosti jeho zpracování, které je navíc asynchronní.
IMHO spracovanie nemusi byt nutne asynchronne, resp. nie vsetky spracovania musia byt synchronne/asynchronne. Tento pristup si si zvolil ty. Ale ako som uz pisal inde, mozno som len nepochopil tie clanky na webe ohladom CQRS :)
Command je pouze žádost, neví vůbec nic o tom jaké Eventy ve skutečnosti budou emitovány, tj. i nově vytvořené entity/aggregate ID. Command ID !== Entity/Aggregate ID. Je zřejmě, že pokud Command vrátí 5xx tak nikdy nebude zpracován, na druhou stranu pokud vrátí 202 tak to ještě automaticky nemusí znamenat jeho úspěšné provedení.
Ohladom tohto:
Si si isty, ze to je spravny pristup? Mozno pre ten marketingovy system je to ok, ale ak by kazda entita mala ulozenych tisicky eventov, tak by tento pristup nebol pouzitelny. Nie je lepsie udrziavat aktualny ‚snapshot‘ v nejakej relacnej DB? Mam pocit ze vsade to robia tak, ale mozno som aj nieco zle pochopil :) V takom pripade nacitanei entity znamena nacitanie jedneho riadku v DB.
Samozřejmě si nejsem jistý, zda je to správný přístup! Ale zatím je to přístup, který nám stačí. Je nám jasné, že časem stačit nebude, i my máme máme entity, které žijí dlouho (Customer) a časem tak i pro ně nevyhnutelně budou tisíce Událostí. Až to bude problém, tak to budeme řešit a nejspíš přidáme nějakou cache přímo tam, kde se ty entity instancují. Tzn., že když dnes instancuju Customera, uložím si jeho stav do paměti a když ho budu instancovat zítra, donačtu jen Události, které pro ni vznikly ode dneška. Ale je to jen pracovní neodzkoušený nápad.
Skôr by som to riešil tak, aby vždy ste mali nejaký záznam s aktuálnym snapshotom, kľudne aj v databáze. Proste sa vyberie tento dokument. Všetky tie eventy si samozrejme bokom ukladať a vytvoriť si logiku, ktorá ten snapshot vie kedykoľvek aktualizovať. Toto by ste si vedeli spúšťať kľudne aj na pozadí, alebo keď sa udeje nejaký event, ktorý tie data výraznejšie zmení a je proste nevyhnutné ten snapshot updatnúť.
Takto by sa využívali naplno všetky prednosti Vášho prístupu – stav aktuálnej entity odvodený od postupnej aplikácie všetkých modifikácii a zároveň aj jendoduchý prístup k aktuálnym dátam skrz jediný prístup k DB (za ideálneho stavu, že ten výsledný dokument obsahuje všetky hodnoty a už žiadne referencie).
Sám som raz podobný princíp použil (u mňa šlo len o sled +/- nejakého čísla, nič zložité) a bol som s tým mimoriadne spokojný.
Tyhle snapschoty tam máme (viz kapitola Queries a View Buildery), ale nepoužíváme je, když jde o něco tak důležitého, jako je instancování entit při zpracování commandů, tedy když vytváříme nové Události. Má to totiž několik nevýhod:
Když vždy poctivě načteme a aplikujeme všechny Události, tak zmíněné problémy nemáme. Snapshoty/View máme pro Queries, které mohou vracet data, která už nejsou v daném čase platná, tam nám to nevadí.
Zkus se podivat, jak to dela treba Axon Framework
http://www.axonframework.org/docs/2.4/repositories-and-event-stores.html#using-snapshot-events
Jak resite concurrency problemy? Co se napriklad stane, kdyz dva uzivatele budou editovat stejnou kampan a oba ve stejnou chvili odeslou commandy, prvni na pozastaveni kampane a druhy na smazani kampane. Predpokladejme, ze z pohledu business logiky by nemelo byt mozne pozastavit smazanou kampan. Jak ve vasi architekture resite to, aby se do event storu nedostal nejdrive „delete“ command a pak „pause“ command? Tedy aby v event storu nebyla kampan v nekonzistentnim stavu.
Na začátku zpracování commandu si zjistíme, v jaké revizi je daná entita, to je nějaké číslo. Takže oba commandy by si třeba zjistili, že Kampaň má revizi 41. Do Event Store by se pak oba commandy snažily uložit Kampaň pod revizi 42 a to už se tomu druhému v pořadí nepodaří. Ten druhý command by se pak začal zpracovávat znova a už by věděl o tom předchozím commandu/eventu.
Moc pěkný článek ukazující CQRS v praxi, díky.
Můžu se zeptat, co bylo důvodem pro použití CQRS a ES? Znám několik důvodů, proč to používat, ale v této aplikaci mi to nějak nesedí. Pokud jsem to pochopil, tak jde o víceméně CRUD systém s ne zrovna multi-user collaborative environmentem. Jaký byl problém, který jste tím chtěli řešit a jestli jste si spíš nepřidělali práci?
Viz vlákno u mě na blogu: http://programio.havrlant.cz/architektura-event-sourcing/#comment-2364618825
Znáš CouchDB? Proč jste nepoužili ji? Řeší stejné problémy a navíc přesně tak, jak popisuješ. Data ukládá jako event stream, kolize řeší přes version, má podporu view přes map/reduce. Navíc byste měli zdarma PouchDB pro mobilní užití. Zdá se mi, že takhle jste zbytečně programovali něco, co už je naprogramované.