Git fork synchronizace

Už po několikáté jsem musel vzpomínat, jak správně synchronizovat forknutý repozitář z GitHubu. Znáte to také? Nejspíš ano. Pojďme si postup připomenout společně.
Text vyšel původně na webu autora.
Proč je synchronizace potřeba?
V případě, že se jedná o jednorázovou kontribuci, není potřeba synchronizaci řešit. Postup je většinou následující:
- Fork původní repozitory.
- Klon forknuté repozitory.
- Lokální změny a push do forknuté repozitory.
- Pull request do původní repozitory.
- (Případně) Opakování kroků 3-4.
- Akceptace pull requestu.
- Dobrý pocit. 😀 😎
Pokud se ale vaše kontribuce opakuje, už je potřeba synchronizaci řešit, protože pokud jste si pro přispívání nevybrali mrtvý (anebo hodně stabilní) projekt, tak na původním repo probíhá aktivní vývoj a během doby, kdy probíhal proces vývoje a akceptace vašeho prvního pull requestu, už tam nejspíš někdo nakomitoval další změny.
Jak vypadá proces synchronizace ?
V následujícím obrázku přibyly k výše popsanému postupu dva nové kroky: 5. fetch a 6. push. To je právě ona synchronizace.
V obrázku pak už chybí další, cyklicky se opakující kroky, tj. pro druhý pull request by ještě přibyl krok 7. pull request, pro třetí pull request by to byly kroky 8. fetch + 9. push + 10. pull request atd.
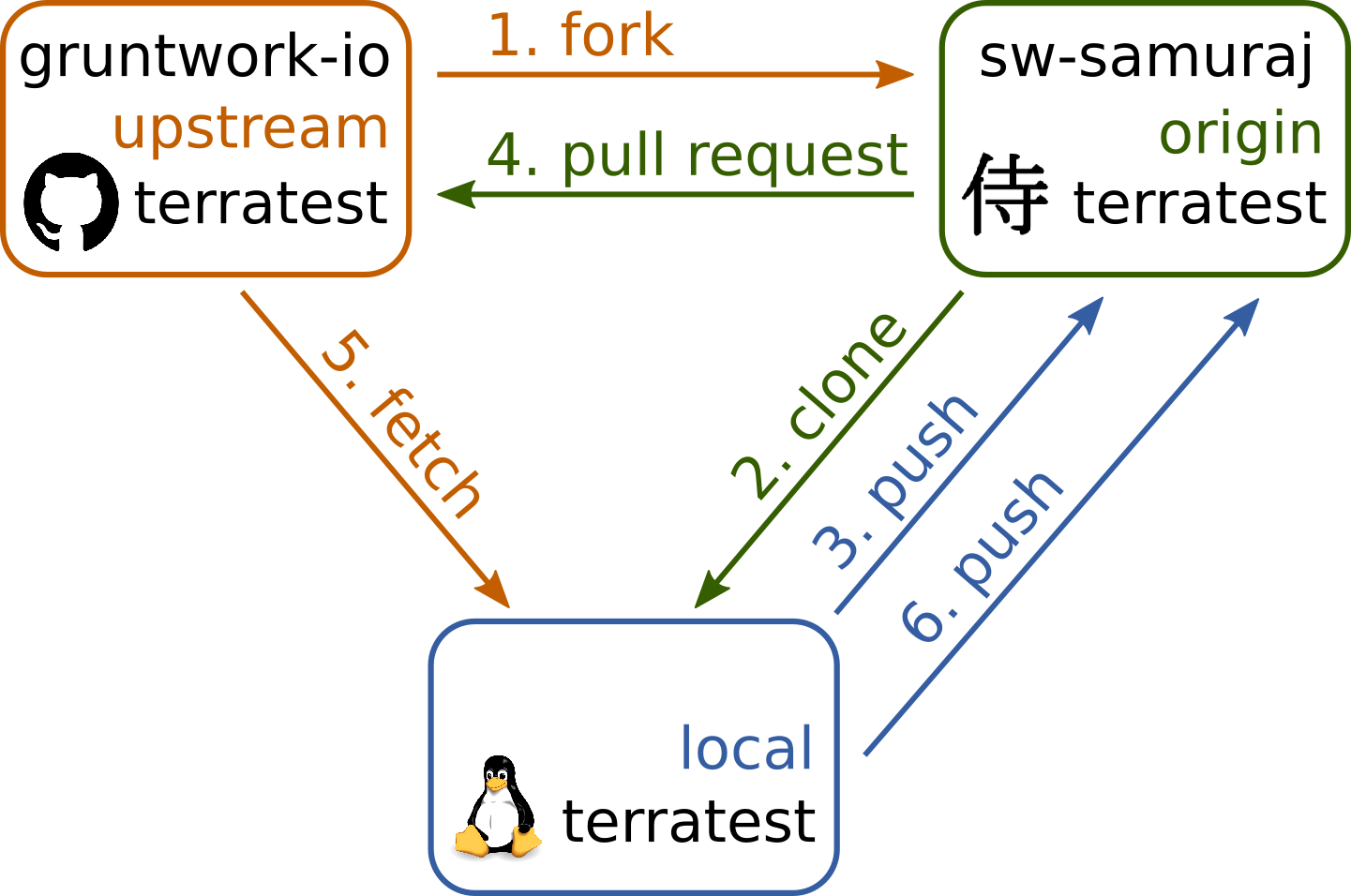
Schéma synchronizace mezi Git repozitory
Jak se to dělá v Gitu?
Předpokládám, že fork už máme udělaný. Pro potřeby tohoto příkladu použiju jako původní repozitory gruntwork-io/terratest, kterou mám forknutou jako sw-samuraj/terratest.
(Všechny následující příkazy si můžete bez obav pouštět u sebe lokálně. Pouze pokud byste chtěli zkusit i push, tak si samozřejmě musíte udělat svůj vlastní fork.)
Nyní si uděláme klon forknuté repo:
git clone git@github.com:sw-samuraj/terratest.gita vypíšeme si výchozí seznam remote repozitory:
$ git remote -v
origin git@github.com:sw-samuraj/terratest.git (fetch)
origin git@github.com:sw-samuraj/terratest.git (push)Přidání původního repozitory
Původní repozitory – většinou nazývanou upstream – přidáme příkazem:
$ git remote add upstream git@github.com:gruntwork-io/terratest.gitOpět si vypíšeme seznam remote repozitory a vidíme, že máme dvě:
originje náš nový fork.upstreamje původní repozitory,
$ git remote -v
origin git@github.com:sw-samuraj/terratest.git (fetch)
origin git@github.com:sw-samuraj/terratest.git (push)
upstream git@github.com:gruntwork-io/terratest.git (fetch)
upstream git@github.com:gruntwork-io/terratest.git (push)Stažení změn z původního repozitory
Samotná synchronizace se skládá ze čtyř kroků:
fetchzměn v původní repozitory (upstream).checkoutlokálního branche, kam chceme změny zpropagovat.mergedanéhoupstreambranche.pushdo forknuté (origin) repozitory.
$ git fetch upstream
$ git checkout master
$ git merge upstream/master
$ git pushJe jen na vás, jestli vaše změny uděláte před nebo po merge z upstream repozitory. Dobré pravidlo je udělat synchronizaci před zahájením práce na novém pull requestu.
A to je vše. Happy contributing!
Vít Kotačka
Poslední roky píšu micro-services v Golangu pro cloudovou infrastrukturu. Předtím jsem (sekvenčně) programoval 2 roky v JavaScriptu, 3 roky v PHP a 12 let v Javě. Paralelně k tomu jsem 8 let fungoval jako Team/Technical Leader. Píšu technologický blog SoftWare Samuraj, kde se věnuji různým aspektům z oblasti SW engineeringu.



Proc misto fetch+checkout+merge neudelat proste pull? Podle me to bude mit stejnej efekt.
Jeste je teda potreba rict, ze po merge i pull muze bejt obcas potreba commit, pokud se tam resil nejakej konflikt…
Ano, dá se udělat
git checkout master→git pull upstream master. Je to jen otázkou osobní preference použítpull, nebofetch+merge(třeba z důvodů větší kontroly příchozích změn).Dobrým pravidlem je mít co pull request to (feature) branch. Potom je kontrola příchozích změn zbytečná, protože není třeba.