Pub-Sub a WebHooks: Máme pro vás čerstvé zprávy!
Zajímá vás, co je to PubSubHubbub? A víte, že to má něco společného s RSS? Syndikace obsahu a formáty jako RSS a Atom jsou tu s námi už nějaký čas. Nejčastější způsob jejich použití vlastně poněkud obrací tok informací a simuluje Push model v převážně pull médiu, jakým je web. S rozvojem webu vznikají i nové techniky, s nimiž je ona simulace Push modelu komfortnější.
Nálepky:
Současný web je poněkud pasivní médium – tedy v tom smyslu, že sám od sebe necpe uživateli žádné informace, uživatel si o ně musí říct (Pull model – „uživatel táhne data ze serveru“). Jsou ale situace, kdy by se hodil spíš aktivní Push model („Server tlačí data uživateli“) – např. u IM služeb, u nejrůznějších notifikací apod. Internet to řeší otevřenými spojeními, UDP tunely apod. Pokud ale zůstaneme ve světě WWW, nezbyde nám, než Push simulovat pomocí Pull technik. Škála sahá od naivní „heartbeat“ implementace, která se neustále dotazuje serveru „Nechceš mi něco říct?“, až po poměrně vyspělé metody, které jsou po většinu cesty „Push“, a až na poslední míli k uživateli se mění na „Pull“ (a heartbeat).
Na úvod se musím přiznat – když jsem poprvé četl název „PubSubHubbub“, byl jsem uhranut jeho zvukomalebností; připomíná skoro nějaké temné šamanské zaříkávadlo. Pojďme si společně rozkrýt tajemství této magické formulky, uvidíte, že v tom žádná mystika není.
Syndikace
Začneme od Adama, či spíše od Atomu a RSS. Tyto dva formáty zná snad každý. Slouží k publikování stručného výtahu obsahu webové stránky v normované podobě, která je snadno strojově zpracovatelná (jsou založené na XML, resp. na POX). (Pro přesnost dodejme, že Atom není jen jiné RSS, ale že je to formát, používaný spolu s RESTful rozhraními či XML-RPC API např. i pro publikování textů.)
Zaběhnutá praxe je taková, že vždy, když na webu přibude nový text, je vygenerován i nový soubor s RSS daty (nebo Atom, samosebou – dál budu pro jednoduchost psát o obou formátech jako o „RSS“, pokud bude třeba odlišit RSS od Atomu, výslovně na to upozorním), který obsahuje metadata k posledním deseti (pěti, dvaceti, padesáti – jak který web) článkům. Pod pojmem RSS metadata jsou míněny informace o čase vydání, titulku článku, autorovi, odkazu, unikátním ID atd., včetně stručného shrnutí, nebo dokonce i celých článků. Nemusíme tedy v prohlížeči prolézat web a hledat, co se píše, stačí si stáhnout krátký RSS soubor a podívat se jen na to, co nás zaujme.
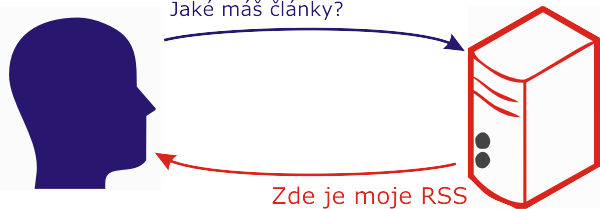
Což je sice fajn, ale nás zajímá spíš něco jiného – Co je nového? Naštěstí jsou takto publikované informace snadno strojově zpracovatelné, takže můžeme přenechat nudnou práci strojům. Stroje to ovšem řeší primitivně a hrubou silou:

Z výsledku pak tipnou, co už četli a co ne, a to, co se objevilo poprvé, to je novinka! Nic inteligentního, že? Opravdu hrubá síla. A pokud jsou vaše stránky trochu navštěvovanější a vaši čtenáři netrpěliví, takže si stahují aktualizace co pět minut (extrémisti i každou minutu), tak to vypadá nějak takto:

Čili model známý jako Cimrmanovské jak jste na mně všichni mluvili… Není to ideální a zvyšuje to počet dotazů na server, a to poměrně významným způsobem. Řešení se objevilo hned několik.
Řešení…?
S jedním způsobem řešení přišlo samotné RSS 2.0 – pomocí informací ttl, skipHours a skipDays umožňuje specifikovat, jak dlouho od poslední aktualizace může být obsah cachován nebo ve které dny a ve které hodiny není třeba se dotazovat na aktualizace (např. můžete dát v RSS najevo, že v sobotu a neděli nic nového nevychází, takže v tu dobu nemá smysl RSS stahovat, nebo že od 20.00 do 06.00 taky nic nového nevyjde…) Problém je v tom, že ne každý web publikuje pravidelně, a taky v tom, že lecjaké čtečky tyto informace zkrátka nezohledňují.
Jiné řešení nabízí samotný HTTP protokol: Zkrátka oznámí, že se soubor od posledního požadavku nezměnil (HTTP kód 304 – Not Modified). Sice se tím nezbavíme marného dotazování, ale už se aspoň neposílají velké objemy dat. Problém je opět na straně čteček – některé z nich kašlou na posílání jakýchkoli informací, podle nichž by server poznal, kdy bylo to „minule“ (ETag, Expires, Cache-Control apod.), takže jim server dál a dál cpe ta samá data. Navíc některé redakční systémy generují RSS dynamicky při každém dotazu (oblíbená adresa „/rss.php“) a nedávají serveru ani šanci, aby cokoli cachoval či zjistil, že se obsah nemění. Obzvlášť touto vymožeností oplývají weby, které vydávají nejvýš jeden článek za týden.
Předchozí řešení trpí společným neduhem: Řeší problém na straně serveru, a pokud je na druhé straně neinteligentní čtečka, která se chová neslušně, tak jsou zcela k ničemu. Smutné je, že velká část webových čteček se chová přesně tak – v pravidelných intervalech pomocí nějakého ekvivalentu funkce wget (třeba cURL) tupě dokola stahují ze serveru RSS, ten rozparsují a nějak s ním pracují.
Inteligentnější autoři inteligentnějších čteček přišli na to, že podobný způsob stahování hrubou silou nesvědčí nejen serverům, ale ani čtečkám, a tak se snaží čtení optimalizovat, adaptivně upravovat intervaly mezi stahováním, sledovat chování jednotlivých zdrojů a přizpůsobovat se jim – a samosebou korektně používat obě předchozí metody, tedy zohledňovat skipHours, skipDates a ttl, a korektně pracovat s HTTP stavy.
Kulišácké řešení je použití nějakého proxyserveru, nejčastěji FeedBurneru. Tím se výše uvedené schéma promění – serveru se dotazuje pouze proxyserver, a uživatelské dotazy jsou přesměrovány na něj. Ne že by to nějak koncepčně či systémově řešilo výše uvedené problémy, jen je to zkrátka přehodí na někoho jiného:

Feedproxy mají i jiné výhody – umožňují snadněji sledovat statistiky, přizpůsobit výstup RSS zařízení, které k němu přistupuje, umožňuje snadno vkládat reklamu nebo zařídit třeba mailový odběr.
Ale přesto je to všechno takové polovičaté řešení – o novém článku na nějakém serveru se nedozvíme ve chvíli, kdy vyšel, ale až ve chvíli, kdy si naše čtečka vzpomene, že se na ten server podívá. Popřípadě když si nejdřív vzpomene feedproxy… V reálu to je za několik desítek minut, v extrémních případech až za několik hodin.
Ping a Web Hooks
Výše zmíněný problém má jedno jednoduché řešení, zvané prostě „Ping“. Princip spočívá v tom, že server oznámí odběrateli krátkou zprávou, že má nový obsah, takže je vhodná chvíle stáhnout si nový RSS.
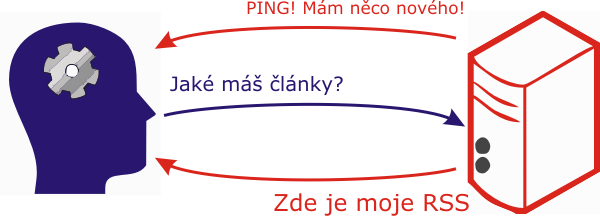
Vypadá to téměř ideálně, ale nevýhoda je jasná: Konzument zprávy musí být pro server nějak dosažitelný – musí mít tedy svou veřejnou IP. Sedí-li za anonymní proxy nebo za gateway, nemá server šanci ho nijak oslovit (vynechme prosím možnosti tunelovat UDP a podobné; zůstáváme u webových technik a TCP portu 80). Pokud navíc bude ve chvíli, kdy server posílá PING, třeba offline, tak se o novince nedozví. Podobné řešení tedy vyžaduje, aby příjemce byl veřejně dostupný.
Ping můžete použít i u výše zmíněných feedproxy systémů – na serveru vyjde nový článek a server upozorní (třeba) FeedBurner na to, že „něco vyšlo“. FeedBurner vzápětí stáhne RSS a nabízí ho odběratelům. Minimalizuje se tím časová prodleva mezi vydáním článku a jeho zpracováním proxy serverem.
Webový ping není nijak specifikován – nejčastěji se používá prostý HTTP GET dotaz na předem domluvenou adresu (tedy nikoli ICMP Ping). Zobecněním webového pingu vznikl mechanismus, známý jako Web Hooks.
Pojem „hooks“ se v programování používá spolu s pojmy jako „událost“, „ovladač“, „callback“ či „posluchač“ – tedy v oblasti zpracování asynchronních událostí. Systémy nabízejí aplikacím možnost „přihlásit se“ k události coby „posluchač“ a zaregistrovat svou vlastní obslužnou rutinu, kterou systém při vzniku události zavolá. („Prosímtě, až se objeví událost KLÁVESA STISKNUTA, zavolej mou metodu keyPress() a řekni jí, jaká klávesa to byla“) Jako by se aplikace „zaháčkovala“ k dané události. (Přesné termíny zde nejsou podstatné, jde spíš o ilustraci principu, nikoli o dohadování, jestli jde o Pozorovatele nebo Posluchače či o rozdílu mezi Událostí a Zprávou; pojmové puristy odkážu na terminologickou diskusi.)
Hook tedy umožňuje požádat o zaregistrování vlastní obslužné rutiny k dané události. Web Hooks pak aplikují tento princip na webové technologie. Jedná se o prostý HTTP POST callback, který webová aplikace vyvolá v případě, že došlo k dané události. Implementace Web Hooks tedy spočívá v možnosti zaregistrovat klientům jejich callback URL (a samosebou jej opět odregistrovat), a na tuto adresu poslat domluvený POST v případě, že se něco stane. Formát požadavku není nikde pevně specifikován, záleží na konkrétní službě – přesto je rozumné nevymýšlet kolo a držet se nějakého známého a používaného principu – např. REST (viz návrh RESTful Web Hooks).
Je na místě zmínit, že koncept callbacků a Web Hooks umožňuje nejen simulovat Push model, ale např. i implementovat pluginy, nebo dělat nejrůznější akce, které s šířením pingů nesouvisí – např. poslat zprávu o události mailem.
Hub
Termín Hub není určitě třeba nijak obšírněji vysvětlovat – je to zařízení, které slučuje víc připojení do jednoho, nebo naopak rozbočuje jednu komunikační linku do více přípojek (to podle směru, kterým se na hub díváme). Huby jsou známé především ze sítí nebo z USB.
Ve světě Web Hooks se termín „hub“ používá pro jakýsi „proxy hook server“ – tedy pro „retranslační server“, který distribuuje událost dál, podobně jako u sítí či USB. Hub je tedy velmi jednoduchá aplikace, která na jedné straně implementuje Web Hooks server, k němuž se mohou hlásit klienti a registrovat se, a na druhé straně se tváří jako klient, který je přihlášen k jinému serveru (nebo hubu).
Klienti se tedy nemusí registrovat k obsluze nějaké události přímo u zdrojové aplikace, ale u hubu, o němž ví, že danou událost pro daný server distribuuje. Umožňuje to, podobně jako výše popsaný příklad s feedproxy, snížit zátěž na aplikaci, která tak nemusí posílat třeba několik tisíc upozornění každému klientovi, ale stačí jí poslat několik stovek či desítek na registrované huby. Zlepšuje to distribuci zátěže a usnadňuje škálování.
Huby umožňují budovat opravdu bohatou topologii spojení, kde nemusí probublávat „všude všechno“ – některé huby se mohou zaměřit pouze na určité události („nový obsah“), některé se mohou naopak zaměřit třeba jen na určité servery („fotogalerie“), jiné mohou agregovat výstupy předchozích a filtrovat je („nové fotografie v galeriích“).
Pub-Sub
Princip Web Hooks můžeme naroubovat na výše probíranou problematiku RSS. Tu stranu, kterou jsme nazývali „server“, tedy tu, která poskytuje nějaký obsah, nazveme Publisher. Klient, příjemce informací, je v tomto případě Subscriber – tedy odběratel. (Zkratka Pub-Sub už není tak tajemná, že?) Událostí bude vydání nového článku; různé kategorie článků mohou představovat různé události, nebo doprovodnou informaci (tělo zprávy). Do výše naznačeného vztahu tak přibude jeden důležitý krok, totiž „přihlášení k odběru“ (ono nahození háčku):
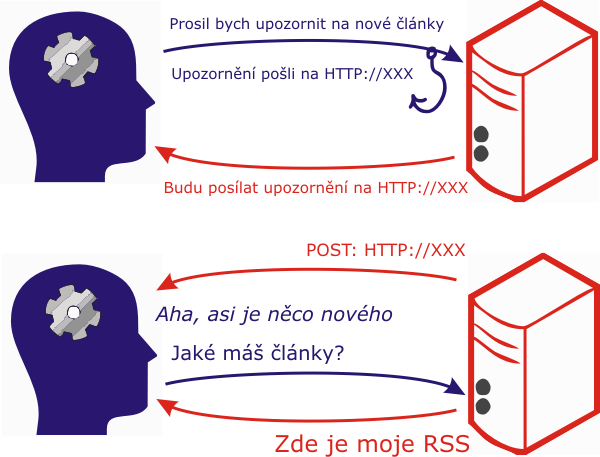
Když do tohoto modelu přidáme koncept hubů, dostáváme obří ekosystém, v němž je mezi producentem informací – publisherem a příjemcem – subscriberem síť vzájemně propojených a komunikujících uzlů (hubů). V síti některé uzly agregují informace z více zdrojů, jiné je naopak filtrují, další fungují jako zesilovače nebo distributoři, takže celý systém může být velmi variabilní. Pevný vztah mezi odběratelem a producentem informace je tak rozvolněn – už se nepřihlašujeme jen k odběru konkrétních serverů, ale můžeme se přihlásit k odběru určitých témat či určitého obsahu. (Ve zjednodušené podobě si lze představit, že nesledujeme přímo publikační servery, ale k nim i RSS agregátory témat, která nás zajímají.)
Tento model vztahů se nazývá Publisher/Subscriber, nebo zkráceně Pub/Sub, Pub-Sub, Sub-Pub atd.
PubSubHubbub
Abrakadabra! V tuto chvíli je jistě toto zaříkávadlo srozumitelnější: PubSubHubbub je protokol, navržený a prosazovaný Googlem, který především implementuje výše zmíněné postupy, tedy vztah Pub–Sub a huby pro události, do RSS a Atomu. Jeho specifikace (verze 0.3) říká, jakým způsobem do RSS doplnit informaci o tom, ke kterému hubu se lze přihlásit pro odběr informací (pomocí atributu rel="hub") a specifikuje, jak má probíhat přihlašování a komunikace mezi publisherem, odběratelem a hubem.
Na webu lze nalézt spoustu implementací hubů, publisher klientů i subscriber klientů, které jsou s PubSubHubbub kompatibilní. Existují i veřejně použitelné huby (např. FeedBurner používá pubsubhubbub.appspot.com – ve svém RSS kanálu z FeedBurneru jsem objevil tag <atom10:link xmlns:atom10="http://www.w3.org/2005/Atom" rel="hub" href="http://pubsubhubbub.appspot.com/" />).
Shrnutí
Zopakujme si tedy pointu celého příběhu: PubSubHubbub (a další Pub-Sub protokoly a specifikace, jako třeba RSS Cloud) simulují pomocí webových technik „Push model“ šíření zpráv, tedy takový, kdy server aktivně posílá klientům informaci o tom, že se něco stalo, na základě předchozí žádosti klienta, aby byl o těchto událostech informován.
Na místě je přirovnání k odběru mailového newsletteru, který nabízejí některé servery: Klient se přihlásí k odběru („subscribe“) a uvede svůj mail (analogicky s „callback URL“). Ve chvíli, kdy server má nějakou novinku („událost“), tak pošle zaregistrovaným odběratelům mail. Ten postupuje přes mailservery („huby“) až k poslednímu v řadě, odkud si jej uživatel stáhne (tedy Pull model na poslední míli).
Využití PubSubHubbub (a Web Hooks obecně) se neomezuje jen na RSS – lze jej využít jako obecný Push protokol. Psali jsme na Zdrojáku např. o řešení přihlášení pro několik serverů, které používá vlastní OpenID autoritu a k synchronizaci informací využívá právě interní implementaci PubSubHubbub.
Pokud vás zajímá podrobnější popis PubSubHubbubu a možnosti jeho použití, dozví se v dalším článku na toto téma. Chcete-li o Pub/Sub modelu (a o PubSubHubbubu) diskutovat, přijďte do Diskusního fóra.
Martin Malý
Začal programovat v roce 1984 s programovatelnou kalkulačkou. Pokračoval k BASICu, assembleru Z80, Forthu, Pascalu, Céčku, dalším assemblerům, před časem v PHP a teď by rád neprogramoval a radši se věnoval starým počítačům.



na GDC se mluvilo o tom, ze by pubsubhubub mohl interne nasadit i facebook, nemate nekdo nejake nove drby, jak je to daleko?