Doctrine 2 – Optimalizace výkonu

V tomto článku si představíme způsob, kterým můžeme zvýšit výkon a snížit nároky webové aplikace využívající Doctrine 2 s minimálním zásahem do aplikace.
Nálepky:
Second Level Cache
Výkon aplikace je ovlivněný celou řadou různých faktorů (samotná implementace, počet a druh provedených dotazů do databáze, následná práce s daty apod.). Doctrine 2, která se stará o mapování dat z relačních databází do objektů v aplikaci (princip ORM), má na starost hned několik věcí, které jsou zodpovědné za celkový výkon aplikace. První z nich je porozumění tomu, která data po ní aplikace chce (např. data o produktu s ID=10). Doctrine musí znát způsob, kterým požadovaná data získá z databáze a následně musí vytvořit objekty, do kterých vloží získaná data.
Celý proces od získání dat po vytvoření a naplnění objektu je velmi náročný. Doctrine nejprve musí podle mapovacích metadat (PHP anotace, XML, YAML) porozumět databázovému schématu. Díky tomu dokáže vygenerovat validní a optimalizovaný SQL dotaz do relační databáze. Následně ze získaných dat dokáže vytvořit objekty a naplnit je daty (vyhydratovat).
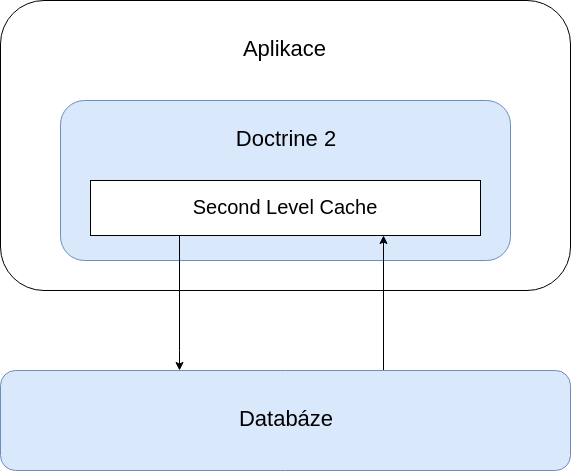
Co je Second Level Cache?
Second level cache spatřila světlo světa ve verzi Doctrine 2.5.0, která byla vydána v dubnu 2015. Jejím cílem bylo výrazně zvýšit výkon celé Doctrine ORM. Jak toho chtěla docílit? Postavila se mezi aplikaci a databázi a snížila počet prováděných dotazů na minimum.
Před položením SQL dotazu se Doctrine nejprve podívá do Second level cache, zda nemá potřebná data uložena zde. Pokud v cache nejsou, tak položí SQL dotaz do databáze a získaná data si uloží do cache (pro další hledání stejných dat). Pokud požadovaná data jsou nalezena v cache, tak jsou z ní načtena a dotaz do databáze se vůbec neprovede.
Nejsou data jako data
Data, která ukládáme do second level cache, dělíme do třech základních skupin.
1. Data entity
Entita reprezentuje nějaký objekt reálného světa. Například země má mj. svůj identifikátor, název, kód. Podle identifikátoru jsme schopni bezpečně určit, o kterou zemi se jedná.
Doctrine využije tohoto identifikátoru a uloží pod ním všechna ostatní data o entitě. Pokud poté chceme načíst zemi s ID=3, tak jsou všechna data načtena přímo ze Second level cache. Uložený identifikátor v Second level cache slouží také k aktualizaci a mazaní dat. Většina implementací cache by v případě aktualizace dat cache invalidovala. Second level cache zjistí, co se v entitě změnilo, a provede odpovídající aktualizace přímo v cache (stejně jako je provedla databáze). Proto může být následný požadavek pro načtení aktualizované entity opět plně obsloužen z cache.
Doctrine potřebuje znát entity, které má do Second level cache odkládat. Tuto informaci získá z anotace @ORM\Cache, kterou se označí cachovatelné entity.
<?php declare(strict_types=1);
namespace App\Model\Entity;
use Doctrine\ORM\Mapping as ORM;
/**
* @ORM\Entity
* @ORM\Cache
*/
class Country
{
/**
* @ORM\Id
* @ORM\GeneratedValue
* @ORM\Column(type="integer")
* @var int
*/
private $id;
/**
* @ORM\Column(type="string")
* @var string
*/
private $name;
/**
* @ORM\Column(type="string", unique=TRUE)
* @var string
*/
private $code;
// ...
}
2. Data kolekce
Kolekce je množina souvisejících entit (např. entita Country definuje množinu měst, která jsou v dané zemi). V řeči relačních databází by se jednalo o sloupec country_id obsahující cizí klíč z tabulky city do tabulky country. Přes tyto vazby jsme schopni bezpečně určit, o kterou zemi a město se jedná.
Second level cache dokáže tyto vazby ukládat také (podobně jako jsou uloženy v databázi). Do cache se uloží primární klíč navázané entity a její data jsou následně uložena do vlastního regionu. Pokud kolekci měníme (přidáváme nebo odebíráme položky), tak jsou tyto změny prováděny i na úrovní cache (po změně v databázi).
<?php declare(strict_types=1);
namespace App\Model\Entity;
use Doctrine\ORM\Mapping as ORM;
/**
* @ORM\Entity
* @ORM\Cache
*/
class Country
{
// ...
/**
* @ORM\OneToMany(targetEntity="City", mappedBy="country")
* @ORM\Cache
* @var City[]
*/
private $cities;
// ...
}
Pro správnou funkčnost musí být entita City také označena anotací @ORM\Cache.
3. Data z dotazů
Do Second level cache nemusíme ukládat pouze entity a vazby mezi nimi, ale máme možnost do ní odkládat i výsledky libovolných DQL dotazů.
Pokud bychom např. chtěli získat města začínající na písmeno „A“ v dané zemi, tak nám bude stačit vytvořit odpovídající DQL dotaz a Second level cache si poté výsledky z databáze uloží. S dalším požadavkem tak dojde k načtení identifikátorů měst z cache (nikoli z databáze) a následná hydratace entit (vytvoření objektů a jejich naplnění daty) je také plně obsloužena ze Second level cache (jsou v ní podle identifikátoru dohledána všechna potřebná data o městech).
<?php declare(strict_types=1);
namespace App\Model\Repository;
use App\Model\Entity\City;
use Doctrine\ORM\EntityManager;
class CountryRepository
{
/**
* @var EntityManager
*/
private $entityManager;
public function __construct(EntityManager $entityManager)
{
$this->entityManager = $entityManager;
}
/**
* @return City[]
*/
public function getCitiesStartingWith(string $startWith, int $countryId): array
{
$query = $this->entityManager->createQuery('
SELECT c
FROM App\Model\Entity\Country c
...
');
return $query->setCacheable(TRUE) // use Second Level Cache for query
->getResult();
}
}
Regiony
Doctrine do Second level cache neukládá instance entit, ale identifikátor a jednotlivé hodnoty, které dostane z databáze. Aby se z cache nestalo jedno obrovské úložiště, které bude problematické invalidovat, tak vznikly oddělené regiony. Region si lze jednoduše představit jako složku, do které dáváme související data. Pro různá data máme různé složky (regiony) např. produktový region (obsahující produkty, ceny a statistiky prodeje), zákaznický region (obsahující zákazníky, adresy) apod.
/**
* @ORM\Entity
* @ORM\Cache(region="my_product_region")
*/
class Product
{
// ...
}
/**
* @ORM\Entity
* @ORM\Cache(region="my_category_region")
*/
class Category
{
// ...
}
Jednotlivé regiony mají v cache různé jmenné oddíly (namespace) a mohou mít různou expiraci (dobu platnosti záznamů = lifetime). Doctrine umožňuje ruční invalidaci určitého regionu, kdy dojde k zneplatnění všech dat, která jsou v daném regionu uložena, ale všechny ostatní regiony v cache zůstanou naplněné a platné.
V případě ukládání kolekcí jsou data entit ukládána do svých regionů (podle definice v entitě).
Tři způsoby využití cache
Second level cache definuje tři různé způsoby, kterými jsou data do cache ukládána.
1. READ_ONLY
Jedná se o výchozí způsob cachování, který je nejrychlejší a nejjednodušší ze všech tří způsobů. Tento způsob se perfektně hodí pro velmi často získávaná data, která se nikdy nemění. Jak napovídá název, tak v tomto způsobu (módu) není možné provádět jakoukoli editaci a mazání dat. Při pokusu o úpravu nebo smazání dat z entity, která je cachována v módu READ_ONLY, dojde k vyhození výjimky.
/**
* @ORM\Entity
* @ORM\Cache(usage="READ_ONLY", region="country_region")
*/
class Country
{
// ...
}
2. NONSTRICT_READ_WRITE
Tento způsob umožňuje čtení, vkládání, editaci i mazání dat. Kvůli tomu, že Second level cache musí hlídat změny v datech, tak v tomto módu dochází k určitému zpomalení. Cachování přes způsob NONSTRICT_READ_WRITE se hodí pro data, která jsou čtena často, ale přitom může občas dojít k jejich změnám. Přístup k datům není omezen žádným zámkem.
/**
* @ORM\Entity
* @ORM\Cache(usage="NONSTRICT_READ_WRITE", region="comment_region")
*/
class Comment
{
// ...
}
3. READ_WRITE
Poslední způsob práce s cache umožňuje stejné možnosti jako předchozí způsob (NONSTRICT_READ_WRITE), ale vytváří zámek před editací a smazáním dat. Tato strategie je nejpomalejší ze všech tří způsobů a hodí se pro data, která musí být aktualizována.
/**
* @ORM\Entity
* @ORM\Cache(usage="READ_WRITE", region="customer_region")
*/
class Customer
{
// ...
}
Závěr
Díky Second level cache může naše aplikace drasticky snížit počet komunikací s databází. Nastavení a použití je velmi snadné a rychlé. Data jsou do cache ukládaná v logických skupinách (regionech), které můžeme libovolně invalidovat. Second level cache neukládá instance entit, ale pouze identifikátor a odpovídající data. Díky tomu dokáže i cache aktualizovat změněné hodnoty a nemusí “hloupě” invalidovat všechna uložená data a načítat si je znovu z databáze. Navíc si sami můžeme rozhodnout, jakým způsobem bude Second level cache zacházet s ukládanými daty, a tím ovlivnit výkon cache.
Chceš se dozvědět více?
Aktuální dokumentace Second level cache vysvětluje problematiku ještě více do hloubky. Na školení “Doctrine 2 – Pokročilé použití” probírám Second level cache spolu s dalšími způsoby optimalizace a celou řadou dalších věcí na reálných příkladech, tak přijď! Pokud chceš Doctrine používat každý den v práci, tak přijď do našeho skvělého IT týmu a posouvej dál první internetovou lékárnu Lekarna.cz spolu s námi.
Tomáš Pilař
Mojí velikou vášní je programování v PHP s využitím všech moderních nástrojů. Zajímám se primárně o dění okolo programátorské komunity, také sleduji dění kolem Nette, Symfony, Doctrine a Elasticsearch.


Ahoj Tome, díky za přehledný článek. Ten graf se mi moc líbí! :)
Mám 2 otázky do praxe:
1) Jak moc dlouho ti trvalo to všechno nasát a zjistit, abys to mohl použít v praxi? Zajímá mě hodinová zátěž úkolu „přidat Doctrine 2nd level cache“ pro někoho, kdo zná Doctrine, ale čte o 2nd level cache poprvé.
2) Jak velké je zrychlení např. na přehledu produktů, relativně i absolutně a při jakém počtu produktů (a další elementů, které tam jsou a mají roli a teď mě nenapadli).
Propaguji 2nd level cache ve firmách, kde Doctrine používají, ale chybí mi reálná čísla k přesvědčení :)
Ahoj Tome, titulek „Očekávání vs. Realita“ je skvělý! :)
Ad 1) Cesta od objevení SLC k jejímu použití je kratší než by se mohlo zdát. Když se ti nechce číst dokumentace, tak to jsou vlastně pouze dva kroky:
setSecondLevelCacheEnabled()a poté stačí předat cache továrna přessetCacheFactory()viz. https://www.doctrine-project.org/projects/doctrine-orm/en/2.6/reference/second-level-cache.html#enable-second-level-cache.@ORM\Cachedo entity, která se má odkládat do SLC.Jak vidíš, tak je to práce na 5-10 minut? :) Samozřejmě, že čím více začneš využívat SLC (i pro kolekce), tak se už dokumentaci nevyhneš. Když pak narazíš na nějaký edgecase, tak musíš projít i samotné zdrojové kódy a pak toho načerpáš daleko více. Stačí se nebát a nahlédnout pod pokličku. ;) Z mého pohledu je zátěž na základní implementaci skoro nulová.
Ad 2) Zrychlení aplikace je velmi relativní. SLC totiž není zázračná skřínka, kterou zapneš a ona ti zrychlí aplikaci o 50%. Je to nástroj pro snížení počtu dotazů do databáze. Pokud máš tedy navštěvovanou aplikaci (řádově stovky lidí online) a podaří se ti ušetřit jeden sql dotaz, který se provede každému zákazníkovi na každé stránce (např. zjištění lokalizace podle domény), tak díky tomu ušetříš statisíce provedených SQL dotazů za den. Cílem je tedy snížit zatížení databáze.
Ze zkušenosti ti mohu říci, že když dáš do SLC všechny entity v aplikaci, tak do databáze nepůjde opravdu žádný dotaz. Je potřeba, ale myslet na to, že data musí být z nějakého zdroje načteny. Pokud se ti předtím provádělo třeba 100 requestů do DB, tak se SLC se ti bude provádět 100 requestů do cache (např. Redisu). Když si toto uvědomíš, tak zjistíš, že před využitím SLC je dobré se zaměřit na snížení počtu dotazů do databáze (např. přes manuální hydrataci kolekcí viz. https://ocramius.github.io/blog/doctrine-orm-optimization-hydration/). Když se ti povede snížit počet dotazů do databáze a pak nasadíš SLC, tak je to win-win situace. :)
O tom jaké jsou možnosti snížení počtu dotazů do DB bych mohl připravit navazující článek. Každopádně to také probíráme na demo aplikaci na školení. ;)
Přesná čísla o tom, jak pomohla SLC u nás na lekarna.cz ti bohužel říci nemůžu, protože si je už nepamatuju. :D Novou verzi lékárny jsme spouštěli před rokem a tyto optimalizace se dělali ještě před spuštěním. Co si, ale pamatuji tak to bylo řádově desítky procent ušetřených dotazů. Ne všechny entity můžeš na e-shopu držet v cache.
Abych ti dal nějaká skutečná čísla, tak ti mohu říci, že na jednom připravovaném projektu se počet dotazů vyvíjel takto:
Suma sumárum je to snížení počtu dotazů do databáze na jeden request o ~91% a to je pěkné číslo.
Snad jsem ti vše srozumitelně vysvětlil. :)
Za redakci dodávám, že navazující článek rozhodně vítáme a oceníme. 👍