Představujeme Ring – HTTP server pro Clojure

Webový vývoj v Clojure je dobře etablovaný. Nebylo by to ale Clojure, kdyby si věci nedělalo trochu po svém. A tak nabízí, místo rozsáhlých aplikačních frameworků, množinu knihoven, které se dají pospojovat dohromady. Trochu to připomíná unixovou filozofii – malé, jednoúčelové prográmky, které lze propojovat do komplexnějších řešení.
Text vyšel původně na autorově blogu.
Když jde o web, tak jde v první řadě o HTTP. Clojure na to jde od podlahy a jeho odpovědí je Ring – „Clojure HTTP server abstraction“. Možná teď nebudu úplně přesný: Ring je Clojure implementací HTTP protokolu a zároveň je částečně kompatibilní s Java Servlety.
Ring vládne čtyřem komponentám
Každá Ring aplikace se skládá ze čtyř základních částí:
- Handler – funkce, která přijímá mapu reprezentující HTTP request a vrací mapu představující HTTP response.
- Request – mapa reprezentující HTTP request, která obsahuje sadu „standardních“ klíčů, které nám budou povědomé ze Servletu: :server-port, :server-name, :remote-address, :request-method ad.
- Response – mapa, představující HTTP response, která obsahuje tři klíče: :status, :header, :body.
- Middleware – funkce, která handleru přidá dodatečné funkcionality. Věci jako session, cookies, či parametry jsou řešené middlewarem.
Ring Hello, world!
Začneme tradičně, vytvořením Leiningen projektu:
$ lein new blog-ring
a v souboru project.clj doplníme dependency na Ring:
(defproject blog-ring "0.1.0-SNAPSHOT"
:dependencies [[org.clojure/clojure "1.8.0"]
[ring "1.6.0-RC2"]]
:main blog-ring.core)Dále upravíme soubor src/blog_ring.core.clj, aby obsahoval náš Hello, world handler. Přidáme také funkci -main, abychom mohli aplikaci rovnou spustit:
(ns blog-ring.core
(:require [ring.adapter.jetty :as jetty]))
(defn handler [request]
{:status 200
:headers {"Content-Type" "text/html"}
:body "<h1>Hello, world!</h1>"})
(defn -main []
(jetty/run-jetty handler
{:port 3000}))Aplikaci spustíme příkazem:
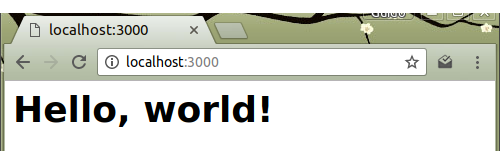
$ lein run
a můžeme si ji prohlédnout v browseru na URL http://localhost:3000.
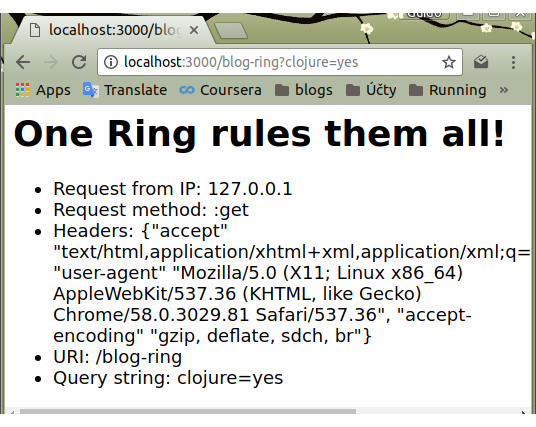
Request
Práce s requestem je přímočará – request je v Ringu prezentován mapou, takže stačí pomocí klíče vytáhnout požadovanou hodnotu a nějak ji zpracovat.
(defn handler [request]
{:status 200
:headers {"Content-Type" "text/html"}
:body (str "<h1>One Ring rules them all!</h1>"
"<ul><li>Request from IP: "
(:remote-addr request)
"</li><li>Request method: "
(:request-method request)
"</li><li>Headers: "
(select-keys
(:headers request)
["accept" "user-agent" "accept-encoding"])
"</li><li>URI: "
(:uri request)
"</li><li>Query string: "
(:query-string request)
"</li></ul>")})Předešlý handler nám vrátí následující stránku:
Response
V hello world příkladu jsme si celou response mapu sestavili sami. Ring nabízí řadu funkcí, soustředěných v namespace ring.util.response, které práci s response usnadňují:
(ns blog-ring.response
(:require [ring.util.response :as res]))
(def simple-res (res/response "Hello, world!"))
simple-res
;; -> {:status 200,
;; :headers {},
;; :body "Hello, world!"}
(res/charset simple-res "utf-8")
;; -> {:status 200,
;; :headers {"Content-Type" "text/plain; charset=utf-8"},
;; :body "Hello, world!"}
(def json-res
(res/response "{\"id\":1,\"content\":\"Hello, World!\"}"))
json-res
;; -> {:status 200,
;; :headers {},
;; :body "{\"id\":1,\"content\":\"Hello, World!\"}"}
(res/content-type json-res "application/json")
;; -> {:status 200,
;; :headers {"Content-Type" "application/json"},
;; :body "{\"id\":1,\"content\":\"Hello, World!\"}"}
(res/not-found "Ring not found!")
;; -> {:status 404,
;; :headers {},
;; :body "Ring not found!"}
(res/redirect "http://clojure.cz")
;; -> {:status 302,
;; :headers {"Location" "http://clojure.cz"},
;; :body ""}
(res/set-cookie simple-res "Clojurian" "Granted")
;; -> {:status 200,
;; :headers {},
;; :body "Hello, world!",
;; :cookies {"Clojurian" {:value "Granted"}}}Middleware
Tak, to bylo triviální. Co si teď střihnout nějaký middlewérek? Middleware je, podle definice, „funkce vyššího řádu, která přidává handleru dodatečné funkcionality. Prvním argumentem midddleware funkce je handler a její návratovou hodnotou je nový handler, který bude volat handler původní.“
Seznam standard middleware funkcí se dá najít na wiki stránce Ringu, nebo na stránce API (všechno co je ring.middleware).
Pro potřebu článku jsem si vybral dva middlewary:
- wrap-params, který rozparsuje parametry z formuláře a query stringu a přidá do requestu klíče :query-params, :form-params a :params
- wrap-keyword-params, který zkonvertuje stringové klíče v mapě :params na keyword klíče (protože všichni přece máme rádi keyword klíče v Clojure mapách).
Middleware funkce se dají dobře testovat pomocí funkce identity, kdy není potřeba funkci podstrčit celý handler a následně request, ale jen část (request) mapy, která nás z hlediska middlewaru zajímá.
Tady je ukázka, co s requestem dělají uvedené funkce wrap-params a wrap-keyword-params:
(ns blog-ring.middleware
(:require [ring.middleware.params :refer [wrap-params]]
[ring.middleware.keyword-params :refer [wrap-keyword-params]]))
((wrap-params identity)
{:query-string "clojure=yes&lisp=maybe"})
;; -> {:query-string "clojure=yes&lisp=maybe",
;; :form-params {},
;; :params {"clojure" "yes", "lisp" "maybe"},
;; :query-params {"clojure" "yes", "lisp" "maybe"}}
((wrap-keyword-params identity)
{:params {"clojure" "yes" "lisp" "maybe"}})
;; -> {:params {:clojure "yes", :lisp "maybe"}}Jak naznačuje definice, midddlewary jsou navržený tak, aby šly pospojovat za sebe. Je to v podstatě analogie Java (servlet) filtrů. Jak middlewary zřetězíme? Můžeme funkce jednoduše zanořit do sebe. Ale čitelnější, i používanější, je použití thread-first makra:
(def app
(-> handler
(wrap-keyword-params)
(wrap-params)))Kompletní kruh
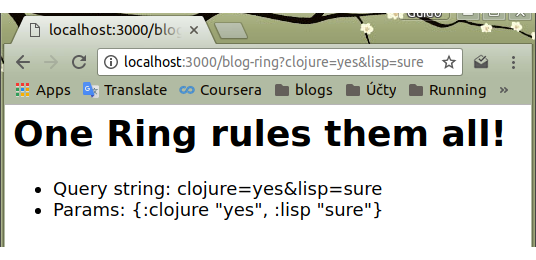
Tak, a jsme na konci. Probrali jsme všechny čtyři komponenty, ze kterých se Ring skládá – handler, request, response a middleware. Pokdu je všechny spojíme do jednoduché, spustitelné aplikace, může to vypadat takto:
(ns blog-ring.core
(:require [ring.adapter.jetty :as jetty]
[ring.util.response :refer [response]]
[ring.middleware.params :refer [wrap-params]]
[ring.middleware.keyword-params :refer [wrap-keyword-params]]))
(defn handler [request]
(response
(str "<h1>One Ring rules them all!</h1>"
"<ul><li>Query string: "
(:query-string request)
"</li><li>Params: "
(:params request)
"</li></ul>")))
(defn -main []
(jetty/run-jetty (-> handler
(wrap-keyword-params)
(wrap-params)))
{:port 3000}))A výsledek v browseru:
GitHub projekt
Pokud vám výše popsané principy neštymují dohromady, mrkněte na GitHub, kde je malý spustitelný projektík:
Vít Kotačka
Poslední roky píšu micro-services v Golangu pro cloudovou infrastrukturu. Předtím jsem (sekvenčně) programoval 2 roky v JavaScriptu, 3 roky v PHP a 12 let v Javě. Paralelně k tomu jsem 8 let fungoval jako Team/Technical Leader. Píšu technologický blog SoftWare Samuraj, kde se věnuji různým aspektům z oblasti SW engineeringu.



V clanku pisete o Clojure, ale nadpis mate Closure co je ale Google kniznica pre web (https://developers.google.com/closure/library/).
Opravte si to prosim.
Přehmat. Diky.