Jak OpenAI vyškálovala infrastrukturu pro 800 milionů uživatelů

Růst ChatGPT na stovky milionů uživatelů nebyl jen produktem silného marketingu a kvalitních modelů, ale především důsledně škálované infrastruktury. Jak se společnosti OpenAI podařilo obsloužit až 800 milionů uživatelů měsíčně s jádrem postaveným na PostgreSQL?
Nálepky:
Když se dnes mluví o růstu moderních internetových služeb, často se používají nadsázky. V případě ChatGPT ale čísla skutečně působí extrémně. Produkt společnosti OpenAI se během krátké doby dostal ke stovkám milionů aktivních uživatelů měsíčně. Analýza publikovaná na ByteByteGo popisuje, jak se infrastruktura postupně přizpůsobila provozu odpovídajícímu přibližně 800 milionům uživatelů. Zásadní přitom je, že významnou roli sehrála klasická relační databáze PostgreSQL.
Tento příběh je zajímavý právě tím, že se nevydává cestou technologického „humbuku“. Nejde o okamžité nahrazení všeho distribuovanými NoSQL systémy ani o radikální architektonický zlom. Jde o systematické škálování, důslednou optimalizaci a velmi opatrné přidávání komplexity.
Explozivní růst a jeho technické důsledky
Růst uživatelské základny u ChatGPT nebyl lineární. S každým novým modelem, funkcí nebo rozšířením API přicházely další vlny zájmu. Pro infrastrukturu to znamenalo prudké nárůsty provozu, které nebylo možné řešit pouze horizontálním přidáváním aplikačních serverů.
AI aplikace má specifický profil zátěže. Každý uživatelský dotaz typicky zahrnuje:
- ověření identity a autorizaci
- kontrolu kvót a tarifních limitů
- načtení historie konverzace
- zápis nové zprávy
- uložení metadat
- práci s tokeny a billingem
- telemetrii a logování
Databáze je přítomna téměř v každém kroku. Pokud by se stala úzkým hrdlem, celý systém by se zpomalil bez ohledu na to, jak výkonná je výpočetní vrstva modelů.
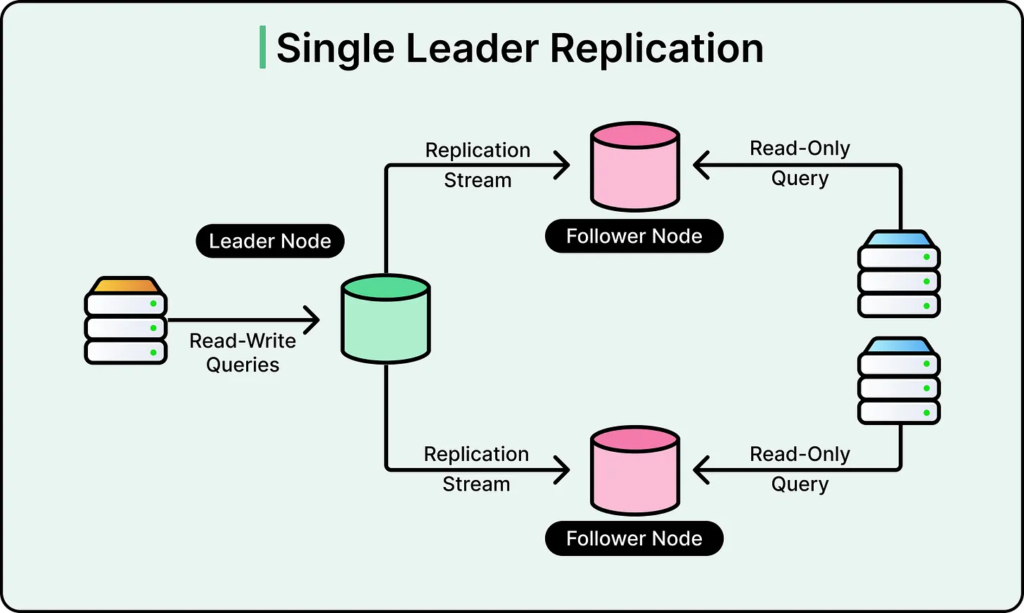
Jeden primární uzel jako srdce systému
Základní architektura byla překvapivě konzervativní. Jeden primární PostgreSQL uzel zpracovával zápisy. K němu bylo připojeno velké množství read replik, které obsluhovaly čtecí dotazy. Tento model je dobře známý, ale málokdo by čekal, že může fungovat při měřítku stovek milionů uživatelů.
Primární uzel byl provozován v režimu vysoké dostupnosti. To znamená, že existovala připravená standby instance schopná rychlého převzetí role leadera. Replikace probíhala s minimálním zpožděním, aby čtení z replik zůstávalo dostatečně aktuální.
Díky oddělení zápisů a čtení bylo možné výrazně zvýšit propustnost systému. Velká část operací v aplikaci typu ChatGPT je čtecí – načítání historie, kontrola nastavení, zobrazování kontextu. Tyto operace se přesunuly na repliky, čímž se primární uzel odlehčil.
V některých obdobích běžely desítky replik napříč regiony. To umožnilo nejen škálování výkonu, ale také snížení latence pro uživatele v různých částech světa.
Proč nebyl sharding okamžitým řešením
Sharding bývá považován za logický krok při růstu systému. Rozdělení dat mezi více databázových uzlů umožňuje horizontální škálování zápisů. Přináší ale značnou složitost.
Jakmile jsou data rozdělena mezi shardované instance, komplikuje se:
- provádění dotazů napříč shardami
- migrace schémat
- zálohování a obnova
- řešení incidentů
- konzistence dat
OpenAI zvolila přístup, který lze shrnout jako „nejprve vyčerpejme možnosti jednoduchého řešení“. Dokud bylo možné škálovat pomocí replik, vertikálního posílení instance a optimalizace dotazů, nebyl důvod zavádět distribuovanou komplexitu.
Tento přístup snižuje provozní riziko. Jedna silná, dobře monitorovaná databáze je často předvídatelnější než deset shardů s různými problémy.
Optimalizace dotazů jako klíčový faktor
Při provozu v takovém měřítku se každý neefektivní SQL dotaz násobí miliony. Optimalizace proto nebyla jednorázová aktivita, ale trvalý proces.
Analyzovaly se pomalé dotazy, přidávaly se indexy a přepisovaly části aplikační logiky. Důraz byl kladen na minimalizaci počtu round-tripů mezi aplikací a databází. Pokud bylo možné spojit více operací do jedné efektivní transakce, udělalo se to.
Zvláštní pozornost se věnovala zápisům. Zbytečné nebo duplicitní zápisy byly eliminovány. Každý zápis totiž zatěžuje primární uzel, a tedy i replikační mechanismus.
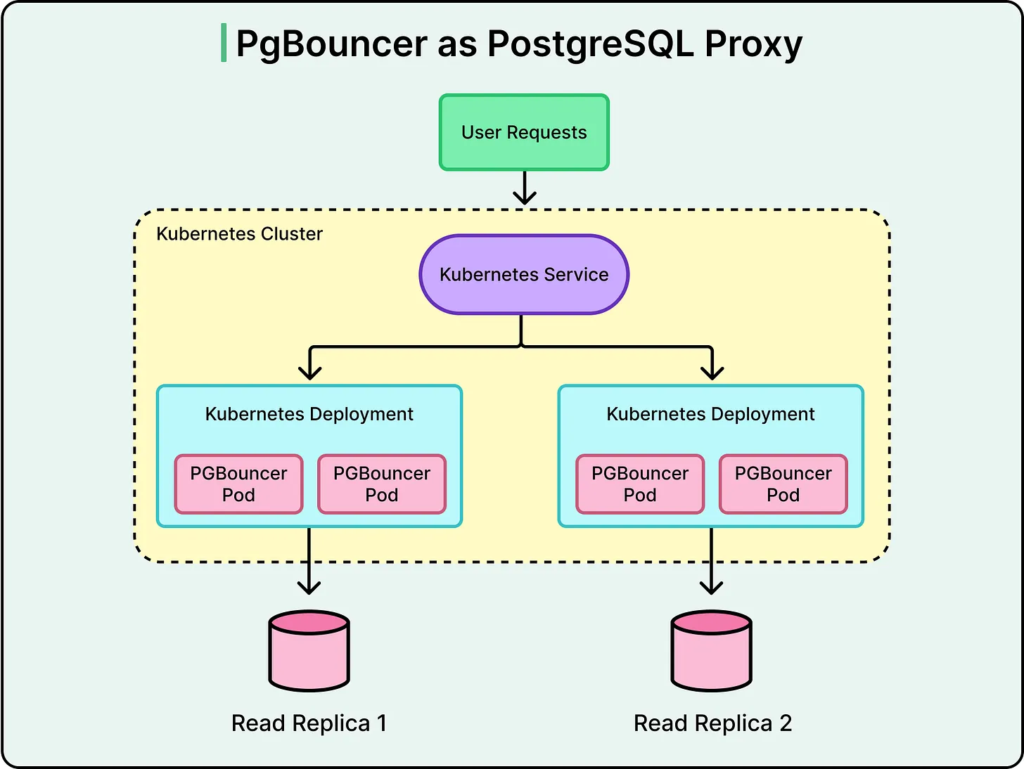
Connection pooling a stabilita při špičkách
Velkým problémem při masivním škálování je počet současných spojení do databáze. PostgreSQL není navržen pro desítky tisíc přímých připojení z aplikační vrstvy.
Řešením bylo nasazení nástroje PgBouncer. Ten funguje jako prostředník mezi aplikací a databází. Udržuje omezený počet persistentních spojení a aplikační požadavky nad nimi multiplexuje.
Tím se snižuje paměťová zátěž databáze a minimalizuje se režie spojená s navazováním a ukončováním spojení. V prostředí, kde každá milisekunda hraje roli, může optimalizace connection managementu znamenat zásadní zlepšení latence i stability.
Cache jako obranná linie
Cache zde neplní pouze roli akcelerátoru. Je to ochranný mechanismus proti přetížení. Pokud by došlo k náhlému výpadku cache nebo k expiraci často používaných klíčů, databáze by mohla být okamžitě zahlcena.
Proto se používají mechanismy zabraňující tzv. cache stampede efektu. Pokud vyprší určitá položka, pouze jeden proces ji obnoví z databáze, zatímco ostatní čekají nebo pracují s dočasně starší verzí dat.
Tím se zabrání situaci, kdy tisíce paralelních požadavků najednou zatíží primární uzel. Cache se tak stává součástí strategie řízení rizika, nikoli jen výkonovou optimalizací.
Oddělení specifických workloadů
S růstem systému bylo zřejmé, že ne všechna data mají stejný charakter. Transakční data konverzací vyžadují jiný přístup než například telemetrie nebo analytické logy.
Postupně se proto některé write-heavy workloady přesouvaly do specializovaných systémů. Tím se snížil tlak na hlavní relační databázi. PostgreSQL tak zůstává zaměřena na klíčová uživatelská data, zatímco ostatní typy dat jsou obsluhovány jinými nástroji vhodnějšími pro vysoký objem zápisů.
Tento krok je důležitý, protože umožňuje zachovat jednoduchost jádra systému, zatímco okrajové části mohou být škálovány nezávisle.
Vysoká dostupnost a kontrolovaná degradace
V prostředí s takovým počtem uživatelů je nemožné spoléhat na to, že žádná komponenta nikdy neselže. Architektura musí být navržena tak, aby selhání jedné části nevedlo k dominovému efektu.
Primární uzel běží v režimu vysoké dostupnosti a je připraven na rychlý failover. Repliky umožňují pokračovat v obsluze čtení i v případě problémů s leaderem. Součástí systému jsou také limity a throttling, které při extrémní zátěži omezují méně kritické operace.
Cílem není absolutní bezchybnost, ale předvídatelné chování i v krizových situacích.
Co tento příběh znamená pro architekty
Případ OpenAI ukazuje, že škálování není primárně o výběru „nejmodernější“ technologie. Je o hlubokém porozumění stávajícímu systému, o měření, testování, předvídání a postupném zlepšování.
Relační databáze, která je často považována za tradiční řešení, může při správném návrhu a optimalizaci obsluhovat extrémní měřítko. Distribuované systémy mají své místo, ale jejich zavedení by mělo být motivováno skutečnou potřebou, nikoli módním trendem.
Důležitým ponaučením je také práce s komplexitou. Každá nová vrstva, ať už jde o sharding, další databázi nebo novou službu, zvyšuje nároky na monitoring, incident response i mentální kapacitu týmu. Pokud lze problém vyřešit optimalizací existující vrstvy, bývá to často bezpečnější cesta.
Škálování na 800 milionů uživatelů tedy není jen technickým úspěchem. Je to ukázka inženýrské disciplíny. Místo dramatických architektonických revolucí proběhla série pečlivých, daty řízených rozhodnutí. Výsledkem je infrastruktura, která zvládá extrémní zátěž, aniž by se stala neřiditelně složitou.
Zdroje:
https://openai.com/index/scaling-postgresql/
https://blog.bytebytego.com/p/how-openai-scaled-to-800-million
Adam Heglas
Student se zájmem o IT, programování a kybernetickou bezpečnost. Baví mě se učit novým věcem a posouvat své schopnosti dál. Když zrovna nesedím u kódu, věnuji se fitness a počítačovým hrám.



… reposted this!