Stav SIMD v Rustu v roce 2025

SIMD – neboli Single Instruction, Multiple Data – znamená, že procesor může jednou instrukcí zpracovat více datových prvků najednou. Typicky to znamená, že místo sčítání dvou čísel přičtete dvě sady čísel paralelně. To může přinést výrazné zrychlení například při zpracování obrazu, audia nebo numerických výpočtů. Pokud již SIMD znáte, tato tabulka je vše, co budete potřebovat. A pokud s SIMD teprve začínáte, tabulku pochopíte do konce tohoto článku
SIMD – neboli Single Instruction, Multiple Data – znamená, že procesor může jednou instrukcí zpracovat více datových prvků najednou. Typicky to znamená, že místo sčítání dvou čísel přičtete dvě sady čísel paralelně. To může přinést výrazné zrychlení například při zpracování obrazu, audia nebo numerických výpočtů.
Pokud již SIMD znáte, tato tabulka je vše, co budete potřebovat. A pokud s SIMD teprve začínáte, tabulku pochopíte do konce tohoto článku
SIMD na různých architekturách
Na procesorech x86 existují sady instrukcí jako SSE, AVX, AVX2 nebo AVX-512, které umožňují zpracování 128, 256 nebo dokonce 512bitových vektorů.
Naopak u ARM64 je rozšíření NEON povinné, takže všechny 64bitové ARMy SIMD podporují. U novějších technologií jako SVE (Scalable Vector Extensions) se ale stále čeká na reálné rozšíření v běžném hardwaru.
Problém nastává, když chcete distribuovat binární aplikaci. Nemůžete totiž předpokládat, že všechny cílové CPU podporují stejnou sadu instrukcí. Na x86 musíte buď cílit na nejnižší společný jmenovatel (např. SSE2), nebo při běhu detekovat schopnosti CPU a podle toho spustit odpovídající kód.
Jak přistupovat k SIMD v Rustu
1. Automatická vektorizace
Nejjednodušší varianta je prostě spolehnout se na to, že LLVM kompilátor převede běžný kód na SIMD instrukce.
Funguje to překvapivě často, ale ne vždy. Například práce s desetinnými čísly (float) bývá problematická, protože kompilátor musí zaručit zachování přesnosti a asociativity operací. Kromě toho autovektorizace nefunguje, pokud kód obsahuje větvení nebo složité datové závislosti.
2. Fancy iterátory
Další úroveň představují knihovny, které používají iterátory nebo vyšší abstrakce, jež interně využívají SIMD.
Výhodou je, že kód zůstává čitelný, ale zároveň může být optimalizovaný. Nevýhodou je, že musíte spoléhat na konkrétní implementaci knihovny a nemáte jistotu, jak efektivně bude kompilátor generovat instrukce.
3. Přenosné SIMD abstrakce
Cílem je umožnit psát algoritmus tak, že operujete na blocích dat, například [f32; 8] zabalených do vlastního typu, a poskytovat vlastní implementace operací jako +, které se při kompilaci přeloží do SIMD instrukcí.
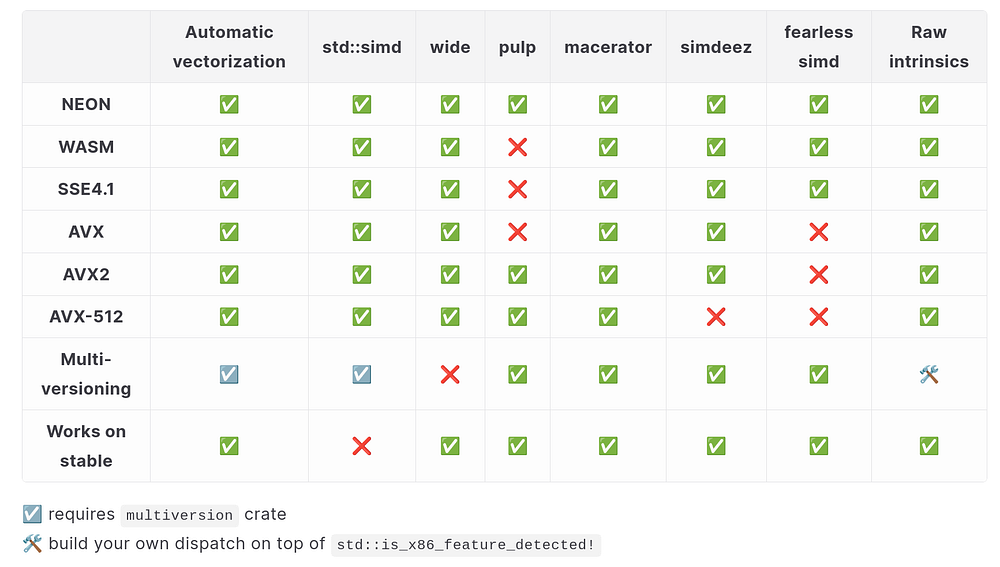
std::simd nabízí přesně tento přístup. Podporuje všechny instrukční sady, které zvládá LLVM, takže platformní podpora je špičková. Dobře spolupracuje s crate Multiversion, ale je dostupný jen v nightly Rustu, takže v praxi je většinou nepoužitelný.
Wide je známá a zavedená knihovna. Podporuje NEON, WASM a všechny x86 instrukční sady, ale nepodporuje multiversioning kromě velmi omezených přístupů, např. cargo-multivers.
Pulp má vestavěný multiversioning a je relativně zralý, používá se např. v faer, takže je výkonově ověřený. Omezení: pracuje jen s nativní šířkou SIMD, takže kód musí zvládnout proměnně široké bloky, a generické psaní pro různé typy (f32 i f64) vyžaduje částečnou duplikaci. Podporuje jen NEON, AVX2 a AVX-512; AVX2 má jen asi 75 % systémů podle Firefox hardwarového průzkumu.
Macerator je fork pulp s lepší podporou generického programování a širší podporou instrukčních sad (všechny x86, WASM, NEON, LoongArch SIMD). Používá se jen v burn-ndarray jako volitelná závislost. Na papíře skvělé, v praxi zatím neověřené.
Fearless_simd je inspirován pulp a podporuje i pevně veliké bloky dat jako std::simd a wide. Je méně zralý, ale aktivně se vyvíjí a podporuje NEON, WASM a SSE4.2. Novější x86 rozšíření zatím nepodporuje.
Simdeez je starší crate, podporuje všechny instrukční sady kromě AVX-512 a má vestavěný multiversioning. Přesto je málo používaný – většina vývojářů si SIMD řeší vlastní implementací. README uvádí, že je dobře pokryt pro typy i32, i64, f32 a f64.
Shrnutí
- Nightly Rust →
std::simd - Multiversioning nepotřebujete →
wide - Jinak →
pulpnebomacerator
4. Intrinsics
Pro maximální výkon je třeba psát přímo intrinsics – tedy volání konkrétních CPU instrukcí.
- Nutné je
unsafebloky, - ruční správa zarovnání a velikosti vektorů,
- různé verze pro různé CPU.
Praktický příklad: při kompilaci pro konkrétní CPU s konkrétní sadou instrukcí lze použít:
RUSTFLAGS='-C target-cpu=x86-64-v3' cargo build --releaseCode language: JavaScript (javascript)Tímto způsobem kompilátor optimalizuje kód pro zvolenou CPU, což může výrazně zvýšit výkon, pokud cílové stroje podporují danou instrukční sadu.
Problematické body
- Kompatibilita: moderní sady jako AVX-512 nemusí běžet na starších CPU.
- Nestabilní API:
std::simdzatím není stabilní. - Zbytky dat (remainders): délka pole často není dělitelná velikostí vektoru → nutný fallback.
Pozitivní stránky
- LLVM autovektorizátor je schopný generovat efektivní SIMD kód.
- ARM64 je jednodušší díky NEON.
- K dispozici jsou knihovny (
wide,packed_simd2,std::simd) pro přenosné vektory.
Závěr
SIMD v Rustu v roce 2025 je možný, ale ne triviální.
- Vývojář volí mezi jednoduchostí a maximálním výkonem.
- Ekosystém Rustu se zlepšuje: stabilizace
std::simd, multiversioning, lepší autovektorizace. - Rust se tak postupně blíží tomu, aby SIMD bylo přirozenou součástí jazyka, nikoliv jen doménou „unsafe“ programátorů.
Adam Heglas
Student se zájmem o IT, programování a kybernetickou bezpečnost. Baví mě se učit novým věcem a posouvat své schopnosti dál. Když zrovna nesedím u kódu, věnuji se fitness a počítačovým hrám.


… reposted this!
Myslím, že by bylo fér alespoň uvést originální zdroj: https://shnatsel.medium.com/the-state-of-simd-in-rust-in-2025-32c263e5f53d. Navíc tento článek mi v podstatě přijde jako chatbotem generovaný výtah…