OpenAI představil GPT-5.3-Codex-Spark
Společnost OpenAI dnes oznámila uvedení nového modelu GPT-5.3-Codex-Spark, který je určený pro reálné programování v reálném čase v prostředí Codex.
Nový model je menší a optimalizovaný pro nízkou latenci, takže dokáže generovat více než 1000 tokenů za sekundu a okamžitě reagovat na pokyny vývojáře. To znamená, že lze rychle iterovat úpravy kódu, měnit logiku programů nebo ladit funkce téměř okamžitě.
Codex-Spark běží na specializovaném hardwaru Cerebras Wafer Scale Engine 3, který je navržený právě pro takto rychlé inferenční úlohy.
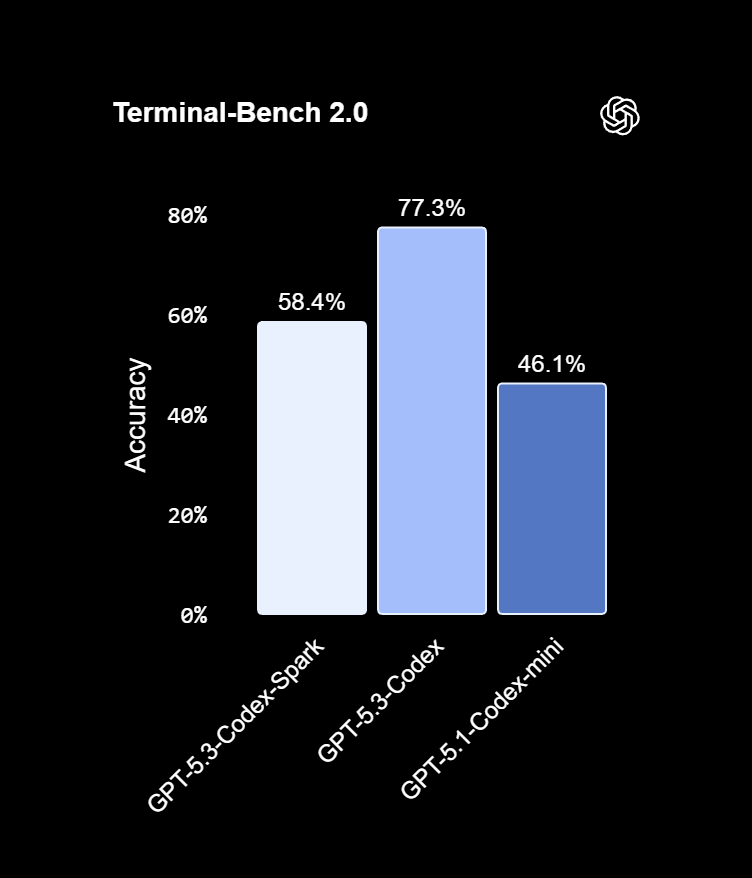
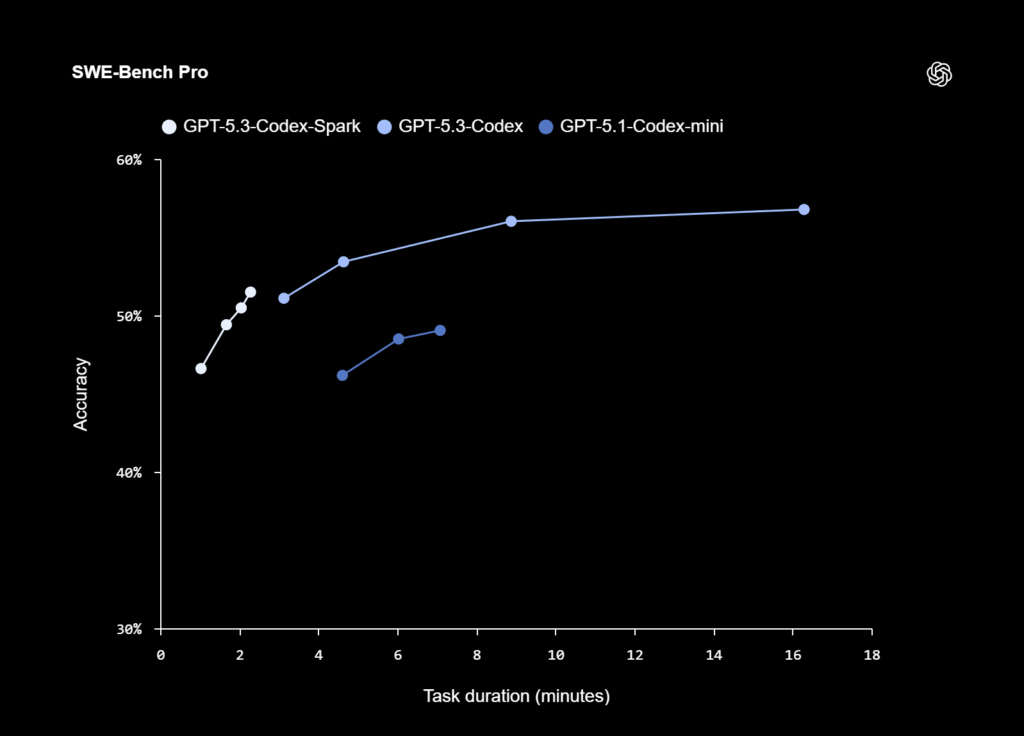
Model je nyní dostupný jako research preview pro uživatele s platným předplatným ChatGPT Pro v aplikaci Codex, přes rozhraní CLI i v IDE rozšíření VS Code.
OpenAI uvedla, že jde o první krok k systémům Codex, které budou kombinovat rychlé interaktivní reakce a hloubkové dlouhodobé úkoly v jednom prostředí tak, aby vývojáři mohli pracovat plynule bez čekání.
Pro více informací: https://openai.com/index/introducing-gpt-5-3-codex-spark/
Adam Heglas
Student se zájmem o IT, programování a kybernetickou bezpečnost. Baví mě se učit novým věcem a posouvat své schopnosti dál. Když zrovna nesedím u kódu, věnuji se fitness a počítačovým hrám.

